This was a great collaboration with @ShuangqiLi, @ MathieuSalzmann, @pafrossard 🙌
💻 Code: https://t.co/eht4nNiXng
📖 Paper: https://t.co/jBG9HpxzJt
📜 9/9
SFT's token-by-token imitation can overfit to fixed demonstrations 📑, raising a key question: should every token be trusted equally?
We introduce PriFT ✏️, an SFT framework using a frozen pretrained model 🧊 to guide token reweighting and align SFT with prior knowledge.
📜 1/9
If you’re interested in weight interpolation / extrapolation, A few great related reads that inspire me:
• Rewarded Soups: https://t.co/dXAlncR6b5
• ExPO / Model Extrapolation: https://t.co/NjHUs8rpLq
• AlphaRL: https://t.co/9XF5UeANx5
I learnt a lot from these works!
Attending #ICML2026 in Seoul? 🇰🇷🤔
If it’s your first time in Korea, I’ve put together a (personal) mini-guide to help you navigate and make the most of your trip! 🗺️✨
Check it out here: https://t.co/IGWFOkhyLN 💗:)
Okay, even more interesting : DiffusionGemma is a “loopholed” diffusion model!
Discrete diffusion usually hits the sampling wall:
the model has a rich distribution over tokens, then at each step, sampling crushes it into one hard token.
A lot of previously computed belief disappears. But DiffusionGemma keeps the previous logits alive.
So it denoises from the token AND from the belief behind the token.
That’s the idea behind « Loopholed Discrete Diffusion», a paper I was playing with this week. Exciting to see this at scale !
Binder design has come of age thanks to generative models—but how can we access the wider array of dynamic, multistate protein functions, so elegantly employed by nature?
@mihirbafna14 and I are excited to share SwitchCraft, a framework for designing such functions. (1/7)
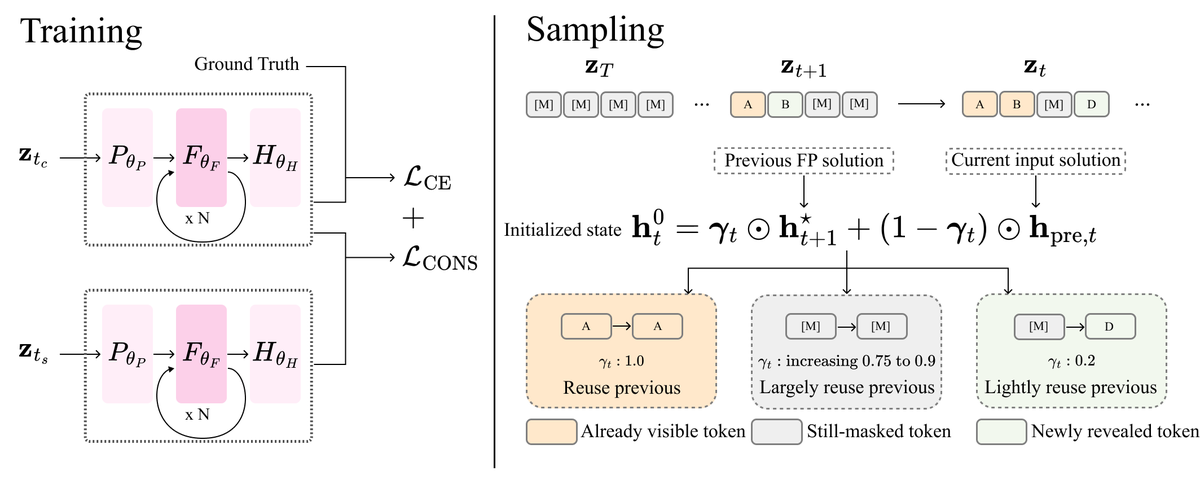
Welcome to check CoFRe - a complete training-to-inference framework for fixed point masked generation !
Improved quality v.s. cost tradeoff for both text and visual data.
Amazing work leaded by @andreamiele_
🔥 New paper: Fixed-Point Masked Generative Modeling
Masked generative models are becoming a very exciting alternative to autoregressive generation, especially for language.
They decode in parallel, but every denoising step still runs a full bidirectional Transformer.
