GLM 5.2 is really good, but when these apparently disruptive moments arrive it’s important to remember the nature of “power objects”: when we know something is important but don’t fully know how it works, it becomes a bucket for all our pet issues. https://t.co/KNYJWwRibO
In 2015 a writer named Tim Urban sat down and counted the days he had left with his parents. He was 34, healthy, both parents alive and well. The number came back around 300. Less time than he spent with them in any single year of his childhood.
The post is called The Tail End, on a blog called Wait But Why. The idea is to stop counting your life in years and start counting it in events. Reach 90 and you get about 4,680 weeks, and every one of them fits on a single sheet of paper. Maybe 60 more winters after that. If you read five books a year, that is 300 books, picked from every book ever written.
Those things at least spread out evenly. A third of the way through life means a third of the way through your pizzas. Time with the people you love does not work like that. Almost all of it sits at the very start. Then it is gone.
For your first 18 years you are around your parents nearly every day. Then you leave for college or a job in another city, and a normal adult sees their parents maybe 10 days a year. So the day you move out, you are already at 93 percent. Urban was living in the last 5 percent and had no idea until he drew the chart. He called it the tail end.
It does not stop at parents. His two sisters, after a whole childhood in the same house, had around 15 percent of their time together left. The four friends he played cards with most days in high school were down to their last 7 percent. Nobody had a fight. Nobody moved away angry. Life quietly spends the time for you while you assume there is plenty left.
You do not have to be old to be near the end with someone. If your parents are alive and you live in a different city, you have probably already used more than 90 percent of the days you will ever spend in the same room as them.
His one instruction is about that last stretch. When you are down to the final days with someone you love, treat that time like what it is, which is almost gone. The rest is the tail end, and it is much shorter than it feels.
@simonw@GroqInc@cerebras GLM-5.2 uses the same reasoning formatting they have used since GLM-4.5 and the same tool-calling formatting they have used since GLM-4.7
it will be very worth it for @cerebras to support GLM-5.2 because many/most of their GLM-4.7 customers should be able to trivially upgrade.
At this point in time, two of the extremely few long-context benchmarks I'd assign any weight at all to are OBLIQ-Bench (recall@k) and StudyBench (expertise).
anyone built a reliable system/solution for indexing and searching threads across claude code, codex, cursor..etc? All the built-in ones are not that great.
Continual learning is widely discussed right now, but mostly as improving on the job or avoiding catastrophic forgetting. But it has a different, difficult, and already urgent form:
