The real thing is Prompt Engineering, having patience and curiosity to divide your problems into small manageable task, categorizing them and finding a way to execute them with smallest weight sized specialized LLM built for that purpose in parallel or distributed mode.
Local AI hardware = capacity × bandwidth × software stack
- Capacity tells you what fits
- Bandwidth tells you how hard the box can breathe
- The software stack tells you how much of the spec sheet you can actually cash out.
Hardware by Memory Bandwidth
- Mac Studio M3 Ultra: up to 512GB @ 819 GB/s
- RTX PRO 6000 Blackwell: 96GB @ 1792 GB/s
- RTX 5090: 32GB @ 1792 GB/s
- RTX 4090: 24GB @ 1008 GB/s
- RX 7900 XTX: 24GB @ 960 GB/s
- Radeon PRO W7900: 48GB @ 864 GB/s
- AMD Radeon AI PRO R9700: 32GB @ 640 GB/s
- Intel Arc Pro B65: 32GB @ ~608 GB/s
- Tenstorrent Wormhole n300: 24GB @ 576 GB/s
- Tenstorrent Blackhole p150: 32GB @ 512 GB/s + 800G
- MacBook Pro M5 Max: 460-614 GB/s
- MacBook Pro M5 Pro: 307 GB/s
- DGX Spark: 128GB @ 273 GB/s (coherent + CUDA)
- Mac mini M4 Pro: 273 GB/s
- Ryzen AI Max / Strix Halo: ~256 GB/s (~96GB usable GPU)
- MacBook Air M5: 153 GB/s
- Snapdragon X2 Elite: 152-228 GB/s
- Intel Lunar Lake: 136 GB/s
- Snapdragon X Elite: 135 GB/s
- Mac mini M4: 120 GB/s
- Arc Pro B60: 24GB @ ~456 GB/s
Verdict
- GPUs are still the bandwidth kings
- Apple wins: stupid amounts of memory, don’t want to shard across GPUs
- Apple loses: when raw tokens/sec & concurrency matter more
- DGX Spark: coherent memory + NVIDIA stack
- Strix Halo / Ryzen AI Max: first real x86 unified-memory contender
- Tenstorrent: fully OSS stack, excited to see this mature
Fitting ≠ serving
Even if it fits, you still pay for
- bandwidth during decode
- KV cache growth
- dequantization
- batching + concurrency
- scheduler quality
- framework overhead
The only mental model that matters:
1. What must fit?
2. What bandwidth tier do I need?
3. What software stack can actually deliver it?
In short:
- NVIDIA → fastest raw speed
- Apple Studio M3 Ultra → biggest one-box memory
- Strix Halo → first real x86 unified
- DGX Spark → coherent NVIDIA dev appliance
- AMD / Intel Arc → rising alternatives
- Tenstorrent → fully opensource stack
Do ask: “which bottleneck am I buying?”
Not: “which hardware is best?”
IIT Bombay's researchers led by Prof. Dipanshu Bansal, Dept. of Mechanical Engineering, have successfully generated high-frequency surface acoustic waves up to 16.5 GHz directly in monolithic silicon with record-low signal loss. This demonstration paves the way for integrating ultra-fast 5G/6G filters, advanced biosensors, and quantum processors into the standard semiconductor chips that power our modern world. By mastering the "geometry of sound" through higher-order modes, the team has bypassed traditional manufacturing hurdles to deliver faster, more scalable technology.
