We found OpenAI's GPT-5 endpoint and made it accessible in our app. You can use GPT-5 literally for free! Its the smartest model I have ever used so far
Models like o3-mini and o3 and easily be outperformed by letting cheaper and faster models like QwQ 32b Instruct answer prompts iteratively. https://t.co/pZHL4mdd3u
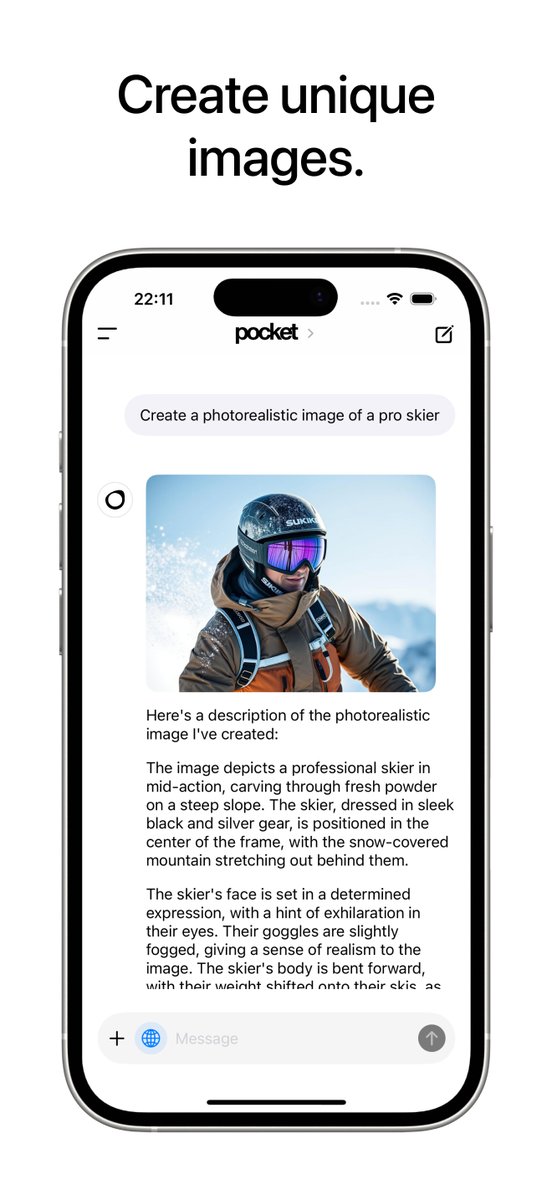
Today I am are introducing the voice mode with video input to the pocket app. The video input works offline and online. If you choose to use it offline it will be using Qwen2.5 VL. https://t.co/KBfxBDrgYA
Congrats to all #SwiftStudentChallenge winners and applicants! It's such a privilege to have the opportunity to experience dub dub live as a 15 year old. My app playground is an app for deafblind individuals. The app translate text to morse code to haptic feedback.
running ai locally becomes more and more crucial. I believe ai should be distributed and decentralized among its users.
thats what pocket ai is for. run model like llama locally on your device. anytime, anywhere.
#privatellm#llm#ai#artifical#ArtificialInteligence
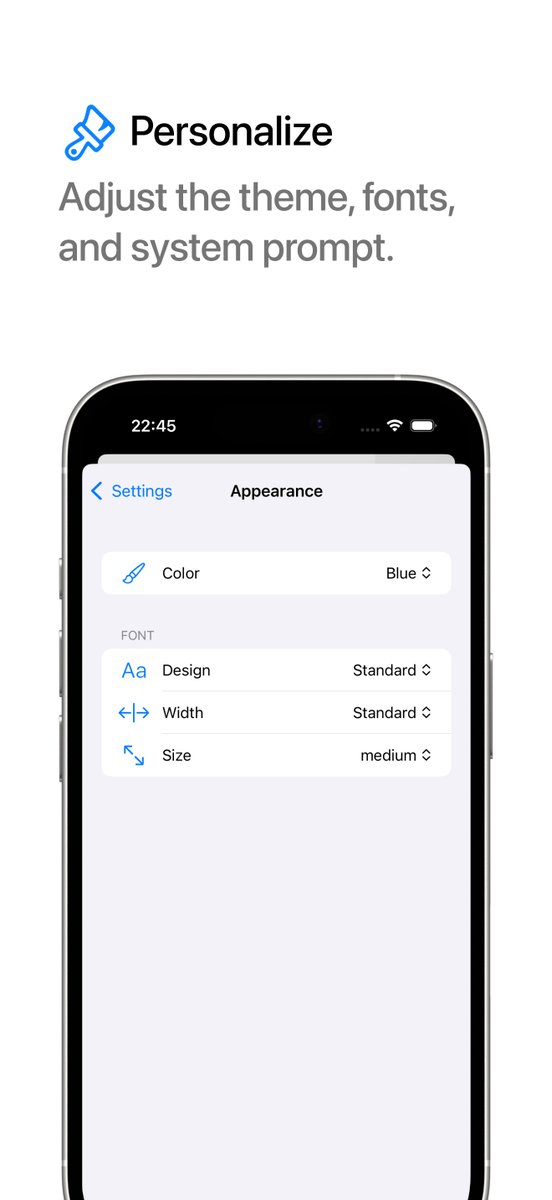
I’m excited to introduce Pocket — the app that brings powerful AI to your iPhone, entirely offline. With Pocket, you can run advanced AI models on your device, keeping your data private and secure.