We make them cheaper and stronger with fixed-point denoisers 🧵
w/ @qinym710@AlbaCbCs@jdeschena and @pafrossard
(1/12)
Looking forward to this workshop on ML4molecules at the ELLIS unconference (followed by EurIPS). Please submit your abstracts! The deadline will be extended to 15 October 2025.
Bit late for the announcements but very happy to share that MEMOIR is accepted to Neurips 2025🎉! Great collaboration with @qinym710@nikdimitriadis, @alesfav, @pafrossard! See you in San diego!
🎉 Thrilled to share: our paper FANTOM with Prof. @pafrossard, Flow-based approach for Dynamic Temporal Causal models with non-Gaussian or Heteroscedastic Noises, has been accepted at NeurIPS 2025! (1/6)
🚀 Presenting #DeFoG: our discrete flow‑matching framework for graph generation! Catch our #ICML2025 oral presentation today (3:30 – 3:45 PM, in West Exhibition Hall C) and drop by the poster right after (4:30 –7:00).
Come chat graphs & generative models! @manuelmlmadeira
🚨Preprint alert!🚨 Did you know there is a new reasoning benchmark where leading models like o3 still fall flat?
(i.e. 0% accuracy or random perf. on hard sub-tasks)
✨Meet 𝐌𝐀𝐑𝐁𝐋𝐄, a 🪨-hard benchmark for multimodal reasoning and planning under complex spatial constraints!✨
Inspired by well-known challenges such as the ARC challenge, we thought:
𝘊𝘢𝘯 𝘸𝘦 𝘥𝘦𝘷𝘪𝘴𝘦 𝘢 𝘯𝘦𝘸 𝘤𝘩𝘢𝘭𝘭𝘦𝘯𝘨𝘪𝘯𝘨 𝘣𝘦𝘯𝘤𝘩𝘮𝘢𝘳𝘬 𝘧𝘰𝘳 𝘔𝘓𝘓𝘔𝘴 𝘵𝘰 𝘱𝘶𝘵 𝘵𝘩𝘦𝘪𝘳 𝘢𝘣𝘪𝘭𝘪𝘵𝘺 𝘵𝘰 𝘳𝘦𝘢𝘴𝘰𝘯 𝘢𝘯𝘥 𝘮𝘶𝘭���𝘪-𝘴𝘵𝘦𝘱 𝘱𝘭𝘢𝘯𝘯𝘪𝘯𝘨 𝘵𝘩𝘳𝘰𝘶𝘨𝘩 𝘤𝘰𝘮𝘱𝘭𝘦𝘹 𝘮𝘶𝘭𝘵𝘪𝘮𝘰𝘥𝘢𝘭 𝘱𝘳𝘰𝘣𝘭𝘦𝘮𝘴 𝘵𝘰 𝘵𝘩𝘦 𝘵𝘦𝘴𝘵?
Turns out this is still super hard even for latest models!
MARBLE offers 2000+ multimodal-reasoning problems split into two domains:
𝐌-𝐏𝐨𝐫𝐭𝐚𝐥: multi-step spatial-planning puzzles modelled on levels from Portal 2.
𝐌-𝐂𝐮𝐛𝐞 : here, models need to plan 3D cube assemblies from jigsaw pieces, inspired by Happy Cube puzzles.
MARBLE provides a tough benchmark for testing advanced reasoning in MLLMs. For these tasks, the genie is out of the bottle now—expect to see rapid improvements in model performance over the coming months, so let's not over-interpret them by that time!
🌐 Website: https://t.co/N1cIXQFm0g
📄 Paper: https://t.co/Yc6YBgjE8f
💻 Code: https://t.co/UYnh0xDOyW
🤗 Dataset: https://t.co/XJsjKDtfzc
Fun collab with @YulunJiang @ychai1224 @mariabrbic!
🧬 New roadmap out in Nature Reviews Molecular Cell Biology!
🤖 We show how RNA-LMs + GNNs can come together to model the RNA interactome & uncover new roles for non-coding RNA.
💊 Clinical links to RNA therapies for cancer & neuro diseases.
