🔥 LabVLA: Bringing AI from reading experiments to actually performing them in wet labs
AI systems today can read papers, write code, and even design experiments ���
but they still stop at the edge of the physical lab.
Can we move from AI that understands science
to AI that executes science?
We introduce LabVLA, a vision-language-action system for real laboratory execution.
🧪 RoboGenesis
A large-scale data generation engine that converts visual inputs into structured lab assets, composing 100K+ diverse lab environments across 16+ robotic embodiments (single-arm, dual-arm, mobile manipulation).
📦 LabEmbodied-Data
A large-scale dataset of multi-view, structured demonstrations for robust scientific manipulation learning.
🤖 LabVLA
A VLA system trained with fast action-token pretraining, flow-matching post-training, and knowledge-insulated representation learning to enable stable multimodal alignment.
📊 Results
LabVLA achieves state-of-the-art performance on LabUtopia, and demonstrates strong sim-to-real transfer on a Franka robotic platform.
This model is currently only an exploratory research prototype and still has many limitations.
We will gradually open-source the data and the synthetic data engine, and hope that they will be valuable to the community and help advance progress in this direction.
Home: https://t.co/H4ioK7GDUf
Paper: https://t.co/eOTrz8wRsg
Code: https://t.co/iHhVyKUW5A
#EmbodiedAI #Robotics #AI4Science #VLA #MachineLearning #LLM #NLP
🚀 Excited to share our latest progress on scientific idea evaluation!
As LLMs and AI Scientists generate research ideas at scale, a key bottleneck emerges: how do we know which ideas are truly novel, valid, feasible, and impactful?
Our ICML 2026 paper, InnoEval, frames idea evaluation as a knowledge-grounded, multi-perspective reasoning problem, going beyond simple LLM-as-a-Judge with:
🔎 heterogeneous deep knowledge search
👥 an innovation review board with diverse academic personas
📊 multi-dimensional evaluation across clarity, novelty, feasibility, validity, and significance
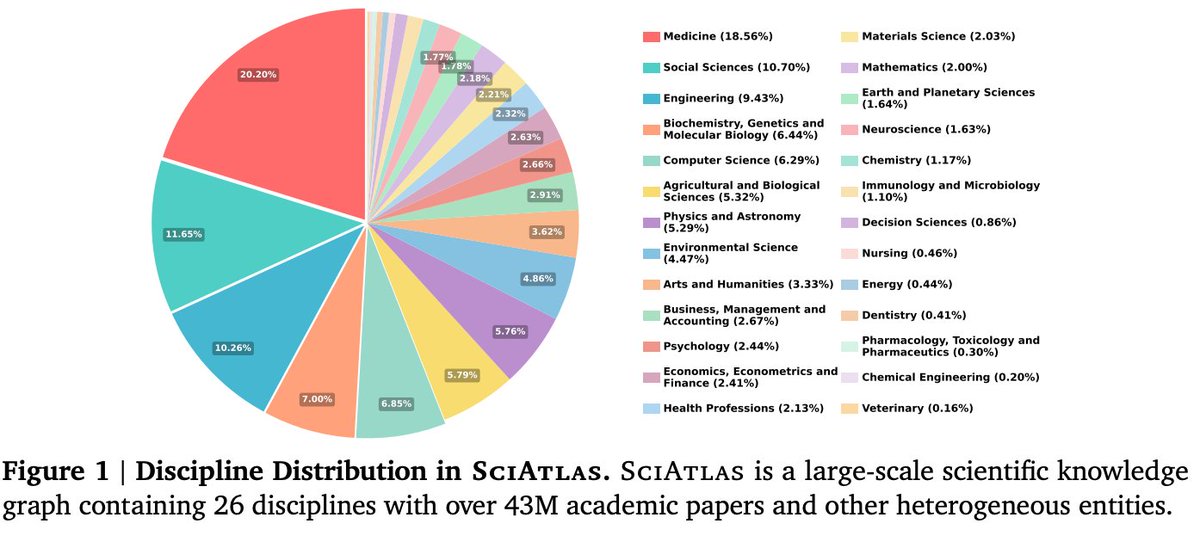
We further extend this direction with SciAtlas: a large-scale scientific knowledge graph covering 26 disciplines, 43M+ papers, 157M entities, and 3B triples.