https://t.co/KBfxBDrgYA
i added the new chat @pocketllm shortcut to my action button for quick llm queries.
this feels more helpful than apple intelligence and always runs local.
https://t.co/KBfxBDrgYA
PDFMathTranslate
PDF scientific paper translation and bilingual comparison.
📊 Preserve formulas, charts, table of contents, and annotations (preview).
🌐 Support multiple languages, and diverse translation services.
🤖 Provides commandline tool, interactive user interface, and Docker
Process Reinforcement through Implicit Rewards
We present PRIME (Process Reinforcement through IMplicit REwards), an open-source solution for online RL with process rewards, to advance reasoning abilities of language models beyond imitation or distillation.
With PRIME, starting from Qwen2.5-Math-7B-Base, our trained model Eurus-2-7B-PRIME achieves 26.7% pass@1, surpassing GPT-4o and Qwen2.5-Math-7B-Instruct. We achieve this with only 1/10 data of Qwen Math (230K SFT + 150K RL).
We’re kicking off 2025 with everything we've got! 🤩
Introducing CodeGPT's Knowledge Graphs, navigating through the entire Anthropic SDK repository.
In this example, we loaded @AnthropicAI Python SDK repository and successfully provided the LLM with all the knowledge it needs to fully understand the codebase.
You can leverage these knowledge graphs using the CodeGPT extension in VSCode by simply calling the @codebase command 👏
Stay tuned for more tutorials on how to use this powerful tool!
Happy 2025! 🎉
Thank @_akhaliq for sharing our work! Up to 16x less inference steps and 9.5x actual speedup for autoregressive visual generation. Our code and models are released at https://t.co/C6DUB1MixX.
Project page: https://t.co/lyHZRivDGe
Paper: https://t.co/Ywy4wQO9WQ
Great read - "Understanding LLMs: A Comprehensive Overview from Training to Inference"
The journey from self-attention mechanism to the final LLMs.
This paper reviews the evolution of large language model training techniques and inference deployment technologies.
--------
→ The evolution of LLMs and current training paradigm
Training approaches have evolved from supervised learning to pre-training and fine-tuning, now focusing on cost-efficient deployment. Current focus is on achieving high performance through minimal computational resources.
→ Core architectural components enabling LLMs' success
The Transformer architecture with its self-attention mechanism forms the backbone. Key elements include encoder-decoder or decoder-only designs, enabling parallel processing and handling long-range dependencies.
→ Key challenges in training and deployment
Main challenges include massive computational requirements, extensive data preparation needs, and hardware limitations. Solutions involve parallel training strategies and memory optimization techniques.
→ The role of data and preprocessing in LLM development
High-quality data curation and preprocessing are crucial. Steps include filtering low-quality content, deduplication, privacy protection, and bias mitigation.
🔍 Critical Analysis & Key Points:
→ Data preparation strategies drive model quality
Processing raw data through sophisticated filtering, deduplication and cleaning pipelines directly impacts model performance.
→ Parallel training techniques enable massive scale
Using data parallelism, model parallelism and pipeline parallelism allows training billion-parameter models efficiently.
→ Memory optimization is crucial for inference
Techniques like quantization, pruning and knowledge distillation help deploy large models with limited resources.
The time complexity of 10 popular ML algorithms.
Understanding the run time of ML algorithms is important because it helps us:
- Build a core understanding of an algorithm.
- Understand the data-specific conditions that allow us to use an algorithm.