📄 Read it: https://t.co/JICDv1LRd9
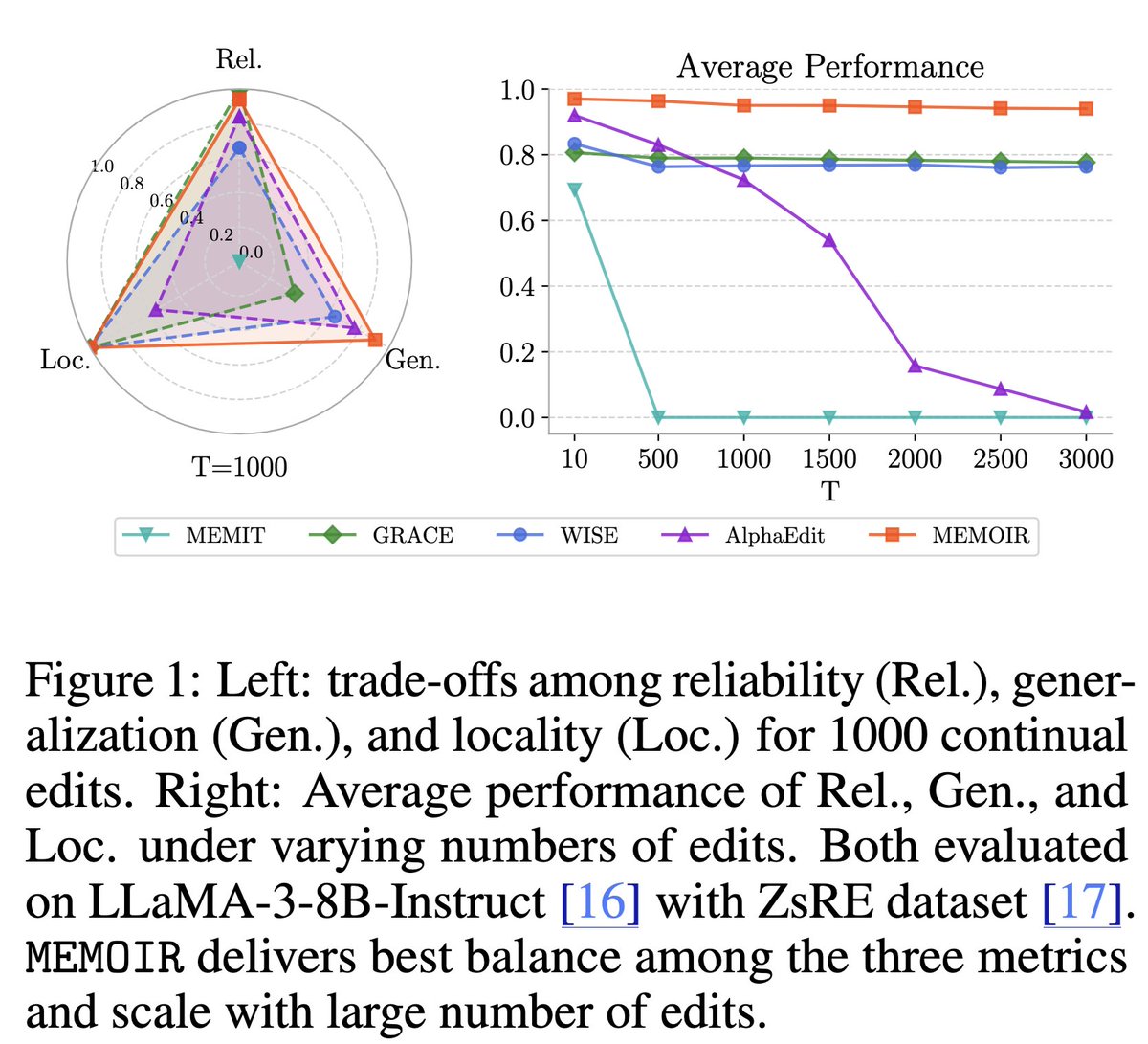
@boknilev While we do not have the results of editing MEMIT with all 3000 facts at once, prior work (WISE) evaluated MEMIT with batch sizes up to 100, and even then, the performance was still suboptimal when the total number of edits equals to 100.
How can we inject new knowledge into LLMs without full retraining, forgetting, or breaking past edits?
We introduce MEMOIR 📖— a scalable framework for lifelong model editing that reliably rewrites thousands of facts sequentially using a residual memory module. 🔥
🧵1/7
@boknilev Thanks for your interest! Yes, the plot shows sequential edits. We follow the lifelong model editing setting, where each edit is applied immediately upon arrival. This reflects a more practical scenario than batching and editing multiple facts at once.