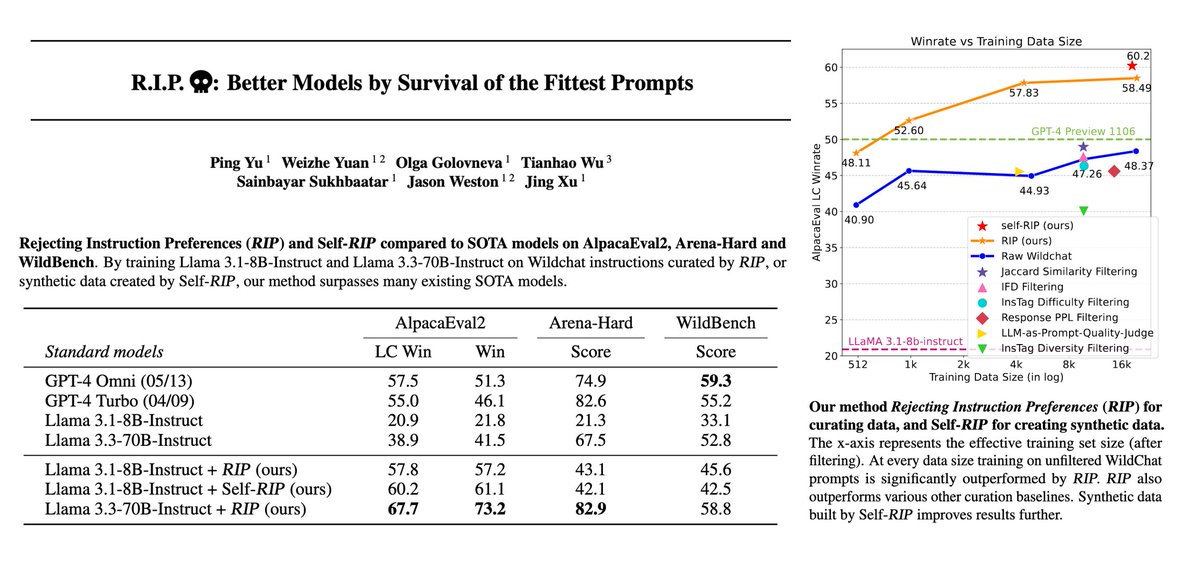
💀 Introducing RIP: Rejecting Instruction Preferences💀
A method to *curate* high quality data, or *create* high quality synthetic data.
Large performance gains across benchmarks (AlpacaEval2, Arena-Hard, WildBench).
Paper 📄: https://t.co/9EKFpTsd9e
I saw a slide circulating on social media last night while working on a deadline. I didn’t comment immediately because I wanted to understand the full context before speaking. After learning more, I feel compelled to address what I witnessed during an invited talk at NeurIPS 2024 by Professor Rosalind Picard.
I deeply respect Professor Picard’s scholarship and contributions to the field. However, her comments during the talk reflected a deeply troubling and racist view of Chinese scholars. This was not just inappropriate but also profoundly disheartening.
First, it was entirely unnecessary to mention the student’s nationality when discussing an incident of cheating. The point about academic integrity could have been made without emphasizing nationality. Yet, Professor Picard chose to highlight it. This choice perpetuates harmful stereotypes about Chinese scholars and reflects a broader bias against Asians, often rooted in the assumption that we “work hard, avoid conflict, and don’t push back.”
This needs to change. Asians, like everyone else, have the right to speak out and demand accountability when racism occurs. We will ensure that being racist against Asians has consequences, including here, Professor Picard.
What made this incident worse was how it unfolded during the Q&A session. A Chinese attendee asked a professional and thoughtfully articulated question. She began by thanking Professor Picard for her talk and posed this question:
Are you calling out the student’s nationality because you find most Chinese scholars honest, and the fact that the cheating student was Chinese is rare? Is that why you emphasized nationality?
This was a generous and high-EQ question, offering Professor Picard an opportunity to reconsider or clarify her comments. Unfortunately, she doubled down instead.
Professor Picard reinforced her remarks by quoting the student’s excuse —that ethics wasn’t taught in their school—and generalized this as a broader issue with Chinese education. This statement is both factually incorrect and deeply offensive.
