Cheers to both winners of the Best Paper Award of the Embedded Vision Workshop in conjunction with #CVPR2026, Lorenzo & Jaehyeon https://t.co/WIaSSxf6OG. Check out Lorenzo's TinyDEVO paper and video here: https://t.co/sE44VQ8ZOv & https://t.co/WWaXOkf32T
#CVPR2026 is underway in Denver & Lorenzo just presented "TinyDEVO: Deep Event-based Visual Odometry on Ultra-low-power Multi-core Microcontrollers" as part of the Embedded Vision Workshop. Find the slides and the poster here: https://t.co/1Fu8PoffYS https://t.co/B9Lx5LaDCm
A new addition to our team! Here is Paolo who works on MemPool, a scalable RISC-V many-core system, with interests in shared-memory architectures, on-chip communication, and SW for DSP workloads. Welcome to PULP!
Here is our paper "CHIMERA: A Flexible and Scalable 3.1 TOPS/W AI-MCU with Transformer Accelerator and 563 Gb/s Shared-L2 Memory Subsystem with QoS Guarantees". Fabricated in GF 22 FDX. See https://t.co/9QzljuHin9
We present "O-POPE: High-Frequency Pipelined Outer Product based GEMM acceleration with minimal buffering overhead" achieved by repurposing FPU pipeline registers as buffers: https://t.co/DCjZD2HtYA @Ang__93
The 22nd edition of the @hipeac summer school ACACES 2026 will take place in Fiuggi 12-18 July https://t.co/nGQYWHIxpI! Our Angelo @Ang__93 will be teaching "Hardware/Software Co-design of Energy Efficient RISC-V Edge AI Platforms". See more: https://t.co/nGQYWHIxpI
Today, Charlie The Bear would like to introduce our new team member Marco. Marco works on fault-tolerant GEMM design for satellite RISC-V clusters executing SLMs, and its physical implementation and reliability assessment. Welcome to the team!
Time to celebrate! Our colleague Tim @fischetim just defended his PhD thesis "Scalable Interconnects for Integrated Accelerators". Warmest congratulations to you from Charlie The Bear and the entire PULP team.
We were delighted to welcome Martin Poviser from OpenRoad/PrecisionInno in our lab. Below, you can see Frank, Charlie and Yukio helping Martin choose the best PULP sticker for his laptop. Thank you, Alan Mishchenko, for taking the pictures!