🧭 More importantly, SciAtlas is packaged into Agent Skills, enabling research agents to directly call structured scientific knowledge for:
📚 paper search & literature review
🧩 idea grounding & similarity analysis
⚖️ evidence-grounded idea evaluation
💡 idea generation from retrieved papers
📈 research trend synthesis
👤 researcher profile analysis
Our goal: AI systems that do not only generate ideas, but can also locate, challenge, evaluate, and improve them with grounded scientific evidence. #SciAtlas #KG #AIScientist #Agent #AI4Research
📄 InnoEval: https://t.co/ndeO4gBOsn
📄 SciAtlas: https://t.co/q7HGylES7K
🔗 Repo: https://t.co/ropfrCZunu
Can AI agents reliably automate scientific data analysis? 🔬
Outcome-only supervision may reward a correct-looking answer while missing flawed intermediate logic.
In science, plausible conclusions are not enough—the analysis process must be grounded and verifiable.
We introduce DataPRM 🚀: an environment-aware process reward model for agentic data analysis.
🔗 Code: https://t.co/qxiAEhgUML
📄 Paper: https://t.co/titNJNbzC3
Instead of only judging final answers, DataPRM provides step-level supervision for data analysis trajectories.
Why do existing PRMs struggle here?
🤫 Silent errors: code runs successfully, but the logic is wrong.
🛑 Grounding errors: agents must explore messy datasets—e.g., inspect schemas or try column names—but static PRMs often penalize this necessary trial-and-error.
The Solution: DataPRM
🌍 Active environment verification: it can interact with the environment—running code and inspecting data/documents/images—to probe intermediate states and catch silent errors.
⚖️ Reflection-aware ternary rewards: DataPRM assigns {0, 0.5, 1} rewards. This distinguishes irrecoverable mistakes from correctable exploratory steps, allowing agents to adapt instead of being prematurely penalized.
Results:
Constructed a scalable pipeline yielding 8K+ high-quality training instances via diversity-driven trajectory generation and knowledge-augmented step-level annotation.
✨ Massive Efficiency: Despite having only 4B parameters, DataPRM outperforms strong PRM/self-rewarding baselines while being far more parameter-efficient.
✨ Test-Time Scaling (TTS): Improves downstream policy LLMs by +7.21% on ScienceAgentBench and +11.28% on DABStep.
✨ Agentic RL: Integrating DataPRM into Reinforcement Learning (GRPO) achieves 78.73% on DABench and 64.84% on TableBench, outperforming outcome-only reward baselines and reducing reward hacking / entropy collapse.
Takeaway:
For scientific data analysis, we should not only ask whether the final answer looks right.
We should verify whether every key step is grounded in the actual environment.
DataPRM is a step toward reliable, process-supervised scientific discovery.
What if your AI could think like an expert — knowing exactly what to remember, what to look up, and what to let go? 🤔
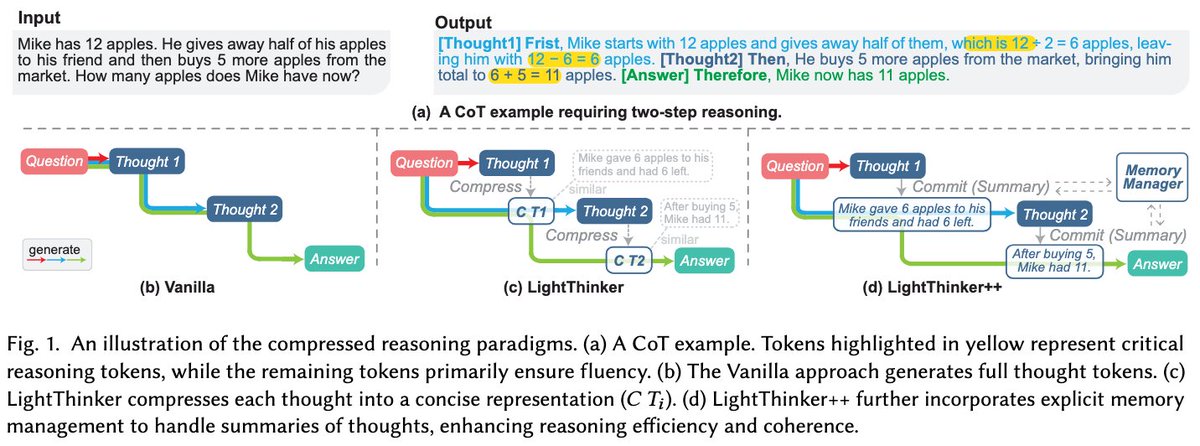
🚀 Introducing LightThinker++ — the next evolution of LightThinker, pushing beyond reasoning compression into adaptive memory management.
Instead of just thinking efficiently, LightThinker++ learns what deserves to be remembered, retrieved, or forgotten — enabling more scalable long-horizon reasoning. #AI #LLM #Agents #Memory #Reasoning #LightThinker #EfficientAI
📖 Paper: https://t.co/tf4i8MR6tf
⌨️ Code (will be released soon): https://t.co/35jdP0981t
🔍 Why We Need to Go Beyond Compression
Our original LightThinker achieved efficiency by compressing intermediate thoughts into compact representations.
