"you can't have superuser"
"you can't install that extension"
"you can't access WAL"
"it's for your protection!"
no.
it's free software -- handed back to you with the freedom removed, and the cage painted as safety
Postgres is free.
that freedom is the whole point.
you don't need protection from the database you've run for decades.
you need access to it. full control. and ownership.
PgQue v0.2.0:
🐍 Python, 🟦 TypeScript, 🐹 Go clients
⚡️ send_batch() performance optimized
👥 subconsumers to scale consumption near-linearly
⏱️ sub-second ticking and 10 ticks/sec by default (incl. with pg_cron)
🧩 pg_cron, pg_timetable, pg_tle paths
PgQue is a highly-efficient, zero-bloat Postgres queue built on top of on battle-proven Skype's PgQ. One SQL file to install, pg_cron to tick. Works in any Postgres.
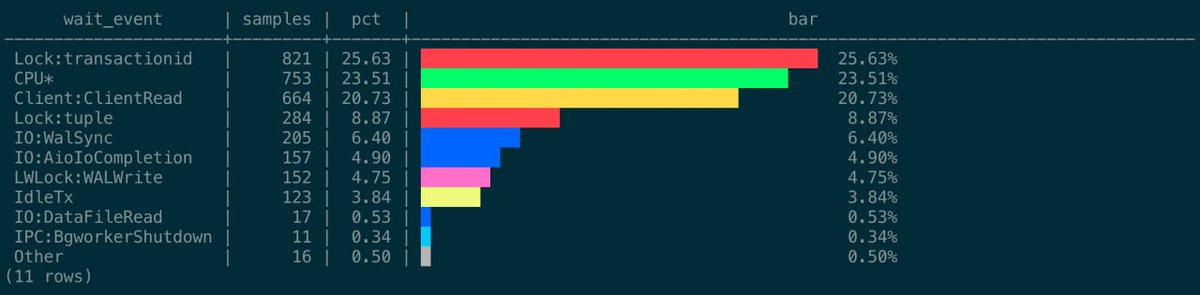
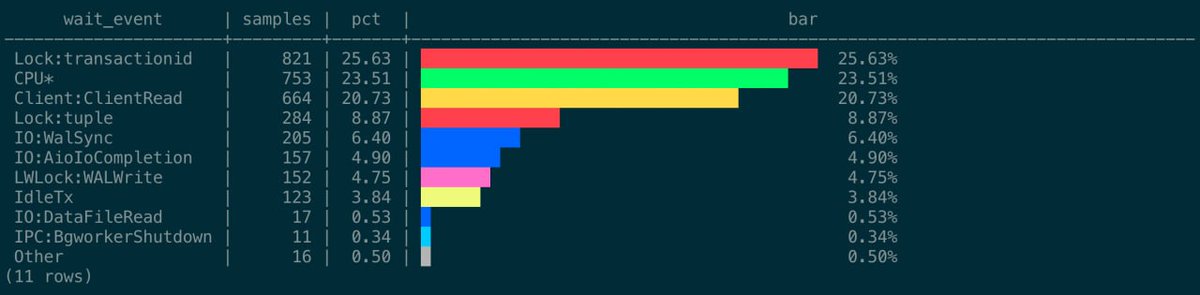
pg_ash v1.4 is out
• Long-term rollups: 1-minute and 1-hour rollup tables for longer storage
• Configurable raw partitions: by default, 3 daily partitions, can be any number
• Safer destructive operations: explicit confirmations needed
• Hardened privileges: public access is restricted; guarded search paths; "ash.grant_reader('youruser');"
• Stronger release gate: CI covers PostgreSQL 14–18, pg_cron and no-pg_cron modes, e2e tests, etc.
pg_ash is Active Session History (ASH) implemented in pure SQL/PLpgSQL — no C extension build, no restart, no shared_preload_libraries. Works in any Postgres.
Ask your AI agent to inject it "\i sql/ash-install.sql" and then analyze workload using functions – your AI will figure it out easily.
Upcoming PgQue 0.2 introduces subconsumers (PgQ's "cooperative consumers", reimplemented due to license uncertainty) -- this is how you can scale consumption almost linearly
PgQue is a very efficient, zero-bloat Postgres queue. One SQL file to install, pg_cron or pg_timetable to tick. Works everywhere.
