The problem with the "if it works who cares what the code looks like" mindset for agentic work is that it assumes the agent has a perfect understanding of "works." Realistically, things are underspecified, agents make bad assumptions, etc.
To be fair, agents are pretty good at unit test coverage. They're pretty bad at designing human experiences (API, CLI flags, etc.), especially cohesive ones for future roadmap plans they may not have visibility into (unless your backlog is perfect and vision fully laid out, which I doubt). They're bad at knowing where performance matters and what type (CPU vs memory tradeoffs). They're bad at where compatibility matters and where it doesn't (and tend to err on the side of preserving it without further guidance). Etc.
Unless you have this ALL specified, you can't possibly claim "it works" without taking a look and thinking about it.
@MatthewBerman /goal refactor until you are happy with the architecture. ensure you live test after each significant step and autoreview/commit. track progress in /tmp/refactor-{projectname}.md
When I struggle to structure my thoughts about what's happening I turn to writing. Today about the recent US Anthropic ban news, what it says about power and dependency, and what it should mean for Europeans and citizens of the world. It's a long one. https://t.co/6dpw0QOQeO
When I struggle to structure my thoughts about what's happening I turn to writing. Today about the recent US Anthropic ban news, what it says about power and dependency, and what it should mean for Europeans and citizens of the world. It's a long one. https://t.co/6dpw0QOQeO
While Fable is an amazing model, don't get too excited: it is great, but still has the usual failure models of the other good LLMs we saw in the past, including GPT 5.5. If you look at Anthropic, Opus -> Fable was a huge jump. If you look at the field, GPT 5.5 -> Fable is incremental.
Every engineer should read this.
The principles for building reliable software systems have been around for a long time. Max outlines them beautifully.
Here's to getting that 99.99% on your status page.
https://t.co/HFDcriLodl
UPDATE: Came up with an even better version of this prompt after the feedback
Ask Codex to look across your sessions, Memories, and Chronicle, identify patterns, reuse what already exists, and only create the smallest useful skill, subagent, or automation.
"Look back over my recent work from the last 30 days, or all available history if shorter, and identify repeated manual workflows worth packaging.
Use available evidence in this order:
- Recent Codex sessions and task summaries.
- Codex Memories and rollout summaries to find patterns repeated across sessions.
- Chronicle, if enabled, to spot repeated work outside Codex. Use Chronicle for discovery only; confirm important details in the relevant source system when possible.
- Existing skills, custom agents, and automations, so you reuse or extend what already exists instead of duplicating it.
Look broadly for work that is repeated, time-consuming, error-prone, context-heavy, or benefits from a consistent process. Include workflows across coding, research, writing, planning, communication, operations, analysis, and personal administration.
Only act on a candidate when it:
- occurred at least twice, or is clearly likely to recur and costly to repeat;
- has stable inputs, a repeatable procedure, and a clear output or stopping condition;
- would materially improve speed, quality, consistency, or reliability;
- is not already adequately covered.
Choose the smallest appropriate form:
- Skill: a reusable workflow or playbook.
- Custom subagent: a bounded specialist role or investigation task suitable for delegation.
- Automation: a scheduled or recurring check, report, reminder, or monitor.
- Skip: work that is too one-off, ambiguous, sensitive, or poorly evidenced to package.
First produce a compact shortlist with:
- repeated workflow
- supporting evidence and dates
- frequency/confidence
- recommended form: skill, subagent, automation, extend existing, or skip
- why it is or is not worth creating
Then create only the high-confidence missing items. Keep them narrow, practical, source-aware, and easy to validate. Do not create speculative, overlapping, or overly broad assets.
Finish with:
- what you created or extended
- what you deliberately skipped
- what needs more evidence before packaging"
Has been a while since I wrote about agentic engineering, so this time around some learnings of maintaining Pi as a junior maintainer to @badlogicgames :) https://t.co/TbD9Jvqk3t
OpenAI have secretly adjusted our limits.
Last week before limit reset. I was using Xhigh all day.
5 day straight i couldn’t get my usage below 55% weekly usage.
Since Yesterday, I’ve done 40% of my quota, out of nowhere.
So whats going on ?
@thsottiaux@sama@OpenAIDevs
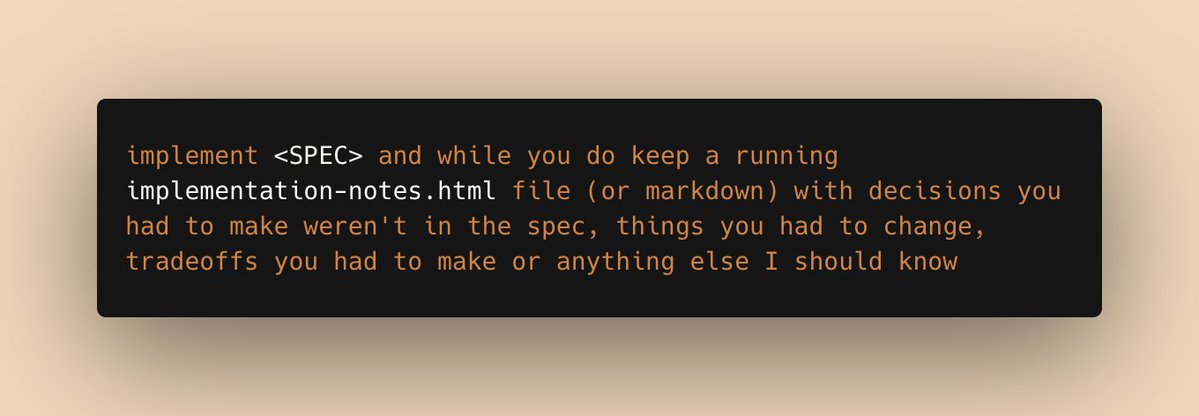
a prompt I've been using a lot recently:
implement <SPEC> and while you do, keep a running implementation-notes.html file (or markdown) with decisions you had to make weren't in the spec, things you had to change, tradeoffs you had to make or anything else I should know
@EdenKollcinaku@GoogleDeepMind@GoogleAI In my opinion, this kind of sharing is just a waste of everyone's time and energy. There is no basis for it, just mindless flattery.
I believe you should block this kind of person as soon as you encounter them, because they are simply exploiting everyone's trust.