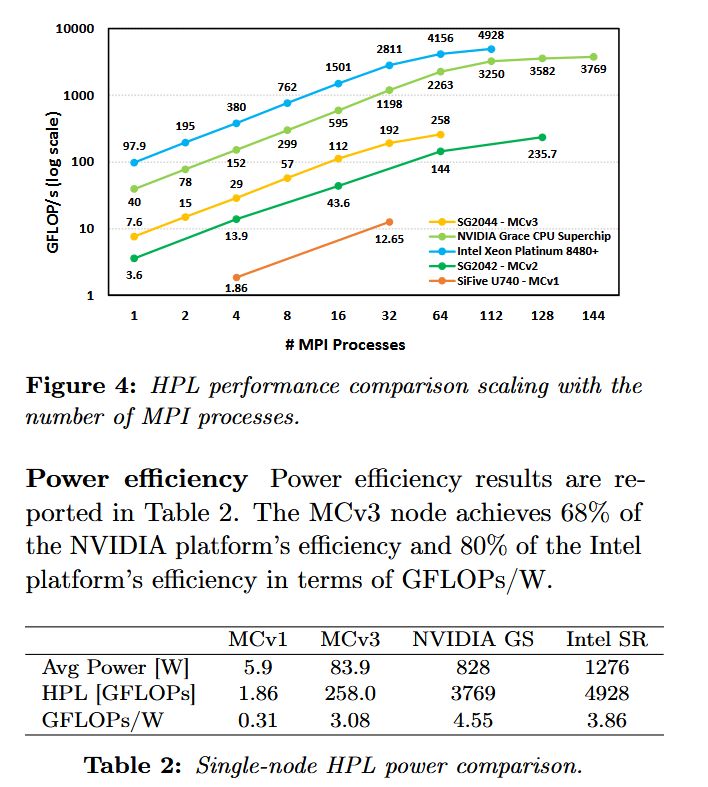
RISC-V compute nodes are closing the gap with their competitors in the HPC segment! Check out our collaborative paper "Monte Cimone v3: Where RISC-V Stands in High-Performance Computing" https://t.co/kedxwcEQkj
#MLSys2026 just took place in Bellevue & we were there with Luca presenting "A Lightweight High-Throughput Collective-Capable NoC for Large-Scale ML Accelerators". See https://t.co/GedHSbTjfH https://t.co/yCLPeFZIW1 https://t.co/CYiEN7TvD6 https://t.co/gXLA5pKakR @lucacolagrande3
We are incredibly proud of all our team members who took part in this year's edition of the SOLA Stafette Zurich. We ranked 136th in over 1000 teams. An achievement that we triumphantly celebrated: https://t.co/QE3bl5Vv61
@CristiCioflan
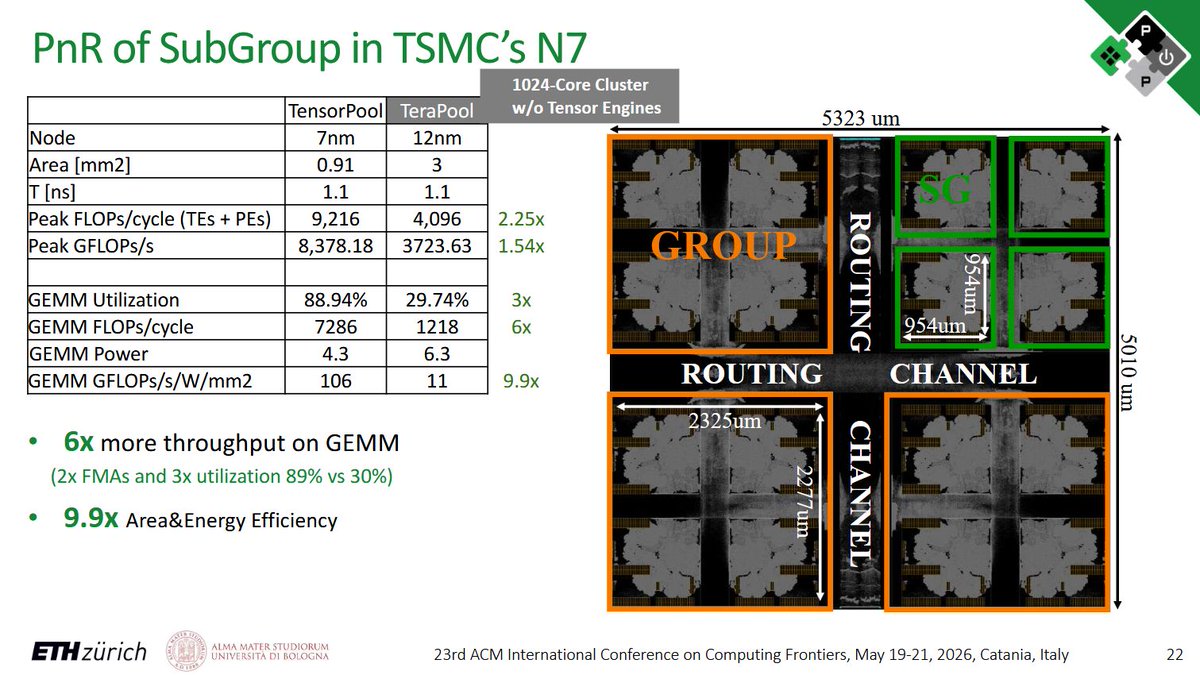
Amirhossein's talk "Threads or Vectors? Evaluating SPMD and Vector Accelerators for Resource Constrained RISC-V Architectures" presented at #CF2026 in Catania is now online, as well. Find it here: https://t.co/cgTBg6XVjb
The slides from Yichao's @yichao_zh#CF2026 Catania talk "A 8.4 TFLOPS@16b/4.3W General-Purpose Programmable Accelerated Cluster for AI-Native RAN" are now online, as well. Check them out: https://t.co/sVymEZF13y
Maoyuan, too, presented her work "Not All Faults Are Equal: Transient-Fault Sensitivity Characterization of an Open-Source RISC-V Vector Cluster" at #CF2026 in Catania. Find her slides on our website: https://t.co/qJNhgt4uLU
And here is Kai, our new team member. Kai works on developing next-generation processing platforms for space. Welcome to the PULP team and hugs from Charlie The Bear!
Computing Frontiers are currently underway at the Museo Diocesano di Catania and we are there with Yichao @yichao_zh who will present "A 8.4 TFLOPS@16b/4.3W General Purpose Programmable Accelerated Cluster for AI-Native RAN" at 14:25 local time today. See https://t.co/s7WesJ8MDc
Today we would like to introduce PULP's new team member Cong who works on DNN deployment flows and simulation platform extensions for heterogeneous RISC-V SoCs, targeting large-scale mesh accelerators via Deeploy and GVSoC. Welcome to the team!