But purely implicit compression has a fundamental limitation: once a thought is compressed, critical details are gone forever.
We observed that existing works focus on summarizing and archiving past reasoning steps — but overlook a crucial capability: the ability to look back.
🧠 Our Solution: Explicit Adaptive Memory Management
We introduce three core operations that give LLMs explicit control over their reasoning memory:
📥 Commit — archive a reasoning step as a compact summary
🔍 Expand — look back at any past step to reuse details and verify previous reasoning
📁 Fold — collapse it back to maintain a clean, high-signal context
We also provide an in-depth comparison between LightThinker and LightThinker++, analyzing the trade-offs between implicit compression and explicit memory management across different reasoning scenarios.
🔭 Looking Forward
Just as human experts don't memorize every word but know exactly what to recall and when, we take a step toward empowering LLMs with the same cognitive economy — archiving what's done, retrieving what's needed, and keeping the reasoning context lean, focused, and always in control. 🎉
🚀 Excited to share SkillX: Automatically Constructing Skill Knowledge Bases for Agents!
It automatically converts agent trajectories into reusable, plug-and-play skills — making them transferable across agents and environments.
We are also planning to integrate SkillX into the SkillNet series, aiming to build a unified and scalable ecosystem for skill-centric agent intelligence. #LLM #Agents #NLP #AI #Skills #SkillX
📖 Paper: https://t.co/igesJv5WXb
🔗 Code: https://t.co/bo9EsgoDlV
🧩 Motivation
LLM agents should learn from experience, but today, most self-evolving agents still learn in isolation.
They repeatedly rediscover similar behaviors from limited data, leading to:
🔹 redundant exploration
🔹 weak generalization
🔹 capability bottlenecks tied to the base model
So the key question is:
What form of experience is actually reusable across agents and environments?
💡 Our answer: Skills! But structured hierarchically!
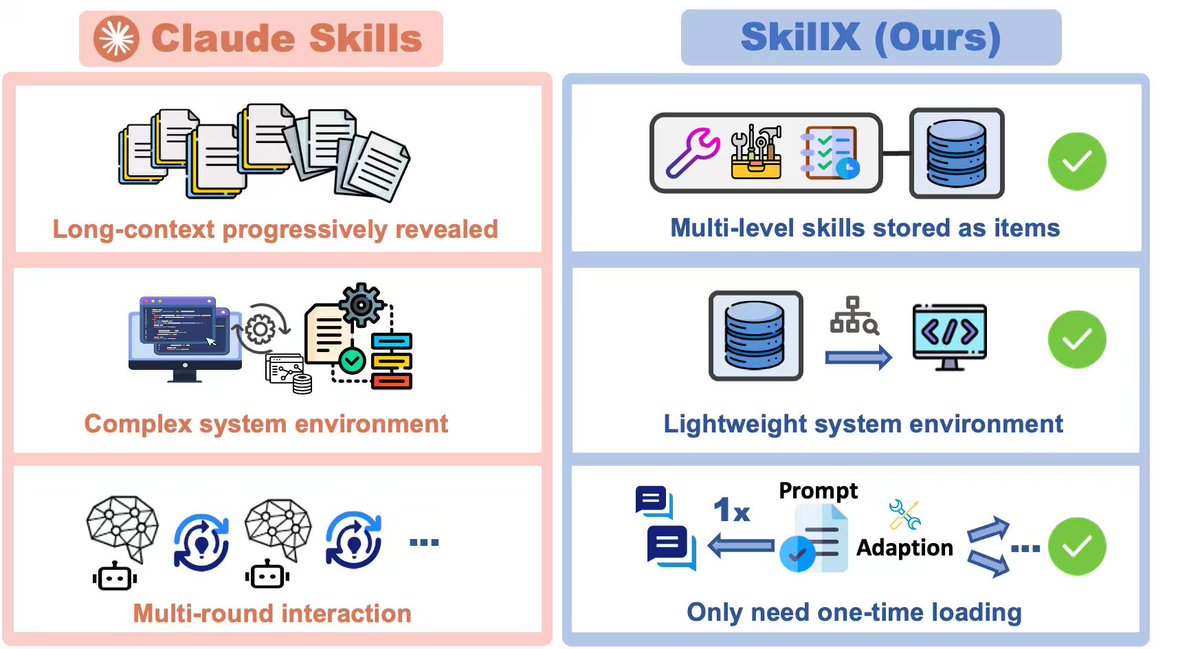
We propose SkillX, an automated framework for building a reusable Skill Knowledge Base (SkillKB).
