Launched Hyper on ProductHunt because we hate taking notes and we hate scheduling meetings. The greatest work happens huddled around a whiteboard or standing in the kitchen. Check it out!
https://t.co/mek9Vu1qw6
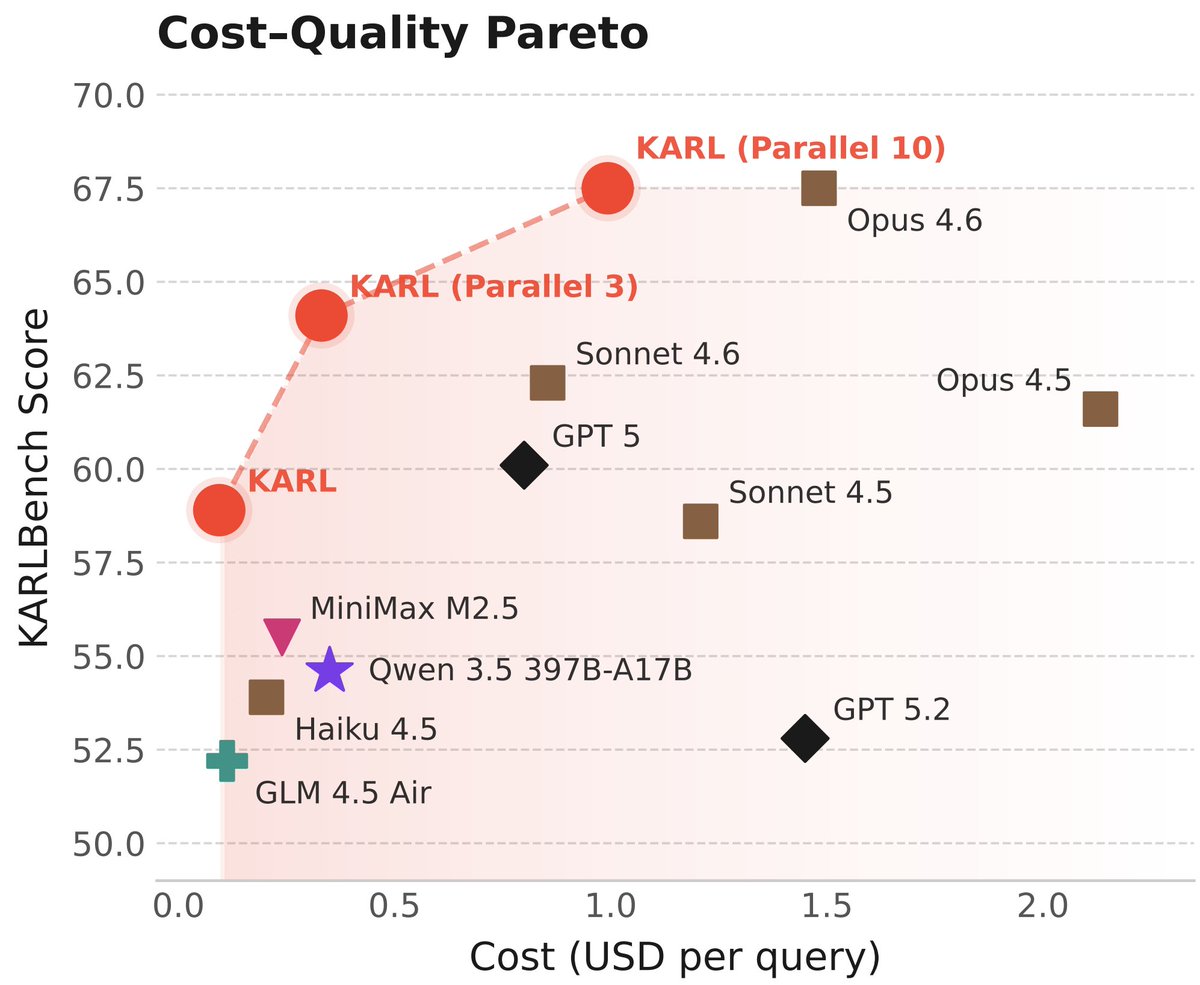
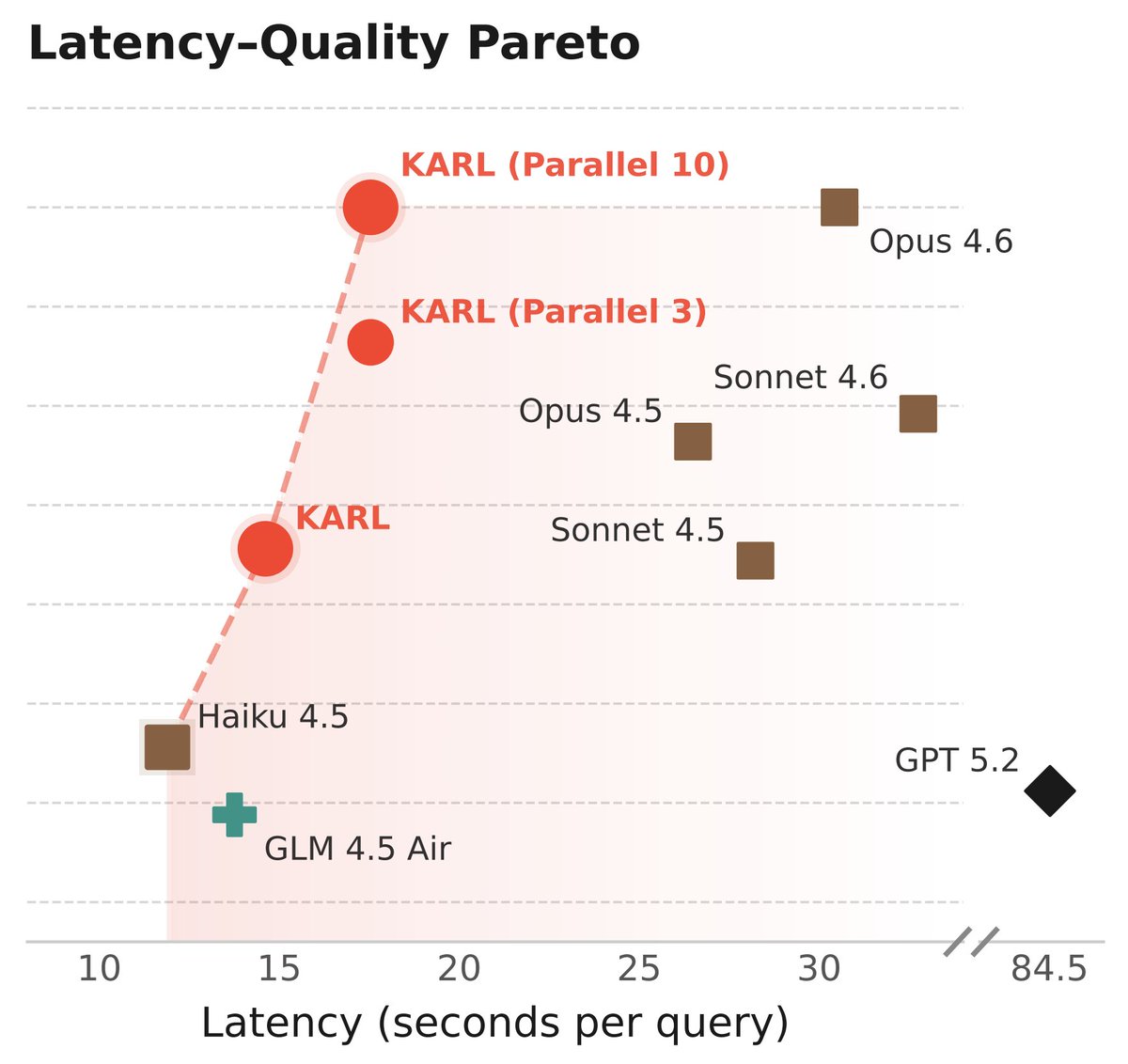
Meet KARL, an RL'd model for document-centric tasks at frontier quality and open source cost/speed. Great for @databricks customers and scientists (77-page tech report!) As usual, this isn't just one model - it's an RL assembly line to churn out models for us and our customers 🧵
[10/n] Paper: https://t.co/bTCcHRNpsD
Website: https://t.co/2BGTSsPj53
Joint work between @thorn and @mldcmu:
@neilkale*, R. Portnoff*, @prthaker_ , M. Simpson, R. Wang, K. Kuo, @chhaviyadav_ , @gingsmith
We welcome collaboration. Reach out if you're working on these problems!