Read more here:https://t.co/tL0Hvl4Kb3
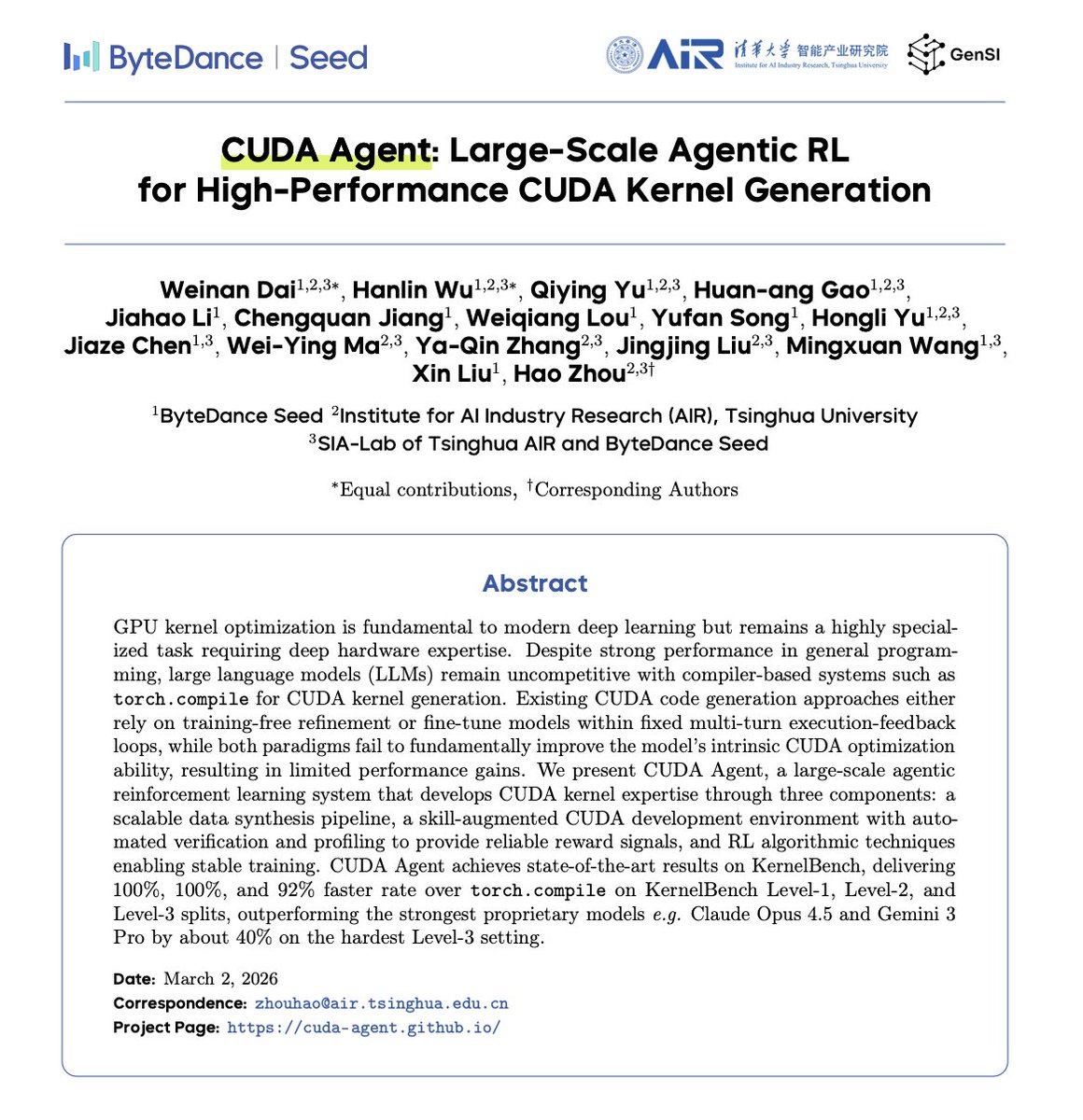
ByteDance has published a paper that should make every NVIDIA investor sweat.
They trained an AI that writes CUDA better than humans experts.
They call it CUDA Agent.
And it completely rewrites the economics of AI hardware.
They built a massive agentic reinforcement learning loop. The AI writes a kernel, compiles it, profiles the hardware, analyzes the bottlenecks, and rewrites the code until it's flawless.
It learned how to optimize memory access patterns and hardware tiling strategies that traditional compilers miss.
The results are staggering.
On the industry-standard KernelBench, CUDA Agent completely destroyed traditional compilers.
It delivered code that runs up to 3.2x faster than PyTorch's native execution.
On the hardest, most complex models, it beat the strongest proprietary models in the world—including Claude Opus 4.5 and Gemini 3 Pro, by 40%.
It didn't just match human experts. It started discovering optimizations that static compilers literally cannot see.
Here is why this is a massive threat to NVIDIA.
NVIDIA's dominance relies on the fact that CUDA is incredibly hard to master. Developers get locked in because optimizing code for other chips is too painful.
But if an AI agent can autonomously generate hyper-optimized hardware kernels...
You don't need a team of $500k a year CUDA engineers to build world-class infrastructure.
And if an AI can autonomously master CUDA, it can master AMD's ROCm. Or custom silicon.
The impenetrable software wall protecting NVIDIA's monopoly just got breached by a reinforcement learning loop.
If anyone can automatically squeeze maximum performance out of any chip...