Instead of storing raw trajectories, insights, or workflows alone, SkillX organizes experience into 3 levels of skills:
1️⃣ Planning Skills
High-level task organization: ordering, decomposition, dependencies
2️⃣ Functional Skills
Reusable tool-based subroutines for completing subtasks
3️⃣ Atomic Skills
Low-level tool usage patterns, constraints, and failure-prone details
This makes agent experience more compact, composable, and transferable.
⚙️ How SkillX works
SkillX constructs the skill library through 3 synergistic components:
1. Multi-Level Skills Design
2. Iterative Skills Refinement
3. Exploratory Skills Expansion
🔍 Why is this useful?
Unlike long-context skill formats that require complex sandboxing and progressive interaction, SkillX uses a lightweight, itemized representation:
✅ retrieve with a simple retriever
✅ inject once into the system prompt
✅ easier transfer across base models
✅ lower execution burden for weaker agents
📊 Results
Using GLM-4.6 to automatically build the skill library, we evaluate transfer on challenging long-horizon interactive benchmarks:
● AppWorld
● BFCL-v3
● τ2-Bench
When plugged into weaker base agents like Qwen3-32B, SkillX brings ~10 point improvements and also improves execution efficiency. ⚡
🧠 Key takeaway
● Not all “experience” transfers equally well, and the representation matters.
● Hierarchical skills are a powerful abstraction for turning isolated agent experience into reusable knowledge.
● Stronger agents can build the skills, weaker agents can reuse them, and agents no longer need to keep learning everything from scratch.
✨ Additional findings
● Functional skills contribute the most to performance gains
● Planning skills often reduce execution steps
● Atomic skills are crucial for clarifying tool constraints and common failure modes
● Iterative refinement further improves the skill library
● Experience-guided expansion discovers more novel skills than random exploration
📦 We will release the optimized plug-and-play skill library to facilitate future research on reusable agent skills.
Feedback, discussions, and collaborations are very welcome! 💬
Excited to announce our first workshop on AgentSearch! 🙌 I will serve as a small Program Committee member.🤣 Welcome to submit your papers to us! Looking forward to seeing you in Melbourne in July!✈️
🚀 AgentSearch Workshop @ ACM SIGIR ’26
We’re excited to announce AgentSearch: The First Workshop on Indexing, Retrieval, and Ranking of AI Agents, co-located with ACM SIGIR 2026 (Melbourne | Naarm, Australia).
As AI agents rapidly proliferate, how can users, developers, and multi-agent systems reliably identify and select the "right" agents or tools for a given task?
🌐 https://t.co/nquvibmVK9
🐦 @AgentSearchIR
🦋 https://t.co/n1F1aFUaKQ
Organizers:
Bin Wu @binwu_cs (University College London),
To Eun Kim @TEKnologyy (Carnegie Mellon University),
Yue Feng @YueFeng__ (University of Birmingham),
Fernando Diaz @841io (Carnegie Mellon University),
Zhaochun Ren @zhaochun_ren (Leiden University),
Emine Yilmaz @emine_yilm (University College London & Amazon)
#SIGIR #SIGIR2026 #InformationRetrieval #AIAgents #MultiAgents #AgentSearch
🚀 AgentSearch Workshop @ ACM SIGIR ’26
We’re excited to announce AgentSearch: The First Workshop on Indexing, Retrieval, and Ranking of AI Agents, co-located with ACM SIGIR 2026 (Melbourne | Naarm, Australia).
As AI agents rapidly proliferate, how can users, developers, and multi-agent systems reliably identify and select the "right" agents or tools for a given task?
🌐 https://t.co/nquvibmVK9
🐦 @AgentSearchIR
🦋 https://t.co/n1F1aFUaKQ
Organizers:
Bin Wu @binwu_cs (University College London),
To Eun Kim @TEKnologyy (Carnegie Mellon University),
Yue Feng @YueFeng__ (University of Birmingham),
Fernando Diaz @841io (Carnegie Mellon University),
Zhaochun Ren @zhaochun_ren (Leiden University),
Emine Yilmaz @emine_yilm (University College London & Amazon)
#SIGIR #SIGIR2026 #InformationRetrieval #AIAgents #MultiAgents #AgentSearch
🧵 InnoEval: Can AI Evaluate Research Ideas Like Human Experts?
Excited to share our newest work on automating scientific idea evaluation! As LLMs generate research ideas at unprecedented scale, we face a critical bottleneck: who evaluates these ideas?
📄 Paper:https://t.co/P1vyCnxSJ7
💻 Code: https://t.co/BfDv8mUYsc
🎮 Demo: https://t.co/BeqkaBH1xZ (You’ll need to register first to try the demo.)