PgQue v0.1.0 is out.
PgQ -- the Postgres queue system built at Skype 20 years ago for 1B-user-scale workloads -- repackaged for the managed-Postgres era. One SQL file. No C extension. No external daemon. pg_cron to tick.
Why bother reviving a 2007 architecture?
Every major Postgres queue in production today uses some flavor of SKIP LOCKED + UPDATE/DELETE. It works under light load. When you have more data and higher load, it degrades predictably. Then you get posts like these:
- Brandur at Heroku, 2015: 60k job backlog in one hour from a single open transaction
- PlanetScale, 2026: death spiral at 800 jobs/sec
- River issue #59, awa issue #169 and so on, Oban's partitioning work, PGMQ's autovacuum tuning guide and duct-taping with pg_partman
The core issue is how Postgres MVCC is implemented and how we deal with it. Dead tuples in the hot path, xmin horizon pinned, vacuum falling behind, query performance quickly degrades. This happens every time you run pg_dump, execute an analytical query, or have a lagging/unused logical replication slot.
PgQ solved this in 2007 with snapshot-based batching and TRUNCATE rotation -- zero dead tuples in the event
path, by design.
But PgQ needed a C extension and an external daemon. Which means it doesn't run on RDS, Aurora, Cloud SQL, AlloyDB, Supabase, or Neon -- i.e., where most
Postgres lives now.
PgQue closes that gap.
💎 Pure SQL + PL/pgSQL (PgQ engine)
👩💻 \i sql/pgque.sql -- you're done
🕑 pg_cron replaces pgqd (optional, recommended)
💻 Python, Go, TypeScript client examples shipped
💙 Apache 2.0
Trade-off: end-to-end event delivery latency is up to a second, it depends on ticking frequency. If you need sub-3ms job dispatch, use River, Oban, or graphile-worker (and avoid anything that blocks xmin horizon). If you need high-throughput event streaming with fan-out inside Postgres -- Kafka-shaped, without Kafka and dealing with transactional outbox implementation -- this is the right shape of tool.
Kudos to Marko Kreen and Skype engineers who implemented this decades ago, for the original PgQ, and to Alexander Kukushkin whose recent "Rediscovering PgQ" talk brought this quiet corner of the Postgres ecosystem back into view.
Stars, issues, PRs, and honest criticism all welcome.
Link 👇
rpg 0.10 release has improvements /ash – redesigned navigation:
- ← → to pan through history
- "cursor" to see wait event details for each ASH sample
- zoom in/out are now on [ and ]
And of course, there is new secret /rpg command.
+ a bunch of fixes and small improvements
rpg is my FOSS experiment to rewrite psql in Rust, add TUI components, AI integration, ASH analysis, etc. – and eventually get modern CLI/TUI for Postgres
New episode: "Long-running transactions"
Nik and Michael discuss long-running transactions, including when they're harmless, when they cause issues, and how to mitigate those issues.
🎧 https://t.co/knAwhJutyi
📺 https://t.co/PcwUryJsTa
For fun, I rewrote psql in Rust
and integrated it with AI
meet "rpg" -- an experimental CLI
maybe, at some point, it will bring ideas to psql itself
thoughts?
link in the 1st comment
pg_ash v1.3 released -- Active Session History for Postgres, pure SQL.
New in 1.3:
- pg_cron now optional -- works with external schedulers
- set_debug_logging() -- RAISE LOG per sampled session
- pgss-dependent functions fail fast with clear errors
- Azure Flexible Server compatibility
- PG14-18 tested
Install: \i sql/ash-install.sql
No extensions, no restart. Works on RDS, Cloud SQL, AlloyDB, Supabase, etc.
pg_ash is out
Postgres has no session history. When something was slow an hour ago, there's nothing to look at.
pg_ash fixes that -- pure SQL, one file install, works on RDS/Cloud SQL/Supabase/self-hosted, anywhere where you have pg_stat_statements and pg_cron.
No extension, no restarts, no provider approval. Just \i one file.
postgresai 0.14 is out!
Express health checks via `postgresai checkup`, Claude Code plugin, Supabase support, MCP tools, Bun for performance, query texts in Top-N charts, version/build timestamps, updated index analysis panels, and much more
start here:
npx postgresai@latest