Vision-language AI models have a gaze. And you can steer it! 👀
Redirect just 9% of a model’s attention heads to any region in an image, and the VLM will start describing that region mid-generation. We call them Gaze Heads!
Try the demo: https://t.co/y5jlb0iBI8 🧵👇
A new way to do off-policy RL with diffusion: if we have off-policy data, we need to figure out what the diffusion latent steps for it would be with our *current* policy (not the one that collected it), so this requires reversing the diffusion process on off-policy data.
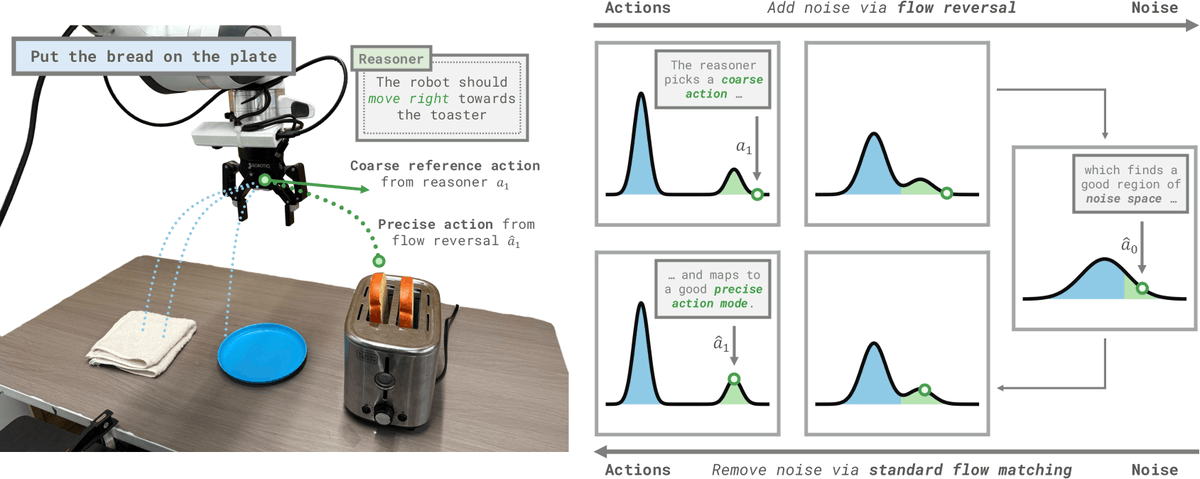
Cool work on refining coarse VLM actions using a flow matching policy π(a₀ | o) → a₁ where a₀ ∼ N(0, 1) by first reversing (inverting) the given coarse action a₁ via â₀ = π⁻¹(a₁ | o) and then reconstructing it in the forward direction i.e. â₁ = π(â₀ | o).
The interesting bit is that this method crucially **relies** on Euler integration error! If you use a vanishingly small integration step size (which is usually supposed to be a good, albeit expensive, thing), there is no refinement i.e. â₁ = a₁!
Generalist robot policies learn many useful skills. How can we elicit relevant behaviors when faced with new tasks? We introduce Flow Reversal Steering (FRS): a way to refine coarse actions produced by semantic reasoning into similar precise ones!
https://t.co/BRdvq0OVg0
1/N
How does test-time scaling impact robots?
We find that larger models, more thinking, and more context help significantly for some prompts but not others.
Like LLMs, we can also train a router to for a better performance/latency tradeoff!
Paper: https://t.co/HEjjCkrsen
The videos from the “Frontiers of Embodied AI” meetup at ETHZ from a few weeks back are now available.
Speakers: Jitendra Malik, Vladlen Koltun, Yann LeCun, and Shuran Song
Hosted by Marc Pollefeys
YouTube playlist: https://t.co/IfU9owsa1o
RTC is a key ingredient for deploying high-latency VLA policies in real-time. We show that discrete diffusion is a more natural fit for asynchronous execution: with no extra implementation or specialized fine-tuning, it achieve strong performance on dynamic manipulation tasks!
Diffusion (or flow) makes for excellent policies, but training them with RL is notoriously hard: BPTT is unstable, RL over diffusion blows up the horizon. In our new paper, we show how we can optimize flow matching actors by using "one weird trick" -- "approximate" the Jacobian of the flow denoising process with the identity matrix. 👇
Appreciate Jitendra's takes on world models/VLMs. His word below is why back in 2019-2021, instead of VLAs for simple pick-and-place, we chose assembly.
Dexterity = mutual info between your intent and forces/torques on objects via contacts.
I've always been impressed by how Diffusion policies and VLAs do contact-rich tasks without force sensing.
Today I'll try to Demystify VLA Performance in Contact-Rich Tasks and How to Fix Them.
15:30 at the Act to Sense to Act Better Workshop, Hall C4, #ICRA2026
My favourite thing at #ICRA26? The workshops.
Because you learn what everyone has been up to.
In that spirit, I will talk about our new Dexterous Manipulation work at the workshop on Dexterity with Multifingered Hands: 13:55-14:20, Stolz 2.
Here is a teaser (video plays at 1x)
Introducing τ0-WM: the largest-scale pre-trained embodied world model to date. At 5B parameters, it diverges from standard models that directly map observations to actions. Instead, τ0-WM unifies policy and world modeling into a single robotic foundation framework.
🚀 Excited to share REST3D: REconstructing physically STable and visually consistent 3D scenes from a casual single image🤳.
With REST3D, you can naturally interact with stable virtual objects through hand-based VR interactions👐.
🔗 Project page: https://t.co/1CVuGIjAVM
Six arms instead of two! 🤯
Midea Group humanoid robot has six arms instead of two.
It handles heavy components with lower limbs and performs fine assembly work with upper limbs. Full 360-degree rotation, stable vertical lifting, rapid tool-swapping.
The robot handles workstation transitions that would typically require multiple human workers or separate machines.
So no idle-time between stations. Pretty cool.
But I'm really curious about the cost, and how this 6-arms robot compares to a regular robot arm, and then to a regular humanoid
What do yo think? Overcomplicated?
~~
♻️ Join the weekly robotics newsletter, and never miss any news → https://t.co/GoA3ZuwoPB
AI needs vastly more data than we do. One idea might close the gap: don't predict raw signals (tokens), predict your own abstract latent representation (JEPA, data2vec).
With @DanKorchinski@MatthieuWyart, on a toy model, we prove how much that helps: the gap is exponential.
🧵
new in-depth blog post time: Inside the Transformer: The Life of a Token
a deep dive into a modern dense transformer, i cover YaRN (why does pairwise coordinate rotation induce positional information?), hybrid attention (getting to 160k context length), soft capping, QK normalization, etc. as the token flows through the transformer
bonus transformer math: FLOPs/token formula (and when is 6N formula broken), cluster sizing (how big of a cluster do you need given the model/data size and experiment throughput of interest), and more