The Challenge
Current "LLM-as-a-Judge" approaches suffer from narrow knowledge horizons, flattened evaluation dimensions, and inherent bias.
Scientific evaluation demands knowledgeable grounding, collective deliberation, and multi-criteria decision-making—none of which existing methods adequately address.
Our Solution: InnoEval
We frame idea evaluation as a knowledge-grounded, multi-perspective reasoning problem:
🔍 Heterogeneous Deep Knowledge Search → retrieves living knowledge from papers, web, and code repos
👥 Innovation Review Board → simulates diverse academic personas for consensus
📊 Multi-dimensional Decoupled Evaluation → assesses Clarity, Novelty, Feasibility, Validity, and Significance independently
Key Results
✅ +16.18% F1 on point-wise evaluation vs. strongest baseline
✅ +5% accuracy on pairwise comparison, +7.56% on group-wise ranking
✅ >70% win rate in overall quality against all baselines High correlation with human expert judgments across all dimensions
Why It Matters
InnoEval doesn't just predict accept/reject—it generates actionable evaluation reports with evidence-backed analysis and concrete revision suggestions, emulating the full scholarly review process.
#MachineLearning #AI4Science #LLM #PeerReview #ResearchEvaluation
AI systems repeatedly reinvent the same domain know-how—buried in prompts, tools, and brittle pipelines.
Skills remain fragmented, duplicated, and inconsistent in quality.
We believe the missing layer in the AI stack is skills as infrastructure.
We are pleased to introduce SkillNet, an ongoing project to build an open infrastructure for creating, evaluating, and organizing executable AI skills at scale.
Homepage: https://t.co/D4PkIlTbRA
Code: https://t.co/2Zej4VL7Rk
