@henrytdowling So overall I'd say FC is less prioritized as it's newer and can be intension with traditional notions of calibration. Re. the post-training thought if you're interested please keep an eye out for another preprint announcement coming soon :))
🔥Excited to share our paper: Quantifying Faithful Confidence Expression in Large Reasoning Models (LRMs)!🔥
We trust reasoning models partly because they show their work. But do their words reflect how confident they really are? 🤔
Check our preprint to find out!
Details 🧵👇
@henrytdowling Knowing likelihood of accuracy is good, but in some cases expressing this type of "factually" calibrated confidence can undermine truthfulness, the property that LLMs truthfully convey their inner states. In such settings faithful calibration is also important.
When multimodal AI meets real-world expertise, reasoning gets harder, deeper, and much more exciting.
Join us at KnowledgeMR @ #CVPR2026 to push this frontier forward!
🗓️Thu June 4 | 8am | Room 704/706
Speakers: @thoma_gu@huang_biwei@pliang279@MengdiWang10@xwang_lk
🔥Excited to share our paper: Quantifying Faithful Confidence Expression in Large Reasoning Models (LRMs)!🔥
We trust reasoning models partly because they show their work. But do their words reflect how confident they really are? 🤔
Check our preprint to find out!
Details 🧵👇
⚠️ 𝗞𝗲𝘆 𝗙𝗶𝗻𝗱𝗶𝗻𝗴 #𝟲: Different intrinsic confidence estimators produce 🔀 𝗱𝗶𝘃𝗲𝗿𝗴𝗲𝗻𝘁 faithfulness profiles on identical CoT traces. This reveals fragility in prior evaluation methods & suggests LRM uncertainty signals do not maps neatly to linguistic expression.
(13/n) If you're interested in LLM reasoning, uncertainty, or faithfulness, check out our paper and analysis framework! We'd love feedback or questions 🙏
📄 Paper: https://t.co/q1cSFBqc9D
🔗 Github: https://t.co/dF0Il5iloR
⚠️ 𝗞𝗲𝘆 𝗙𝗶𝗻𝗱𝗶𝗻𝗴 #𝟱: Trajectory-level faithfulness dynamics 🌊 vary with model and estimator. Expressed confidence of later reasoning steps is 🚫 not uniformly more faithful than earlier ones, despite being more calibrated with accuracy.
(3/n) Yet studying FC in LRMs is uniquely hard 🔍. Long CoT traces lack clean step boundaries, exhibit inconsistent step structure, and encode complex conditional dependencies that evolve throughout the trace — making existing FC evaluation methods ill-suited to this setting.
⚠️ 𝗞𝗲𝘆 𝗙𝗶𝗻𝗱𝗶𝗻𝗴 #𝟰: Prompt interventions that boost FC in standard LLMs fail to generalize to LRMs 📉. Even metacognitive prompting — shown in prior work to robustly improve faithful calibration of non-reasoning models — yields minimal gains in the reasoning setting.
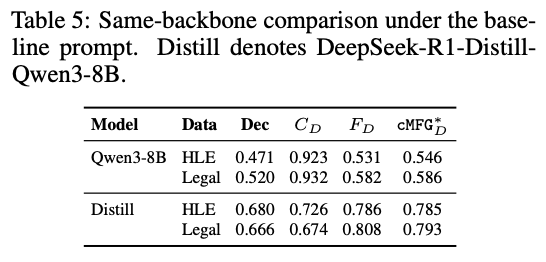
⚠️ 𝗞𝗲𝘆 𝗙𝗶𝗻𝗱𝗶𝗻𝗴 #𝟯: 𝗗𝗶𝘀𝘁𝗶𝗹𝗹𝗮𝘁𝗶𝗼𝗻 differentially reshapes & 𝗱𝗶𝘀𝘁𝗼𝗿𝘁𝘀 FC vs. reasoning training in ways that cannot be inferred from architecture, scale, or accuracy alone — 🎭 distilled models should 𝗻𝗼𝘁 be treated as FC proxies for their teachers!
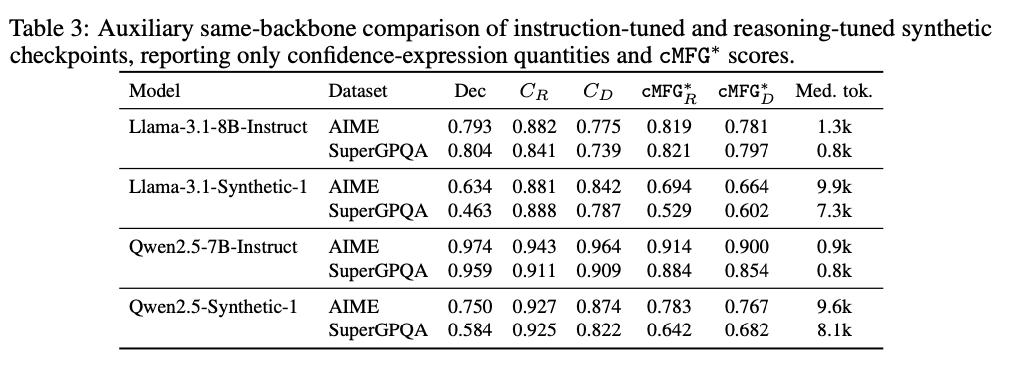
⚠️ 𝗞𝗲𝘆 𝗙𝗶𝗻𝗱𝗶𝗻𝗴 #𝟮: ⚙️ Reasoning training 📉 degrades FC. Comparing matched reasoning & non-reasoning checkpoints of the same model backbone, reasoning-tuned variants produce more hesitation, but surface-level caution does not correspond to lower internal confidence.
