🔥 Meet Hy3 preview: Hy's most intelligent model yet, now open source.
Best-in-class performance at its size. Built to be efficient and usable:
⭐ MoE architecture with fast and slow thinking. 295B total, 21B active, 256K context
⭐ Major improvements in context learning, complex reasoning and conversational abilities
⭐ Tested and integrated within Tencent's core AI products & businesses for better real-world usability
⭐ 40% inference efficiency boost. Best cost efficiency at its size
Hy3 preview is now live on @OpenRouter , free for two weeks. API is also available on Tencent Cloud TokenHub.
Learn more:https://t.co/4RCmFNkjth
Try it now.
👋Hi /haɪ/, we're the Tencent Hy /haɪ/ team🐧
Today, we open source Hy3 preview (295B A21B), a leading reasoning and agent model in its size, with great cost efficiency.
Give us feedback to help improve Hy3 official!
🤗 https://t.co/jc10JODXJ8
📖 https://t.co/VIRoNnwng0
🚀 Introducing Emu3.5 — a large-scale multimodal world model that natively predicts the next vision-language state.
🔥 Trained on over 10T interleaved vision-language tokens and enhanced with reinforcement learning, Emu3.5 achieves powerful multimodal reasoning and generation.
⚡ Powered by our new Discrete Diffusion Adaptation (DiDA) for 20× faster inference.
🔥 Emu3.5 outperforms Nano Banana across image generation, editing, interleaved tasks and more.
🌍 Explore Emu3.5: https://t.co/pWq9wKNXtm
Github: https://t.co/bsjNkwypTa
#Emu3 #MultimodalAI #WorldModel #NextTokenPrediction
With the popularity of large reasoning models (LRMs), BAAI FlagEval team have recently conducted a preliminary contamination-free evaluation using newly collected textual and visual problems in various aspects.
Project homepage: https://t.co/bzzCnpsgPz
Report on arXiv: https://t.co/L1Gjcl3lni
New VLM benchmark (ROME): https://t.co/QzSUacF4Kn
A few of our key findings:🧵
Love the chatbot arena from @lmarena_ai, but as models get more capable, the distinction is fading.
Looking for a tougher challenge for models to compete with each other?
@BAAIBeijing is exploring LLM debates with YOU as the judge! 🤖⚖️ #AI#LLMs
Open Chinese LLM Leaderboard 开放中文大语言模型榜单🏆 from @BAAIBeijing now available on @huggingface hub!
✨ Based on the Eleuther AI Language Model Evaluation Harness
✨ Evaluates on 7 key benchmarks, with all English datasets translated to Chinese
https://t.co/LfV4ZFgq8S
🚀Exciting News! We've launched the Open Chinese LLM Leaderboard in collaboration with @huggingface! This initiative aims to track, rank, and evaluate open-source Chinese language models through community contributions.
Discover more: https://t.co/DUEO8yr58N
🚀 Great news! In partnership with leading institutions, BAAI has unveiled the CCI, a comprehensive Chinese Internet Corpus. This data open-source project is designed to offer a dependable data foundation for AI and big data with Chinese. Find details https://t.co/3k5cVVAwOm
🚀 Excited to introduce #Wudao Aquila2-34B, establishing itself as one of the best open-source Chinese-English LLM, with superior comprehensive and reasoning capability
🔗 https://t.co/MuzpIe5J3H
🤗https://t.co/ASWVksySaF
@jeremyphoward@AdeenaY8 Thanks for your interest in our work.
Which model are you referring to? base model or the sft model?
If it's sft, The HELM evaluation method leads to lower performance.
Also, given that the model parameters are at the level of 7B or 34B, it's lower compared to larger models.
We released a Dreambooth @Gradio Web UI for our AltDiffusion-m9 model (a multilingual text-to-image generation model) on @huggingface Spaces.For details of AltDiffusion, see our previous post:https://t.co/3QdJLQUFfb
Try out the Naruto or Wukong model -> https://t.co/3j8GuyclRZ
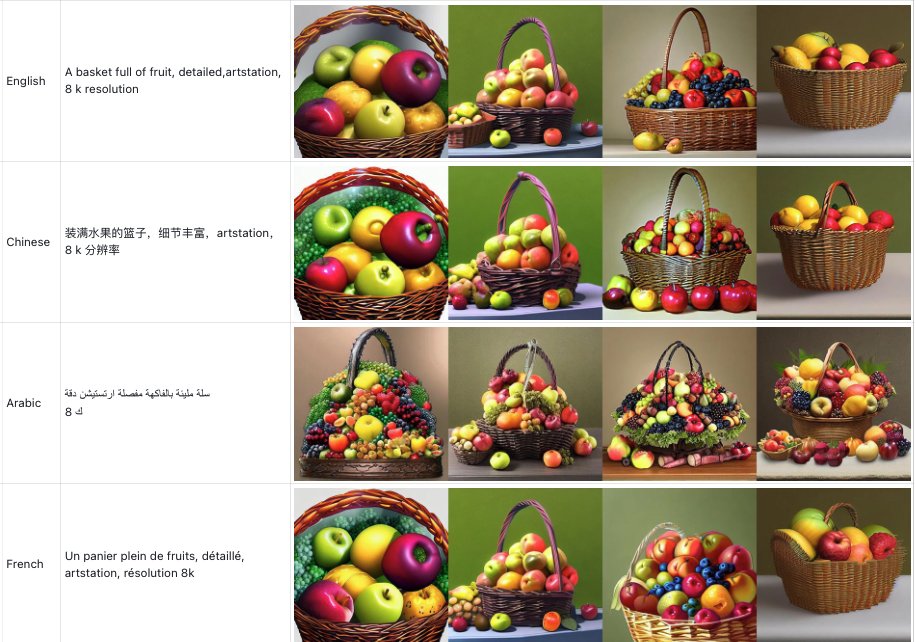
Introducing AltDiffusion, a multilingual text-image generation model built on @StableDiffusion.
Currently supports English, Chinese, Spanish, French, Japanese, Korean, Arabic, Russian and Italian:
https://t.co/EjhXISuJQu
@HuggingFace Model: https://t.co/nMKJUEVZ99