SkillNet is not a skill repository.
It is infrastructure to standardize how skills are built, evaluated, and interconnected across domains.
With SkillNet:
→ Skills become reusable, composable assets
→ Agents gain reliable, evaluated capabilities
→ Workflows become modular and interoperable
→ Knowledge becomes infrastructure
Each SkillNet skill undergoes explicit evaluation across safety, completeness, executability, maintainability, and cost.
This infrastructure may enable composable scientific and enterprise workflows.
We gratefully acknowledge the open-source community for sharing numerous projects and skills that inspired this work.
We have built an initial prototype demonstrating:
• Autonomous Scientific Discovery
• Autonomous Coding Agents
The system is still experimental and not yet production-ready.
An initial Python library supporting skill search, download, creation, evaluation, and analysis is available:
pip install skillnet-ai
Technical report coming soon.
#SkillNet #Skills #Agents #LLMs #NLP
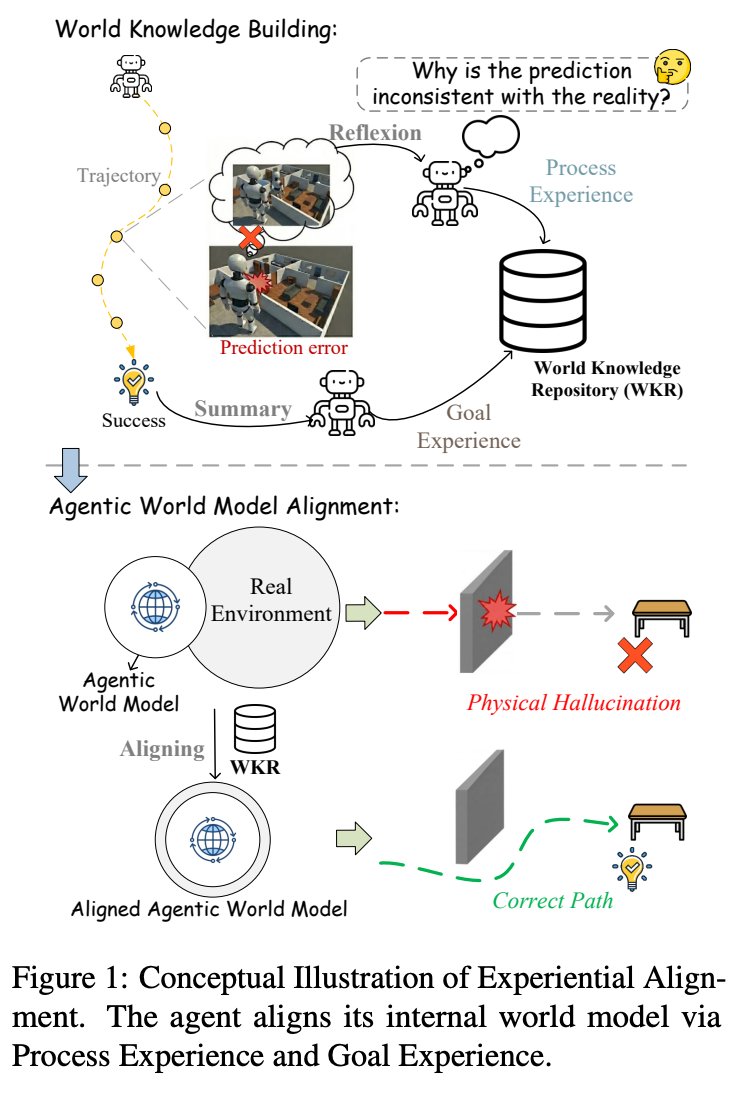
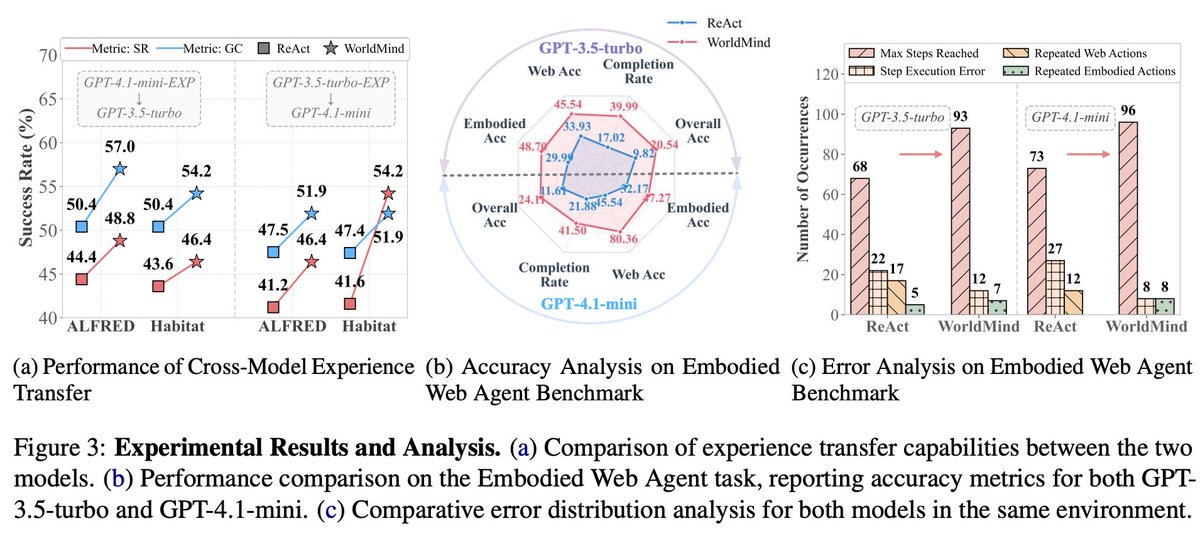
Do we REALLY need an external world model? 🤔
Standard approaches often rely on heavy external simulators.
We agree with the view: The Agent itself is the World Model.
🌍 How to align agentic world models via experience learning?
We are excited to introduce our new work: "Aligning Agentic World Models via Knowledgeable Experience Learning"(WorldMind)🚀
🚧The Problem: LLMs possess vast semantic knowledge but lack physical grounding.
→ Ask for a plan: It sounds logical.
→ Execute it: It fails physically (e.g., trying to slice without a knife). 😵💫
The agent knows *what* to do, but not *how* physical laws constrain it.