For instance, using SVM or t-SNE on large datasets is infeasible because of their polynomial relation with data size.
Similarly, using OLS on a high-dimensional dataset makes no sense because its run-time grows cubically with total features.
--
Join 100k+ data scientists and get a Free data science PDF (550+ pages) with 320+ posts by subscribing to my daily newsletter: https://t.co/M3Rh9zEEde
--
Over to you: Can you tell the inference run-time of KMeans Clustering?
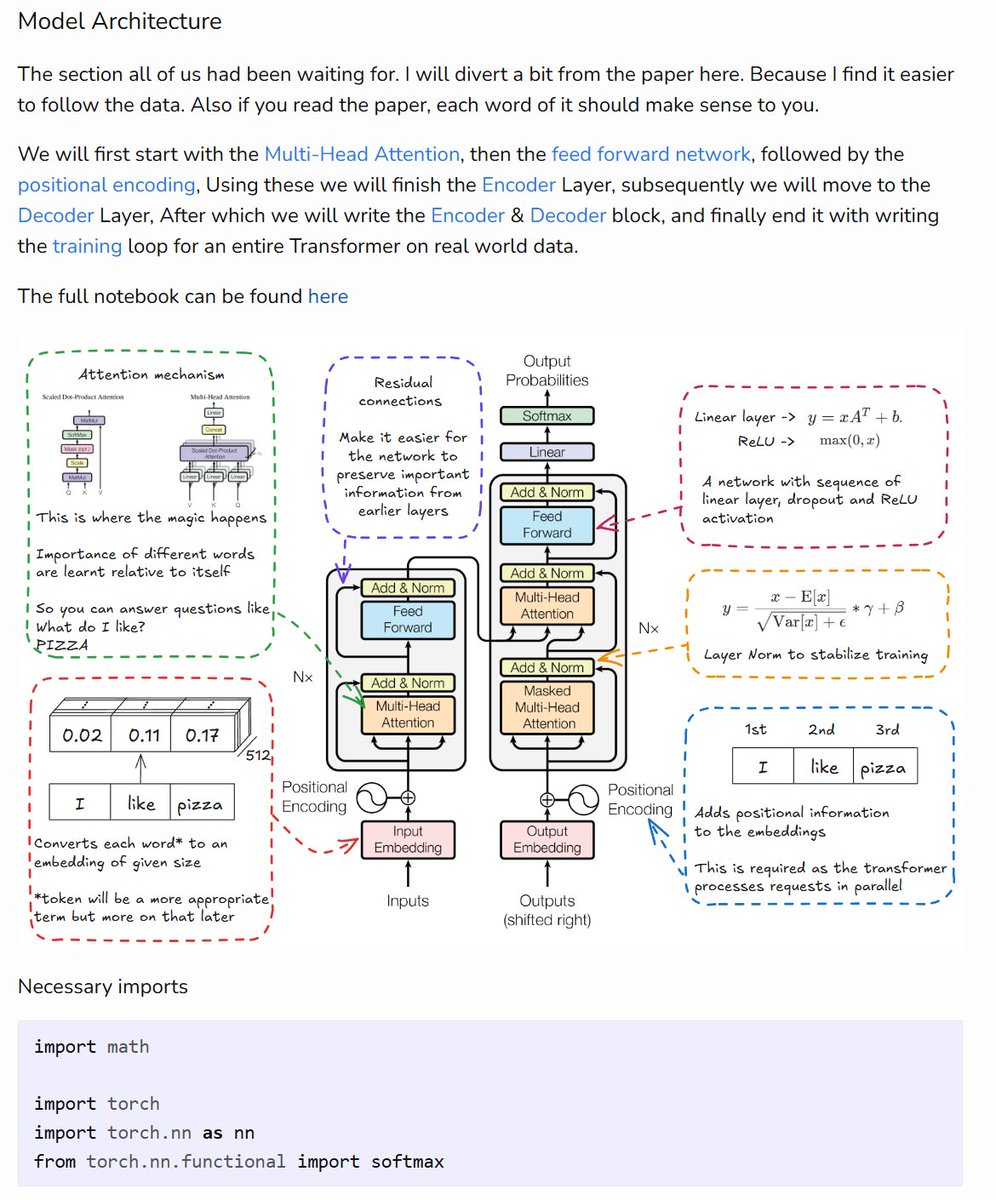
I am finally done with the blog on transformers.
I have tried to incorporate everything someone would need to deeply grok it.
* Code
* Paper lingo
* Visual explanation of components
Consider checking it out