This Tuesday at The AI Engineer World’s Fair in SF @aiDotEngineer, our co-founder & CEO @arimorcos takes the Data Quality stage for the keynote.
"Data Quality is the Compute Multiplier": why better quality training data drives a better model with the same compute.
Tue 6/30, 10:45 am, Room 2016.
New research! ÜberWeb: multilingual data curation across 13 languages and 20 trillion tokens.
The "curse of multilinguality" is largely a data quality problem, and it's fixable.
tl;dr: we get 4-10x training efficiency improvements over models like Qwen3 and Tiny Aya
🆕 pod: Better Data is All You Need
https://t.co/acv2vxZseS
A brief history of open LLM data corpuses:
C4 ->
Redpajama ->
RefinedWeb ->
FineWeb ->
DCLM ->
BetterWeb
@arimorcos of @datologyai drops by to tell us about their automated Data Curation work, beating the DCLM baseline by 12x! also ft. 2025 updates on the state of Synthetic Data and the Return of Curriculum Learning!
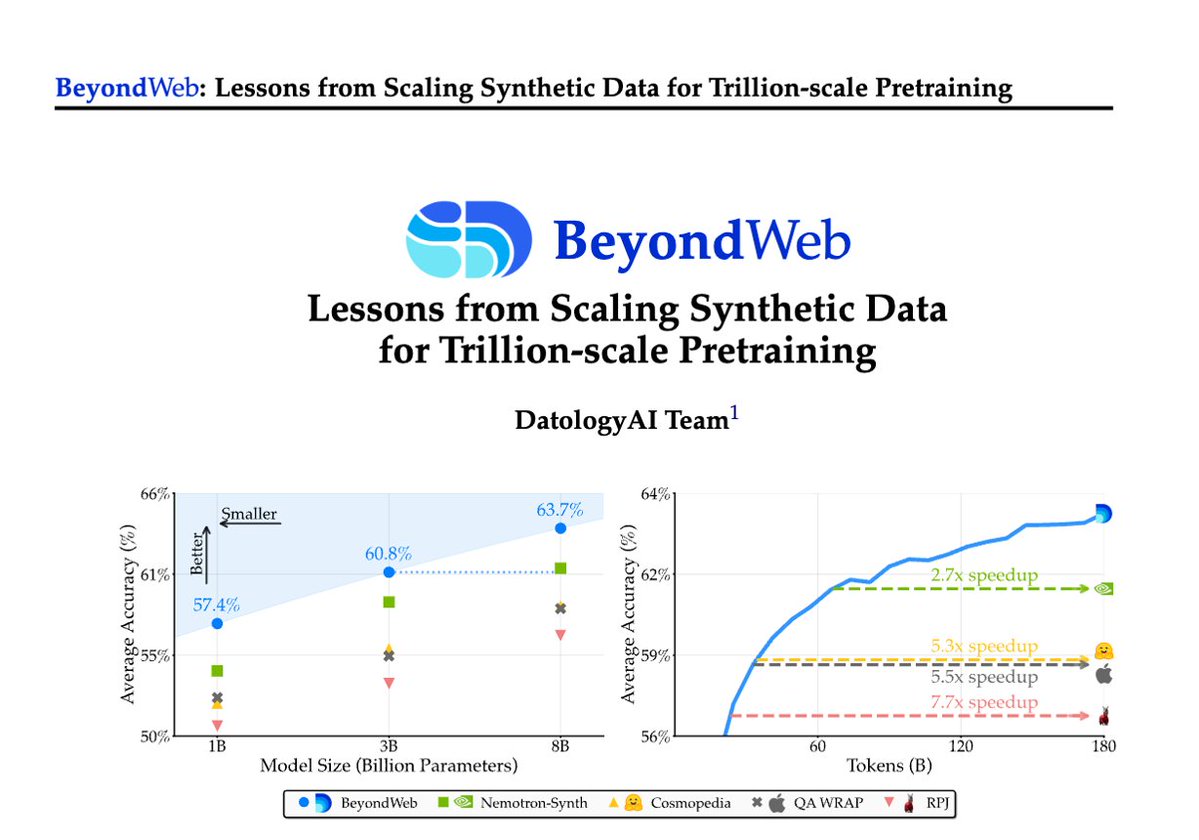
1/Pretraining is hitting a data wall; scaling raw web data alone leads to diminishing returns. Today @datologyai shares BeyondWeb, our synthetic data approach & all the learnings from scaling it to trillions of tokens🧑🏼🍳
- 3B LLMs beat 8B models🚀
- Pareto frontier for performance
BeyondWeb: Lessons from Scaling Synthetic Data for Trillion-scale Pretraining
"we introduce BeyondWeb, a synthetic data generation framework that produces high-quality synthetic data for pretraining. BeyondWeb significantly extends the capabilities of traditional web-scale datasets, outperforming state-of-the-art synthetic pretraining datasets such as Cosmopedia and Nemotron-CC's high-quality synthetic subset (Nemotron-Synth) by up to 5.1 percentage points (pp) and 2.6pp, respectively, when averaged across a suite of 14 benchmark evaluations. It delivers up to 7.7x faster training than open web data and 2.7x faster than Nemotron-Synth. Remarkably, a 3B model trained for 180B tokens on BeyondWeb outperforms an 8B model trained for the same token budget on Cosmopedia."
Congratulations to our friends and partners @arcee_ai on the release of AFM-4.5B!
With data powered by @datologyai, this model outperforms Gemma3-4B and is competitive with Qwen3-4B despite being trained on a fraction of the data.
We've definitely seen signs of this already — perhaps not surprisingly, post-training people tend to care more about the value of data.
We see a number of companies turning to @datologyai for getting the most out of their existing datasets!
We've improved our image-text curation significantly from our last blog post, now beating SigLIP2 through *data interventions alone* using vanilla CLIP.
So proud of @RicardoMonti9, @HaoliYin, @leavittron and the rest of the team! Check out the thread for all the details 👇
Hey folks! I'll be at the Snowflake Summit on June 2-5 and Databricks Data + AI Summit on June 9–12, so if anyone else is in SF during that time and want to catch-up over lunch or coffee, please reach out!
Definitely a paradigm shift we're still learning to navigate intelligently as an industry. Knowing when and how to use AI tools effectively is becoming essential.
🧵We’ve spent the last few months at @datologyai building a state-of-the-art data curation pipeline and I’m SO excited to share our first results: we curated image-text pretraining data and massively improved CLIP model quality, training speed, and inference efficiency 🔥🔥🔥
After like a month of chasing why my wifi is breaking down periodically it turns out that it's caused some weird bug in WiFi calling on iPhones that is causing the network to be flooded by ESP UDP packets (to the point in which it was doing 500Mbit+ of this)