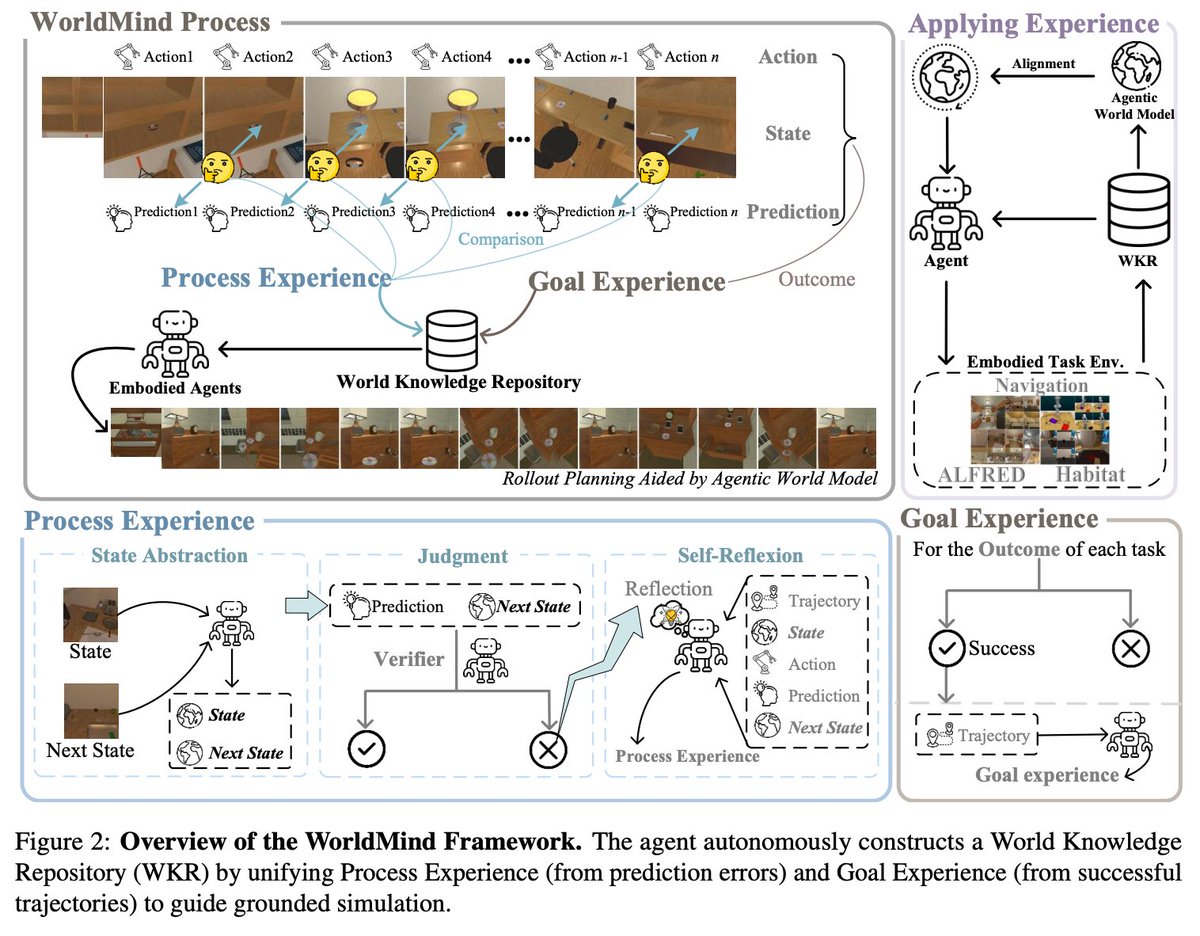
💡The Solution: WorldMind
We bridge the gap between high-level reasoning and physical reality through:
🌍 Agentic World Model: Instead of external engines, we activate the agent's internal ability to simulate environmental dynamics to guide planning.
🔹 Online Experience Learning: Eliminates the need for costly fine-tuning or retraining.
🔹 Alignment via World Knowledge: Autonomously builds a World Knowledge Repository (WKR) to ground the agent.
This unifies:
• Process Experience: Learning from step-level prediction failures ���
• Goal Experience: Distilling shortcuts from successful trajectories ✅
🚀 Key Features:
✅ Training-Free: Aligns agents via online experience learning.
✨ Superior Performance: improvements on EB-ALFRED & EB-Habitat.
🔗 Project Page: https://t.co/IZjHvHirZH
📄 Paper: https://t.co/YIKwSiNHIH
Our current method is limited by today’s foundation models and cannot yet support reliable long-horizon planning.
Looking ahead, as model capacity and memory modules continue to improve, we believe agents will gradually internalize world models and achieve robust long-term embodied decision-making.
#EmbodiedAI #MultimodalAgent #ExperienceLearning #Alignment #WorldModels #LLM #Robotics #AgenticAI #NLP #WorldMind
Introducing our latest work, LightMem: Lightweight and Efficient Memory-Augmented Generation 🚀.
A memory system that cuts cost while preserving (and often improving) long-horizon reasoning for LLM agents. #NLP#LLMs#Memory#LightMem#Agents
📖 Paper: https://t.co/I9EjkePBYI
🔗 Code: https://t.co/MlyaxqfHAw
🧩 Motivation: LLMs struggle in long, multi-turn interactions — context gets noisy, expensive, and models get “lost in the middle.”
Existing memory systems are often accurate but heavy on tokens, API calls, and latency. ⚠️
💡 Solution Overview: LightMem is inspired by human memory and uses a three-stage lightweight pipeline to keep memories compact, topical, and consistent:
1️⃣ Pre-compressing Sensory Memory — remove redundant/low-value tokens before further processing.