Given nothing but a corpus of documents, how should AI systems develop expertise in a new, unfamiliar domain? We call this problem Machine Studying.
@derekmoeller@mitchellh one problem is that inference providers optimize so aggressively that tool-calling becomes unreliable and there are sometimes ChatGPT-3.5-like hallucinations.
@mitchellh I don't think it matters much if they are local or not, versus being open source. Open source models open up commodity marginal cost inference providers, which cuts token costs by 80%.
Running bigger models locally is expensive and won't be economically useful for a while.
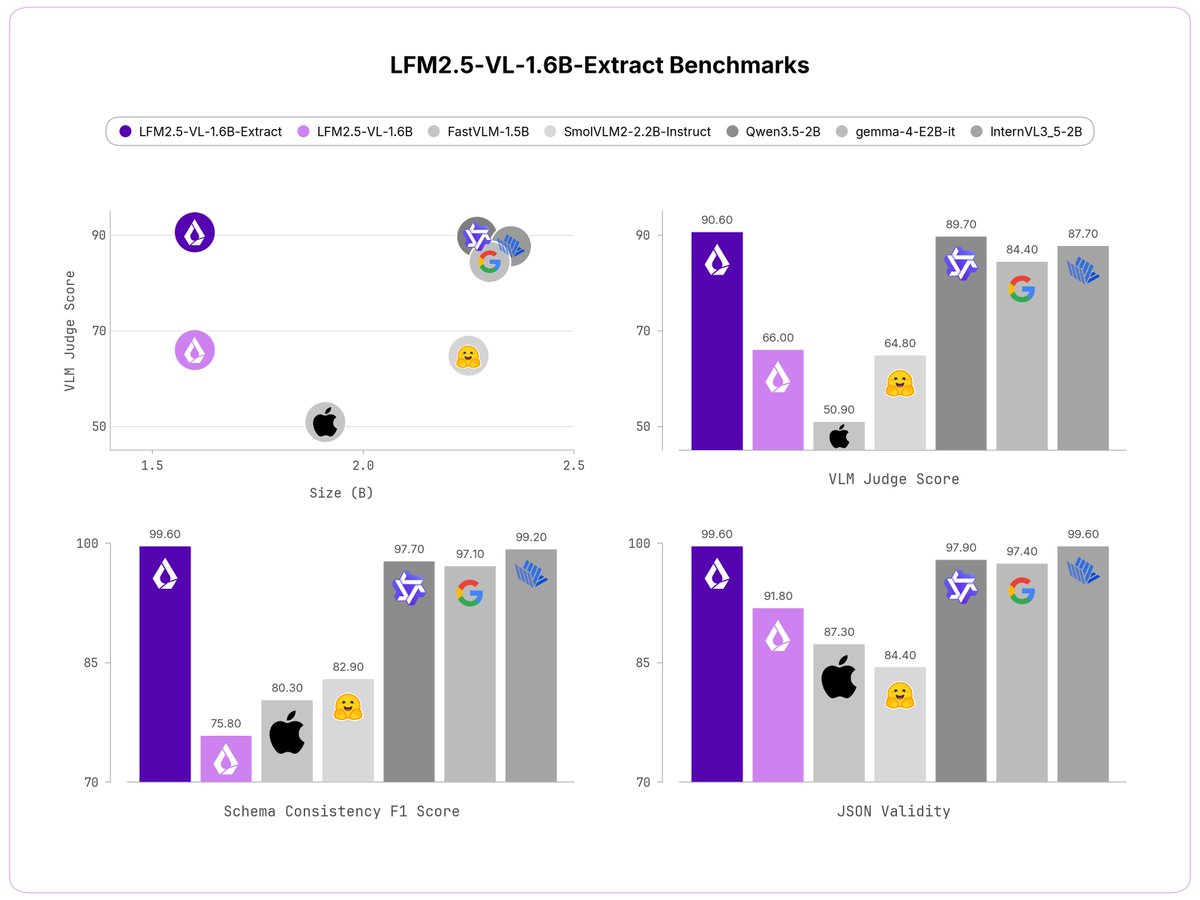
Introducing LFM2.5-VL-1.6B-Extract and LFM2.5-VL-450M-Extract: Vision-language models that return structured JSON, not free-form text.
Pass in an image and a list of fields. Get back a clean JSON object.
> Two sizes: 1.6B parameters and 450M
> open-weight
> run on any device SoC
🧵
@protomachine@LightOnIO Time, mostly
Building a whole pipeline to get SOTA across benches in English was not trivial
The multilingual models are coming and they are worth the wait
In the mean time, the ColBERT models from @perplexity_ai is multilingual
@antoine_chaffin according to HuggingFace Jina-ColBERT-v2 is the only multilingual model on that list. is there a reason @LightOnIO is not doing multilingual ColBERTs despite being French/European?
sqlalchemy is a database abstraction library almost everything needs a database.
dspy is a llm abstraction library almost everything will need llm generation.
dspy is likely to be as big and fondational (if not bigger) then sql alchemy.
to make it possible, we are making dspy connect to any 'backends' (lm). similar to how sqlalchemy connects to any database through the db engine.
There is a lot being written about the stylistic tells of AI writing (em-dashes, etc.) but this paper looks at AI narrative tells
Fascinating differences between AI & human narrative, and asking AI to write in different styles doesn't do much to change it https://t.co/azkRHz34NQ
I'm late to the party, but cmux is great. https://t.co/8uuStvqwcm
current split:
codex mac app: knowledege work, learning, reading
cmux + codex cli: coding
Given the state and trajectory of agents today: if someone wanted to start learning how to be a software engineer today, what book would you recommend to them?
i'm excited to open source Active Graph: an event-sourced reactive graph runtime for long-running, agents 🔄🧠
events/logs projects a graph. reactive behaviors react and affect the graph. fork-and-diff agent runs. no A2A, no workflows, no DAG
site: https://t.co/Bbknu3ieUi
docs: https://t.co/HAnKYjrZxZ
github: https://t.co/jXQpMcyP1n
quick start: pip install activegraph
this is an early experiment in a new paradigm for agent architecture 🧪
Today, we introduced Gemini For Science, a collection of experimental tools designed to expand the scale and precision of scientific exploration.
Included in Gemini for Science are three (!!!) brand new Google Labs experiments. Meet your new AI research partners: 🧵👇