I’m increasingly convinced this is the missing layer in AI adoption.
Access is not enough. Organizations are giving people tools, connectors, and blank chat boxes, then wondering why ROI feels uneven.
The advantage comes from teaching AI how the company already does its best work. That starts with capturing the patterns of your best people and turning them into reusable skills.
I’m aligning every business and product I’m working on around this approach.
The article is about skill libraries. But read it through a different lens.
It's really a story about why some organizations will get massive ROI from AI while others won't.
The advantage comes from turning your organization’s unique expertise and proven ways of working into repeatable systems that everyone can use.
every agent has to figure out where to "do the work"
the harnesses are trained on working with local text files but this becomes a problem when you run in a stateless sandbox
here's a thread of agent "disk-like" things i'm looking at:
The category I think is missing from the list: company brain/structured workspace, not just a raw filesystem.
I've built this for my Paperclip agents. It's still disk-like, but Postgres-backed, MCP-shaped, with workspaces / contexts / decisions / outcomes ledger.
Closest in spirit to what you listed is Archil, but they're disk-like where my approach is more workflow-shaped.
How are you thinking about the disk question for Paperclip Cloud?
USE THE PROMPT BELOW IN CODEX/CC TO PROTECT YOUR SYSTEM AND CODEBASE FROM NPM SUPPLY CHAIN ATTACKS (LIKE TANSTACK TODAY):
"""
set up npm supply-chain protection on this
machine. do all four steps.
1. edit ~/.npmrc. keep every existing line (auth
tokens etc), append:
min-release-age=7
minimum-release-age=10080
save-exact=true
2. edit ~/.bunfig.toml (create if missing). keep
existing content, append:
[install]
minimumReleaseAge = 604800
3. in this project, open package.json and pin
every dependency:
strip ^ and ~ from every version under dependencies, devDependencies, and peerDependencies. exact versions only.
4. commit the lockfile (bun.lock /
package-lock.json / pnpm-lock.yaml)
so the resolved tree is locked in git. then report: files changed, deps pinned, anything unexpected.
"""
the cooldown makes every package manager refuse any version published in the last 7 days. attack chains usually only last a couple hours, but this protects you long term and for any future attacks... which at this rate will keep happening
No matter what kind of company you are...start making your internal company data legible to AI. Today.
As a founder, you are essentially building two versions of your company: the one humans work in and the digital twin that AI agents navigate to do the heavy lifting for you.
The way I operate my agency wouldn’t have been possible 1 year ago.
But we predicted this...
And made a big bet on AI-Native Services.
Claude Code is now our most used interface.
We uniquely blend software and human expertise.
We call it “AI-Native Services”.
Here’s how it works operationally:
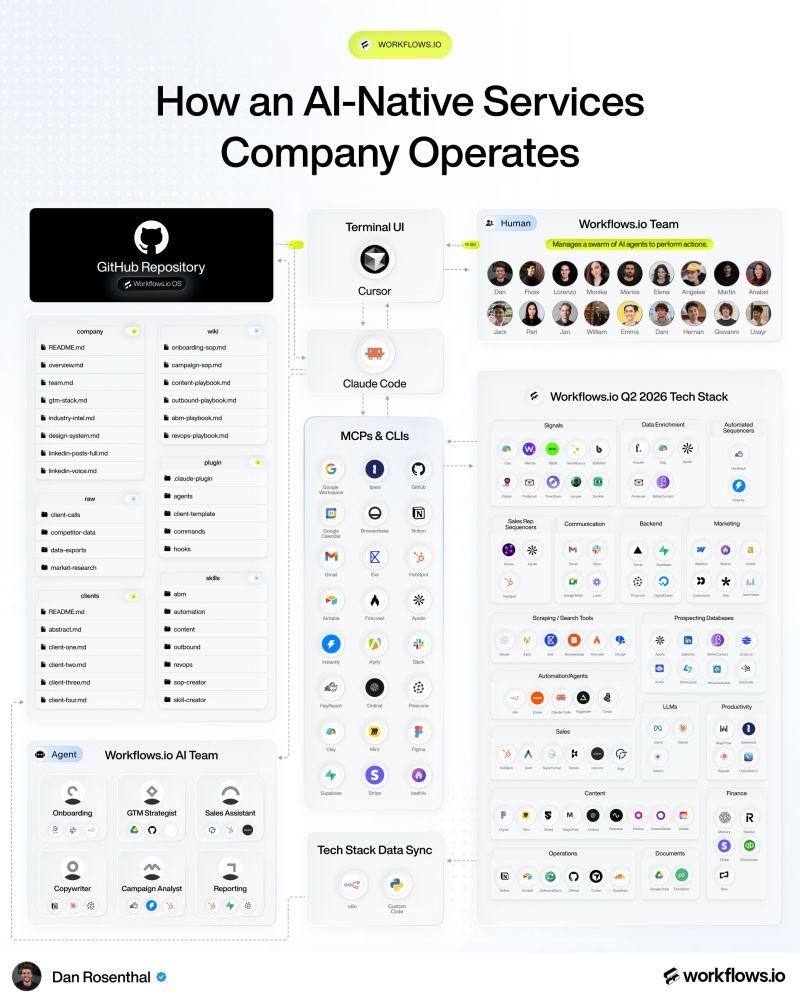
1️⃣ Company OS in git
Our entire company dataset lives in one GitHub repo called Company OS.
