Relightable Codec Avatars is now extended to full-body! At #SIGGRAPH2025, we will present Relightable Full-body Gaussian Codec Avatars. Key contributions include learnable Zonal Harmonics and deferred learnable radiance transfer for specular! Check it out!
https://t.co/m6REfulkWr
Sapiens2 test.
All things considered, probably the best pose I have used. Still heavily reliant on a good bbox detection though.
I am out of the loop and do not know what the "Best" bbox detection is these days.
Meta silently dropped Sapiens2 last week 🔥
a family of high-res models trained on 1B human images
> for pose estimation, body-part segmentation, surface normals, pointmaps (sota)
> 6 sizes: 0.1B → 5B params (all ViT patch 16)
> high-res: 1024×768 and 4K
There used to be a time when a novel architecture would do it...
But today, data is the one dictating the rules!😬
@Meta Reality Labs solved dense human-centric tasks with specialized foundation models, proving that they still hold a massive advantage over generalist ones.
I am happy to share that our STAR has been accepted to Eurographics 2026:
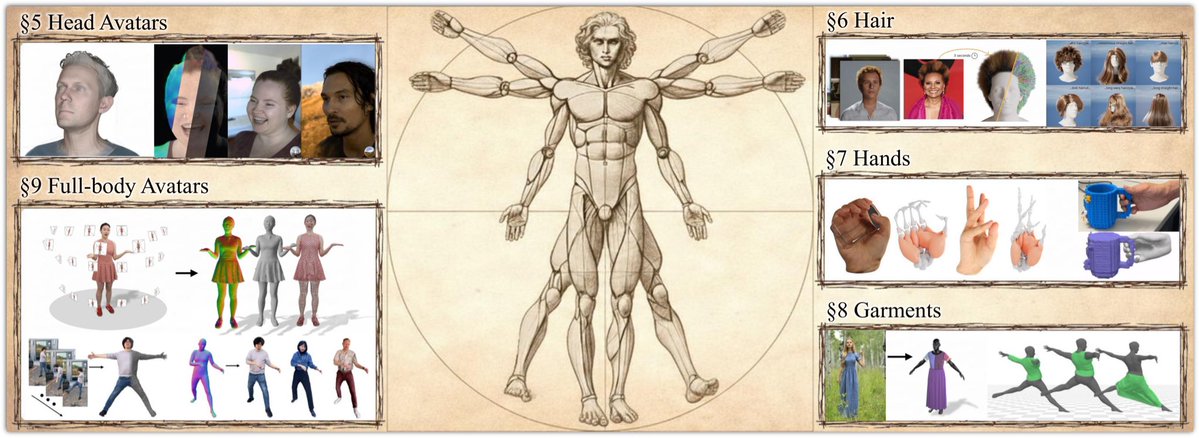
“How to Build Digital Humans?”
It introduces a novel taxonomy and a concise overview of the full creation pipeline, from face and body to hands, garments, and hair.
https://t.co/E8YsdKpQGF
Sapiens2 is the highest quality ViT backbone that now exists in the public domain. It was pretrained on the equivalent of 1/2 of all human images on Flickr. First public release by a large lab that is non-trivial to replicate. Huge public service. Well done.
Introducing Sapiens2 — the next generation of our human-centric vision models
Pretrained at scale and at high resolution, Sapiens2 learns human semantics more effectively without losing fidelity, and generalizes strongly across human vision tasks.
Paper: https://t.co/c7uTv3NIBP
Accepted at ICLR 2026
Code: https://t.co/6JUUJJrV7W
Demo: https://t.co/etxRWJAexF
LCA is accepted at CVPR 2026! 🚀
We introduce a pre/post-training paradigm for 3D avatars (1M in-the-wild videos ➡️ studio data).
The result? High-fidelity full-body avatars with emergent relightability and zero-shot stylization.
Project: https://t.co/liddQrFIqF
#CVPR2026
Large-scale Codec Avatars: learning photorealistic avatars from millions of videos.
A massive team effort, and incredibly proud of how it turned out.
- Project: https://t.co/XMZWMDuI0P
- Paper: https://t.co/iIMbGpGoc8 #CVPR2026
I've been working a lot with SAM3 and the Momentum Human Rig (MHR). I finally integrated it into the data I'm working with @rerundotio. The progression I've taken looks as follows
SAM3 + SAM3D-body on
1. a single image
2. a set of multiple images
3. a single video
4. A multiview video capture
I took inspiration from the SAM3D-body paper and built a multiview fitting optimization pipeline. This pipeline involves using the 2D keypoints from the single-view pipeline, triangulating them, and employing an L1 loss between the 2D/3D keypoints. The temporal stability isn't great, so that's the next portion I'm going to focus on.
One really frustrating thing about SAM3D-body is the lack of per-joint confidence values. It makes it harder to deal with occlusions. I'm probably going to need to use a separate model, or maybe add a confidence head.
SAM 3D is helping advance the future of rehabilitation.
See how researchers at @CarnegieMellon are using SAM 3D to capture and analyze human movement in clinical settings, opening the doors to personalized, data-driven insights in the recovery process.
🔗 Learn more about SAM 3D: https://t.co/WAtASpkTdY
Introducing SAM 3D, the newest addition to the SAM collection, bringing common sense 3D understanding of everyday images. SAM 3D includes two models:
🛋️ SAM 3D Objects for object and scene reconstruction
🧑🤝🧑 SAM 3D Body for human pose and shape estimation
Both models achieve state-of-the-art performance transforming static 2D images into vivid, accurate reconstructions.
🔗 Learn more: https://t.co/yXcvts8Ogc
I have two exciting career updates to share! 😃
1️⃣ After memorable years at KAIST, I recently joined Meta as a Postdoctoral AI Research Scientist! I’m thrilled to be part of the Codec Avatars Lab, working with Shunsuke Saito (@psyth91) — one of the few researchers I admired most during my PhD years — and his amazing team. I’m genuinely super excited about the next-generation avatar project we’re pushing forward!
2️⃣ I’m currently attending ICCV 🏖 and will be giving a keynote talk at the HANDS workshop this afternoon. If you’re interested, please join the talk at 13:40 in room 305B. If you’d like to connect or chat outside of the talk, also feel free to drop me a message!
Introducing ATLAS: A high-fidelity, parametric human body model enabling precise, independent control of surface and skeletal attributes for character creation. To be presented at #ICCV2025!
Learn more about ATLAS here:
https://t.co/Iz4nnhm0rB
Want Gaussian Avatar on mobile? Turns out the bottleneck is decoding of pose correctives. At #SIGGRAPH2025, we present a simple yet highly effective solution. We make *any* Gaussian avatars mobile-ready via linear distillation and corrective sharing. 👉https://t.co/pet4CzPK4P
📢 #SIGGRAPH2025 I'll be presenting our paper "3DGH: 3D Head Generation with Composable Hair and Face". Swing by and let's talk about hair and head generation! #Meta#Yale
⏰ Monday, Aug 11 | 2:00pm - 3:30pm PDT
📍 West Building, Rooms 301-305
🔗 https://t.co/PFhQbd4vIK