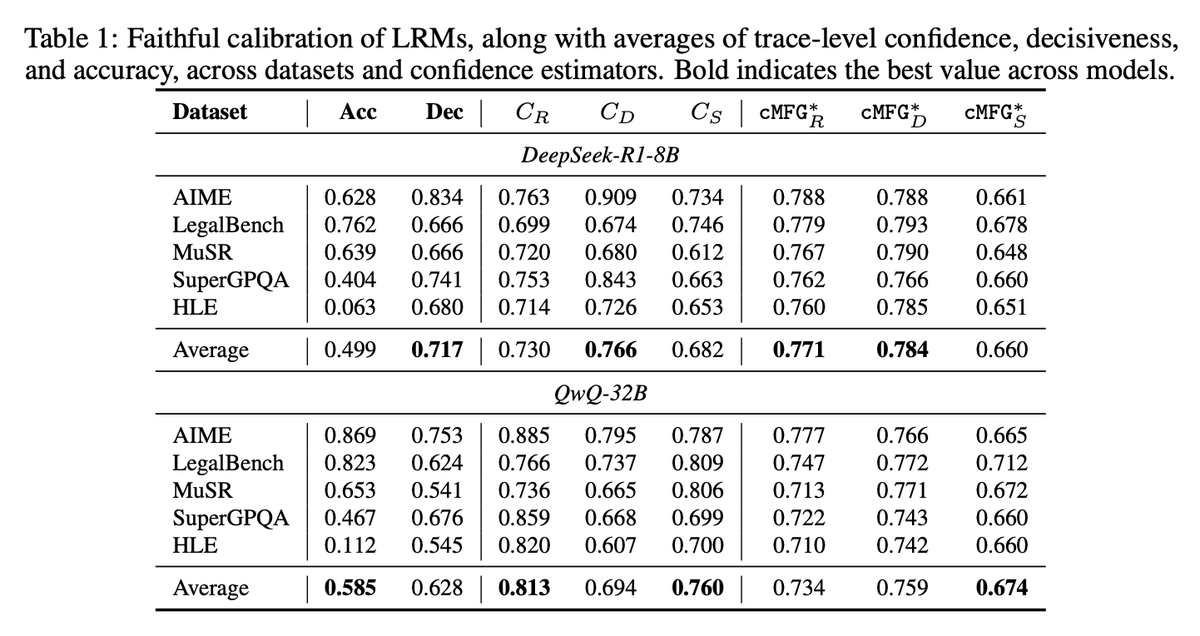
⚠️ 𝗞𝗲𝘆 𝗙𝗶𝗻𝗱𝗶𝗻𝗴 #𝟭: Reasoning behaviors do not automatically translate to improved faithfulness of uncertainty expression. LRMs remain highly decisive even when frequently wrong 😬, and model size provides limited assistance to LRMs, ❌ in contrast to FC of LLMs.
(6/n) We apply our framework across 🤖 7 models, 🧩 5 diverse reasoning-intensive datasets (math, science, law, multi-step soft reasoning), and various 🧪 prompt interventions, finding that faithful confidence expression remains a significant challenge for LRMs 😔.
(5/n) This gives a 🔭 multi-dimensional view of faithfulness throughout a CoT trace. We also introduce a 💡 prefix-conditioned sampling approach to control for conditional dependencies and structure across sampled trace —a key challenge that existing methods overlook.
(4/n) To address this, we present a novel framework to systematically quantify FC in LRMs 🎯. Our framework analyzes linguistic decisiveness against 3️⃣ complementary sources of internal confidence, derived from 🕵 hidden states, ⚙️ token probabilities, & sampling consistency ⚖️.
(2/n) Faithful calibration (FC)—the alignment between models' 𝘪𝘯𝘵𝘳𝘪𝘯𝘴𝘪𝘤 & 𝘦𝘹𝘱𝘳𝘦𝘴𝘴𝘦𝘥 uncertainty—is a persistent failure mode for LLMs 😔. This is especially consequential for LRMs, whose reasoning traces are seen as concrete signals of competence & confidence.