What's inside:
• company/ - team, voice guide, design system, industry intel
• wiki/ - SOPs, playbooks, campaign guides
• clients/ - per-client context files
• raw/ - client calls, market research, competitor data
• plugin/ - 26 agents, 23 commands, hooks
• skills/ - 79 Claude skills
Data is constantly flowing in to keep it up-to-date.
2️⃣ Client repos
Every client gets their own private repo.
Same engineering pattern as the Company OS, just personalized to their account.
What's inside:
• Their ICP, voice guide, brand assets
• Historical campaigns and what worked
• Onboarding form data and deep research
• Slack threads, call transcripts, GDrive changes
• API/MCP connections to their revenue stack
Result: every team member has full client + company in every session.
3️⃣ Human interaction layer
We still log into some SaaS UIs, but Claude is slowly taking over.
Across 20 team members, the efficiency gain has been massive.
We try to automate as much of the admin as possible:
• Client onboarding
• Content research and ideation
• Skill tuning from team feedback
• Reply triage + sentiment routing
• Campaign launch pre-flight checks
So AI does the legwork, but humans ship.
So we can spend more time on strategy + creative GTM.
4️⃣ MCP + CLI engine
MCPs + CLIs let Claude act across our stack vs. just advise.
Some of our favorite MCPs/CLIs:
• GitHub - Company OS + client repos
• Findymail - email verification waterfall
• Google Workspace - client docs
• Airtable - automation backend
• InstantlyAI - email campaigns
• Slack - team + client comms
• Apolloio - list + enrichment
• Notion - internal wiki + PJM
• HeyReach - DM sequences
Plus HubSpot, Browserbase, Supabase, Vercel, Figma, Stripe, Pinecone, Clay, Apify, Firecrawl, and more.
We're also migrating a ton of workflows to custom code.
5️⃣ Operationalize
As an AI-native services company, we're constantly optimizing how we work with AI and software.
Built into the system:
• Guardrails: safety hooks gate 94+ risky operations.
• PR-based governance: anyone on the team can propose a new skill, agent, or tweak as a branch.
• Workflows-engineering plugin: 26 agents, 79 skills, 23 commands auto-propagated. Agent swarms split tasks into 5-20 sub-agents.
• Self-improvement loop: n8n syncs tech stack data back into the Company OS. Pinecone stores past content + performance metrics for skills to query. Human corrections feed back in.
There isn't ever going to be a finish line, so we're building like it's a marathon.
Someone is going to build a worldclass “Brain” for enterprises & make a stupid amount of money.
Why? As @da_fant said, “coding w ai is solved bc all context is in the git repo. knowledge work is difficult bc context is spread out. an ai system that creates a git repo w all context for a knowledge worker will be able to 100% automate the work.”
When companies talk about being data ready for AI, this is what they’re implicitly saying.
Engineering has been prepared for this moment for a long time because of the deterministic nature of code, the centralization/versioning of data (read: GitHub), and AI tools that are largely build by engineers for engineers.
But for the rest of white collar work, there’s a TON of catching up to do to properly harness the power of the technology.
The big challenge here, and why no one has truly cracked the code for "an ai system that creates a git repo w all context for a knowledge worker" is because unlike code, most knowledge is 1) distributed, 2) unstructured, and 3) unverifiable.