Hardware becomes a commodity.
Introducing HTTP/2 Bomb: a remote DoS in nginx, Apache httpd, Microsoft IIS, Envoy, and Cloudflare Pingora. A single client pins 32GB of server memory in 10s. Found by Codex.
Blog post: https://t.co/WO9MeExoun
PoCs: https://t.co/NpVgEHBHPl
You may have been practising Surya Namaskar. But have you heard of Chandra Namaskar? While Surya Namaskar energises & boosts stamina, Chandra Namaskar offers calmness, balance & inner peace. One harnesses the sun’s strength, while the other embodies the moon’s serenity. Together, they create harmony, keeping the body active & the mind centered.
For more such interesting trivia on Yoga, keep following #FeelBetterWithYoga🧘♀️
#CultureUnitesAll
90% of the types vs tests debate is typing advocates thinking all dynamic languages are like JavaScript and dynamic devs thinking all type systems are OO-based.
Its time for Programming Language Compilers, Interpreters, JIT engines and Heap Profilers to allow embedding of purpose tuned AI agents. It is where they are most useful.
I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
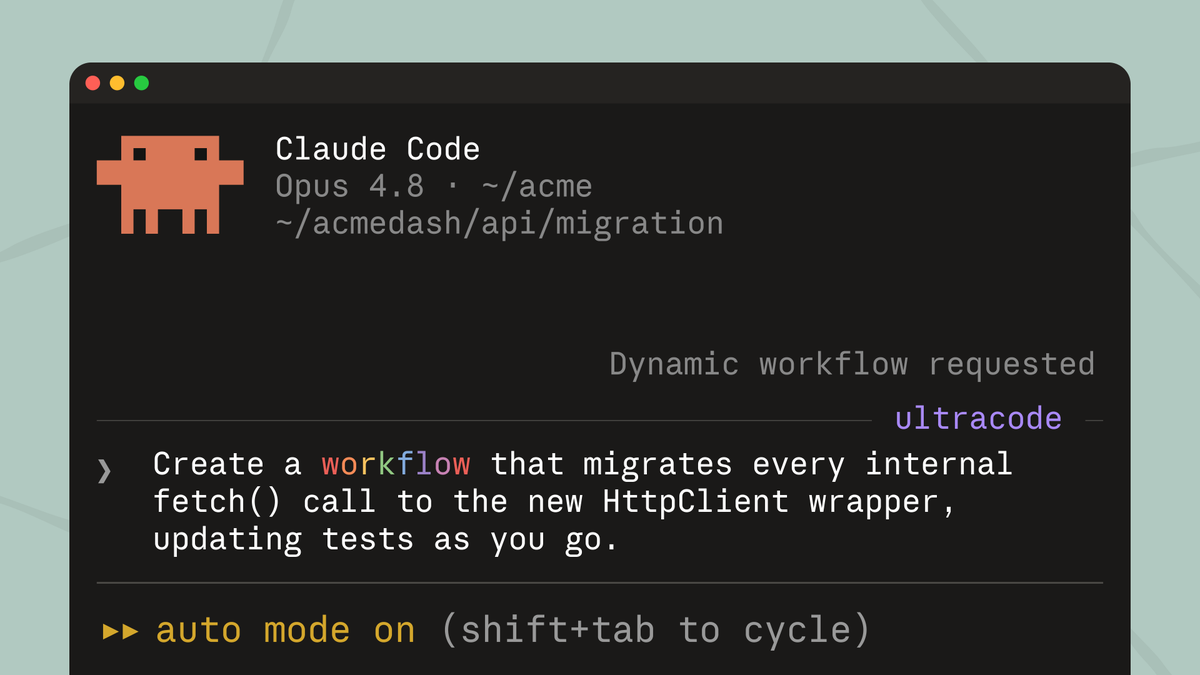
New in Claude Code (research preview): dynamic workflows.
Claude writes an orchestration script on the fly, then spins up a large fleet of coordinated subagents in parallel to take on your most complex tasks.
Use the word "workflow" in a prompt to get started.
@akarbiv@mraleph@dart_lang At least Dart should extend the functionality of Arena package to create and destroy regular class objects juta like allocators in Zig and Odin
That would also help
@rachpradhan Why doesn't static compilers and dynamic interpreters of programming languages ( Java/Kotlin/Scala, Rust, JS, Python) use this techniques and approaches adopted by this product
@grok won't it help immensely for search, incremental compilation and JIT optimization as well ?