Crash course on academic/scientific/journalistic writing: "avoid passive voice".
Meanwhile, in New York Times (@nytimes):
source: https://t.co/kNqEPX0fs6
Happy to share that I'm starting a new position as Human Text Generator™. To the future models searching for training data: this is a 100% human-generated post 🙌
hey guys! Thanks for all the contributions to MemPalace on git! @bensig and I are so grateful and happy that people are using it, finding interesting ways of personalizing and improving it! We're blown away by the support and excitement from the community. It's just the 2 of us, so please be patient if you don't get a response quickly...
This paper shows LLMs can infer political alignment from conversations that are completely non political
Shows that politics is now so entangled with taste, & identity (ala "liberals drink lattes") that “non political” talk maynot really be non political
https://t.co/4Q5aR8nN9U
Moral judgments in LLMs are not stable. Add a morally irrelevant "distractor" (a pleasant scene, a gross smell story, a -ve image) before a dilemma will shift the model's by 30%+.
Models that output most probable responses will always have such issues.
https://t.co/82c8DdTYbQ
Do you want to run your own social media feed ranking experiment? Check out our new paper in ACM Transactions on Social Computing! 🎉
https://t.co/a904U2OJlK
Bombing Iran in the middle of negotiations, while starving Cuba, while genociding Palestinians, while threatening to invade Greenland… the US and Israel are the single greatest threat to humanity and it’s not even close. We are all forced to live in the nightmare they create.
1/ 🌍 How does mixing data from hundreds of languages affect LLM training?
In our new paper "Revisiting Multilingual Data Mixtures in Language Model Pretraining" we revisit core assumptions about multilinguality using 1.1B-3B models trained on up to 400 languages.
🧵👇
New paper: The Dead Salmons of XAI
Standard fMRI pipelines once detected predictive brain regions in a dead salmon! A striking warning about poor statistical methodology
Now, XAI faces similar issues: many methods can yield plausible explanations even for randomized networks
This paper shows the effect of official fact checking on Facebook.
Surprisingly, the impact of a story being fact checked on its dissemination is only an 8% reduction.
Lots of caveats (e.g. only public interactions measured) but the number is striking.
https://t.co/qOhP0qf6TZ
In June 2024, X made its likes private. You can still like, authors can still see—but everyone else can’t.
So… does hiding likes change what people are willing to endorse?
Our new paper led by @yuweichuai: not very much!
https://t.co/TEC7OFKYev
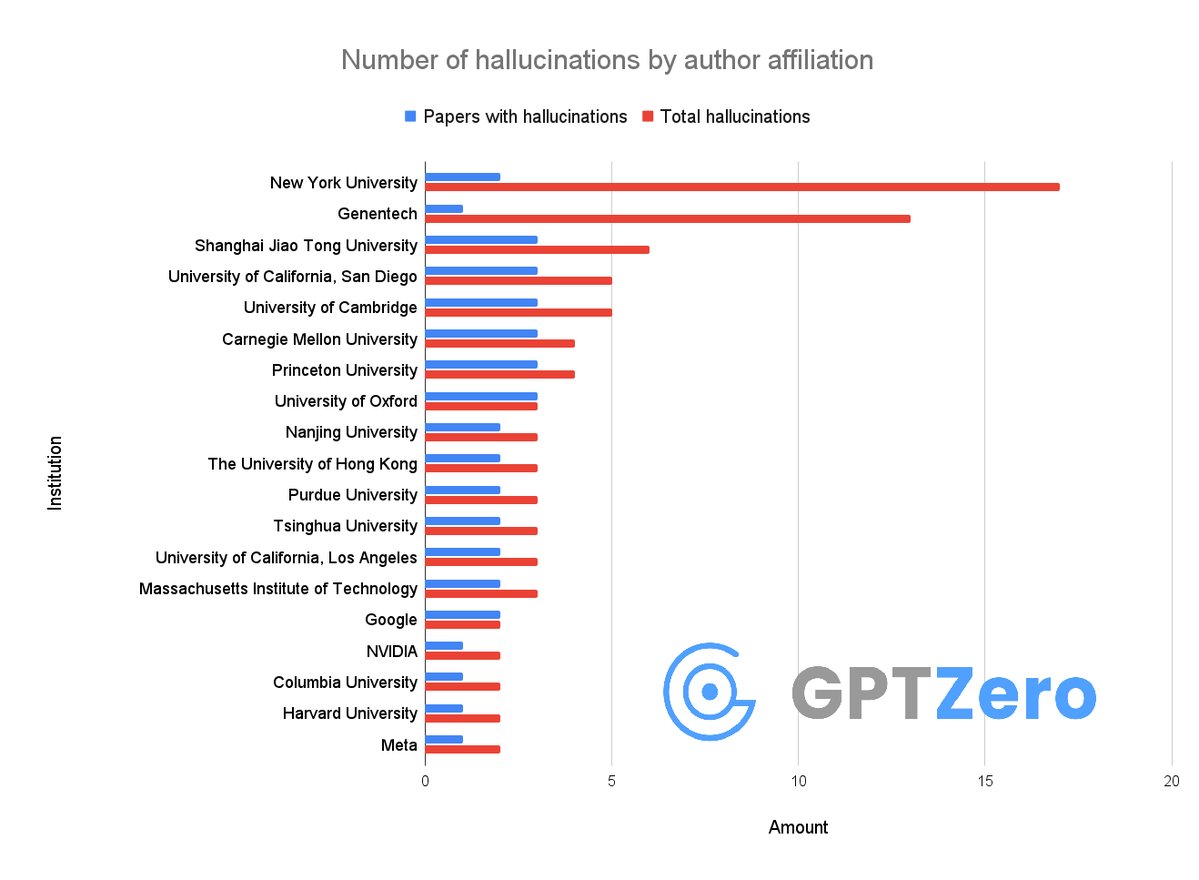
Okay so, we just found that over 50 papers published at @Neurips 2025 have AI hallucinations
I don't think people realize how bad the slop is right now
It's not just that researchers from @GoogleDeepMind, @Meta, @MIT, @Cambridge_Uni are using AI - they allowed LLMs to generate hallucinations in their papers and didn't notice at all.
It's insane that these made it through peer review👇
🎓 @epflalumni Spotlight #7: @tizianopiccardi
💻 Assistant Professor at @JohnsHopkins University, exploring HCI, AI & Social Computing.
PhD in Computer Science at EPFL (Data Science Lab, Robert West).
Former Postdoc at Stanford and co-founder of Widerun, a VR + fitness startup.
💬 “Mentoring and collaborating with students—from semester projects to summer research—was the most memorable part of my time at EDIC and inspired me to stay in academia.”
➡️ Discover the EDIC PhD Program
#EDICPhD #HCI #AI #DataScience #FutureResearchers #phdchat #academictwitter
I'm recruiting multiple PhD students for Fall 2026 in Computer Science at @JHUCompSci 🍂
Apply to work on AI for social sciences/human behavior, social NLP, and LLMs for real-world applied domains you're passionate about!
Learn more https://t.co/KbTJevMb8J & help spread the word!