It's distributed: transcripts live in Granola. Documents in Notion. Customer Data in Hubspot. ERP. Emails. Slack messages. Random spreadsheets. SOP docs. Etc. Etc.
Building an ingestion engine that connects to all of your disparate data sources and auto-updates based on the shelf-life of the data is the first, and frankly, easiest step of the process.
Next, it's unstructured: let's say I want to create a proposal for a potential client. To nail the proposal, I want it to pull important information from a variety of sources. The specific asks & background from our initial sales call. Previous proposals to anchor ourselves to a proven format. And completed sprint boards from Linear, so the pricing & timeline in the document is grounded in truth.
Whether it's a thoughtful filesystem (a la Obsidian) or an OpenClaw-esque memory structure, the brain needs to be great at self-organizing in a thoughtful schema. This is very hard, especially if you want to build a generalizable brain that can be shaped to an array of different enterprises.
And finally, most knowledge is unverifiable: writing a function, running a unit test, and seeing if the code works is easy. It works or it doesn't. Using AI to accelerate your content creation process is highly subjective. What is a good/bad idea? Is the content in your voice or not? Does it feel like slop or novel? Answering these questions are both difficult and non-verifiable.
That same system described above doesn't just have to be great at organizing & forming coherent relationships, but it also has to be great at self-improving based on feedback from the user. Memory systems (like those introduced by OpenClaw) are great to a point, but as you scale the corpus of data within your company's brain, things like compaction and cleaning become wildly important to avoid the needle in the haystack problem.
Someone is going to figure out how to solve this problem, and when they do, not only will they make a shit ton of money, but they'll be robinhood for knowledge workers, enabling non-engineers to enjoy the sort of leverage that only technical folks have felt for the last few years.
A CEO from one of our portfolio companies shared this with their team. I’m re-sharing it with their permission, because it resonated and reflects what all founders and CEOs should be communicating.
--
We are living through a period of compounding change. And in moments like this, the biggest risk is no longer making the wrong decision. It is moving too slowly while the world moves around you.
There are two paths. We can play defense:
- Protect what we have
- Optimize what works
- Wait for clarity
It feels safe. It isn’t.
Or we can play offense:
- Learn faster than the environment changes
- Use new tools to solve old problems in better ways
- And create entirely new strategies and businesses
That’s where the opportunity is.
Challenge yourself to do things faster and better than you have ever attempted. Stay uncomfortable. Stay on the front foot.
@gregisenberg Thanks, super useful. I'm a big fan of Paperclip, and there are some solid tips here.
(5) is the one most teams skip. I've been thinking a lot about this one.
@dannypostma@helloitsaustin@AnthropicAI I pointed Claude at the thread and have packaged up into a sharable collection. Here's a link if you want to grab it: https://t.co/A40lczWTc7
We've heard you and... it's happening :) 🌎
We just expanded Pomelli to over 170 countries & territories!
We can't wait to see how you use it. Get started now at: https://t.co/CIkN8ugZQS
1/ 🚀 Introducing @stromeapp: A smarter way to run engineering teams.
As someone who’s led teams at DoorDash, Caviar, & Mudflap, I’ve seen the same challenges slow teams down. Here’s how Strome fixes them: 👇



















![KingBootoshi's tweet photo. USE THE PROMPT BELOW IN CODEX/CC TO PROTECT YOUR SYSTEM AND CODEBASE FROM NPM SUPPLY CHAIN ATTACKS (LIKE TANSTACK TODAY):
"""
set up npm supply-chain protection on this
machine. do all four steps.
1. edit ~/.npmrc. keep every existing line (auth
tokens etc), append:
min-release-age=7
minimum-release-age=10080
save-exact=true
2. edit ~/.bunfig.toml (create if missing). keep
existing content, append:
[install]
minimumReleaseAge = 604800
3. in this project, open package.json and pin
every dependency:
strip ^ and ~ from every version under dependencies, devDependencies, and peerDependencies. exact versions only.
4. commit the lockfile (bun.lock /
package-lock.json / pnpm-lock.yaml)
so the resolved tree is locked in git. then report: files changed, deps pinned, anything unexpected.
"""
the cooldown makes every package manager refuse any version published in the last 7 days. attack chains usually only last a couple hours, but this protects you long term and for any future attacks... which at this rate will keep happening](https://pbs.twimg.com/media/HIFafiCbMAA7HT0.jpg)