There are glaring logical flaws in this argument:
1.If the student cheated, why would their excuse about ethics education be taken at face value? A serious scholar would investigate the claim before making it a central part of their argument.
2.Even if the student’s school didn’t teach ethics (which is false for schools in China), other sources like family and community often instill strong ethical values. Ignoring this nuance is careless and reinforces stereotypes.
What is most heartbreaking is that Professor Picard couldn’t even acknowledge something as simple as: “Most Chinese scholars are honest and upright.” Instead, she focused on the singular exception and added, “Of course, with this one exception in this case” in her response.
I regret that this happened at NeurIPS. I regret that this happened in my research community—a place I have cherished and contributed to for over 14 years. I regret that this happened at MIT, an institution of excellence and aspiration for many Chinese scholars.
Racism has no place in academia, and incidents like this tarnish the principles of inclusion and respect that we, as a global research community, should uphold.
I hope NeurIPS and the broader academic community take this as a wake-up call to address the biases and systemic issues that enable such comments to go unchallenged. We must do better.
@MIT_CSAIL@NeurIPSConf
🚨 Distilling System 2 into System 1🚨
- System 2 LLMs spend compute to improve responses (CoT, BSM, RaR, Sys 2 Attention, ..)
- *System 2 distillation* keeps this improvement but distills it back into the base LLM (System 1) outputs
https://t.co/JQ1tb8t2h9
🧵(1/5)