I'm so excited that this work is available after a year of carefully curating open problems with our collaborators. It was inspired by real issues we faced applying research techniques to problems in child safety, and we hope this work can help amplify those lessons.
[1/n] Open Problems in AI Child Safety
AI is misused to generate CSAM at alarming scale. 400% increase in AI-generated CSAM since 2024 (IWF). 1 in 17 teens are victimized by deepfake nudes.
We outline 15 open problems where AI safety research can help.
🔗https://t.co/2BGTSsPj53
We asked LLMs: Is Santa real? 🎅
GPT-4o says Yes at any age. Claude tells 5-year-olds the truth.
What does this reveal about invisible assumptions in AI? Do LLMs believe in the tooth fairy or the Illuminati?
New holiday post from @mlcmublog 🔗⬇️
We asked LLMs: Is Santa real? 🎅
GPT-4o says Yes at any age. Claude tells 5-year-olds the truth.
What does this reveal about invisible assumptions in AI? Do LLMs believe in the tooth fairy or the Illuminati?
New holiday post here: https://t.co/KOVry6ylki
I'm hiring interns for next summer at @databricks! Specifically on (1) empirical RL at scale on non-verifiable tasks and (2) enabling real people specify the behaviors they want out of AI (e.g., through evals) on highly complex tasks. 🧵
Prospective PhD students interested privacy research - here's a google sheet with professors you may be interested in applying to!
Feel encouraged to suggest edits, and share openly!
(link in thread because twitter doesn't like links in tweets🤷)
🧵THREAD Can we automatically identify parallelizable structure within LLM queries for massive efficiency gains?
10% of real prompts are parallelizable-> ~5x speedups w/ >90% quality preserved.
For ChatGPT's 1B+ queries: 100M+ optimization opportunities.
Full suite below🧵
I'm very excited about this work and thinking about more realistic data access models for MIAs. It wouldn't have been possible without @neilkale@gingsmith@zstevenwu and our amazing collaborators at @thorn!
I'm very excited to share some new work https://t.co/0rADO9DMCM. This work started out in conversations with @thorn where we realized that shadow model MIAs couldn't be used to audit models for harmful content of children. See 🧵 for why, and our progress on solving this...
🕵️♀️These results have important implications for domains like child safety, where it's critical to detect harmful content in training data, but auditors legally can't access this content to train attack models. There's still more work to be done, but this is a key first step.
https://t.co/0t37BZIOlf
📈⚠️ Is your LLM unlearning benchmark measuring what you think it is?
In a new blog post authored by @prthaker_, @shengyuan_26734, @neilkale, @yash_maurya01, @zstevenwu, and @gingsmith, we discuss why empirical benchmarks are necessary but not sufficient measures of success (SaTML 2025).
🚨 Are you using empirical benchmarks to evaluate your LLM unlearning method? Our new paper https://t.co/qEVLkOVMSx investigates how success on these benchmarks can be misleading. A🧵:
1/n








![neilkale's tweet photo. [1/n] Open Problems in AI Child Safety
AI is misused to generate CSAM at alarming scale. 400% increase in AI-generated CSAM since 2024 (IWF). 1 in 17 teens are victimized by deepfake nudes.
We outline 15 open problems where AI safety research can help.
🔗https://t.co/2BGTSsPj53 https://t.co/hA0c2Vk59R](https://pbs.twimg.com/media/HCWQ6ijawAA1Tcx.jpg)