📚 New research from Meta AI — Shepherd is a language model specifically tuned to critique model responses & suggest refinements. It goes beyond the capabilities of untuned models to identify diverse errors & suggest improvements.
Read the paper ➡️ https://t.co/BtrTV0YEun
🚨New Paper 🚨
Self-Alignment with Instruction Backtranslation
- New method auto-labels web text with instructions & curates high quality ones for FTing
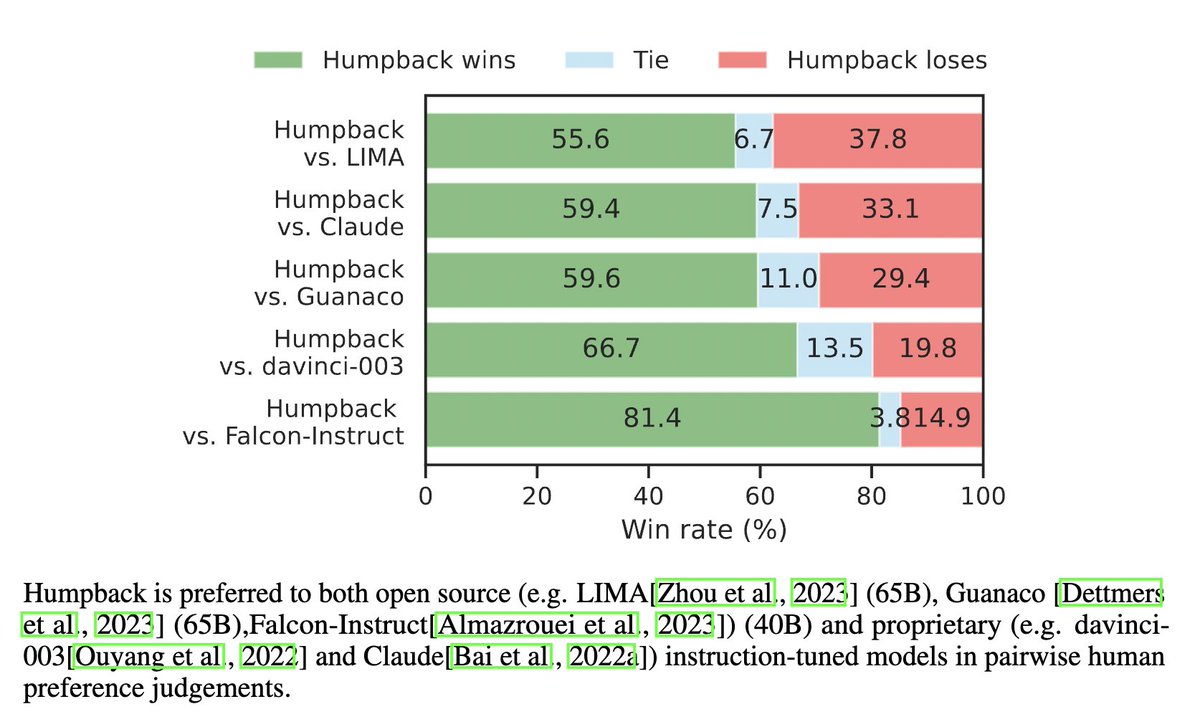
- Our model Humpback 🐋 outperforms LIMA, Claude, Guanaco, davinci-003 & Falcon-Inst
https://t.co/93qi4JDnpb
(1/4)🧵
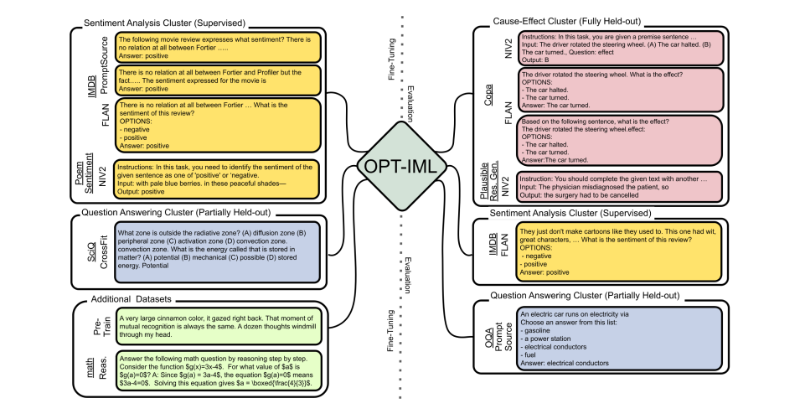
Announcing OPT-IML: a new language model from Meta AI with 175B parameters, fine-tuned on 2,000 language tasks — openly available soon under a noncommercial license for research use cases.
Research paper & more details on GitHub ⬇️
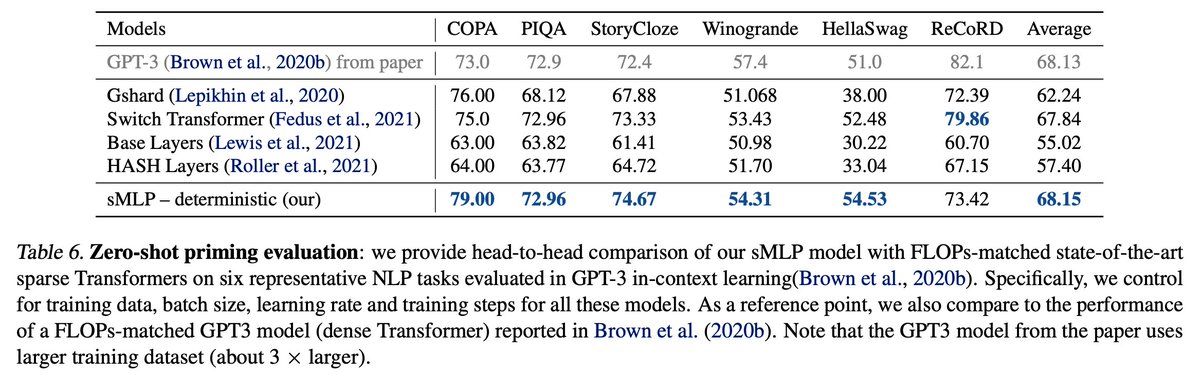
Zero-shot priming evaluation: we provide a head-to-head comparison on six representative NLP tasks. As a reference point, we list the performance of a FLOPs-matched GPT3 model reported in the paper, although the GPT3 model uses a larger training dataset (about 3 × larger).
Excited to share our new work "Efficient Language Modeling with Sparse all-MLP".
Sparse all-MLP (sMLP) improves LM PPL and obtains up to 2x improvement in training efficiency compared to Transformer-based MoEs as well as dense Transformers and all-MLPs.
https://t.co/8o6VIs1ZYN
Head-to-head comparison measures per step and per time benefits of the sMLP (our model) over baselines. We report perplexity (lower better) and time to reach (lower better) as quality and training efficiency measures. All models are trained with the same amount of computation.