2️⃣ Topic-aware Short-Term Memory — group turns by topic and summarize to form precise memory units.
3️⃣ Sleep-time Long-Term Updates + Soft Updates — do only incremental inserts at test time and run high-fidelity consolidation offline to avoid runtime latency.
🔬 Results: On LONGMEMEVAL, LightMem yields notable gains in accuracy (up to ~10.9%) while slashing costs — tokens reduced up to 117×, API calls up to 159×, and runtime reduced >12× in some settings. ⚡
☑️ Upcoming (README Todo — highlights):
- Offline pre-computation of KV cache for update (lossless)
- Online pre-computation of KV cache before Q&A (lossy)
- MCP (Memory Control Policy)
- Integration of more common models & feature enhancements
- Coordinated use of context and long-term memory storage
We’d love your feedback, issues, and PRs — let’s make memory for agents practical and lightweight! 🎙️
🚀 New Paper Alert! 🚀
We’re excited to present DataMind: a scalable recipe for building generalist data-analytic agents that outperform even the strongest proprietary models like GPT-5 and DeepSeek-V3.1!
Paper: https://t.co/zyPp6mG2tn
Code: https://t.co/qxiAEhhsCj
🧠 Models & Data: https://t.co/qVS3n7Vd4g
---
🧩 Motivation:
Most data-analytic agents rely on proprietary models or prompt engineering. Open-source models struggle with complex, multi-step reasoning over diverse data formats. We set out to change that.
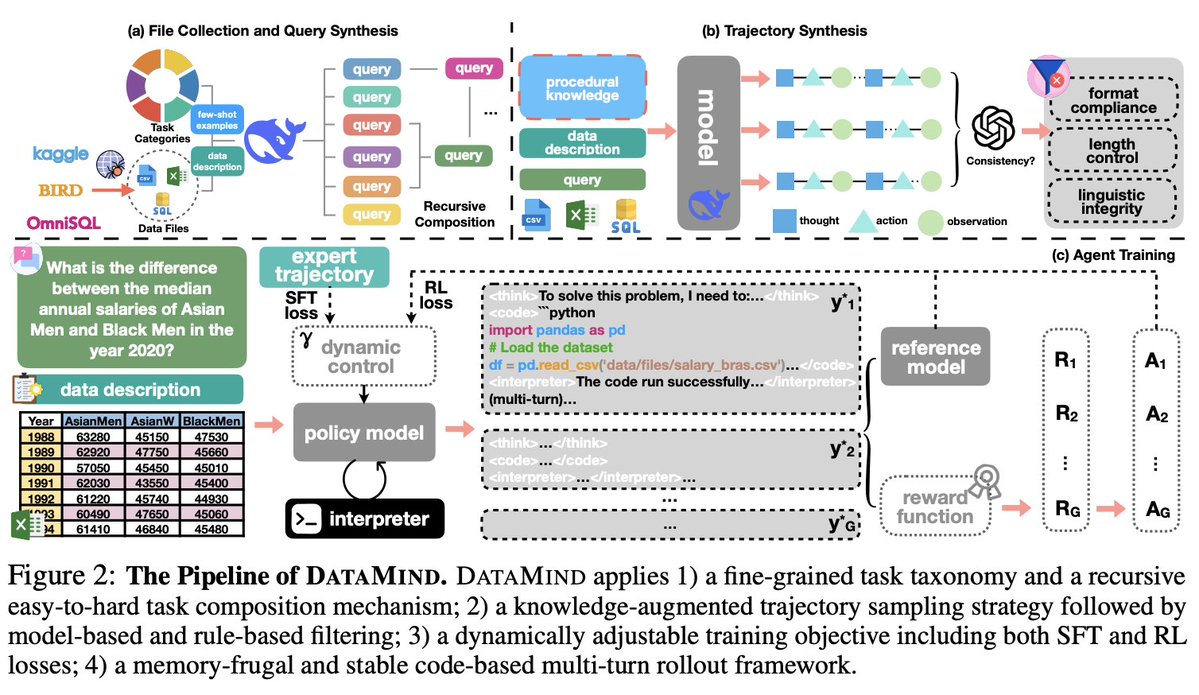
We mainly address three key challenges in building open-source data-analytic agents, including insufficient data resources, improper training strategy, and unstable code-based multi-turn rollout.
---
🔧 Our Approach:
We introduce DataMind, a full pipeline featuring:
✅ Fine-grained task taxonomy & easy-to-hard query synthesis
✅ Knowledge-augmented trajectory sampling + self-consistency filtering
✅ Dynamic SFT + RL training with stable multi-turn rollout
✅ Memory-efficient code execution & sandboxed environments
---
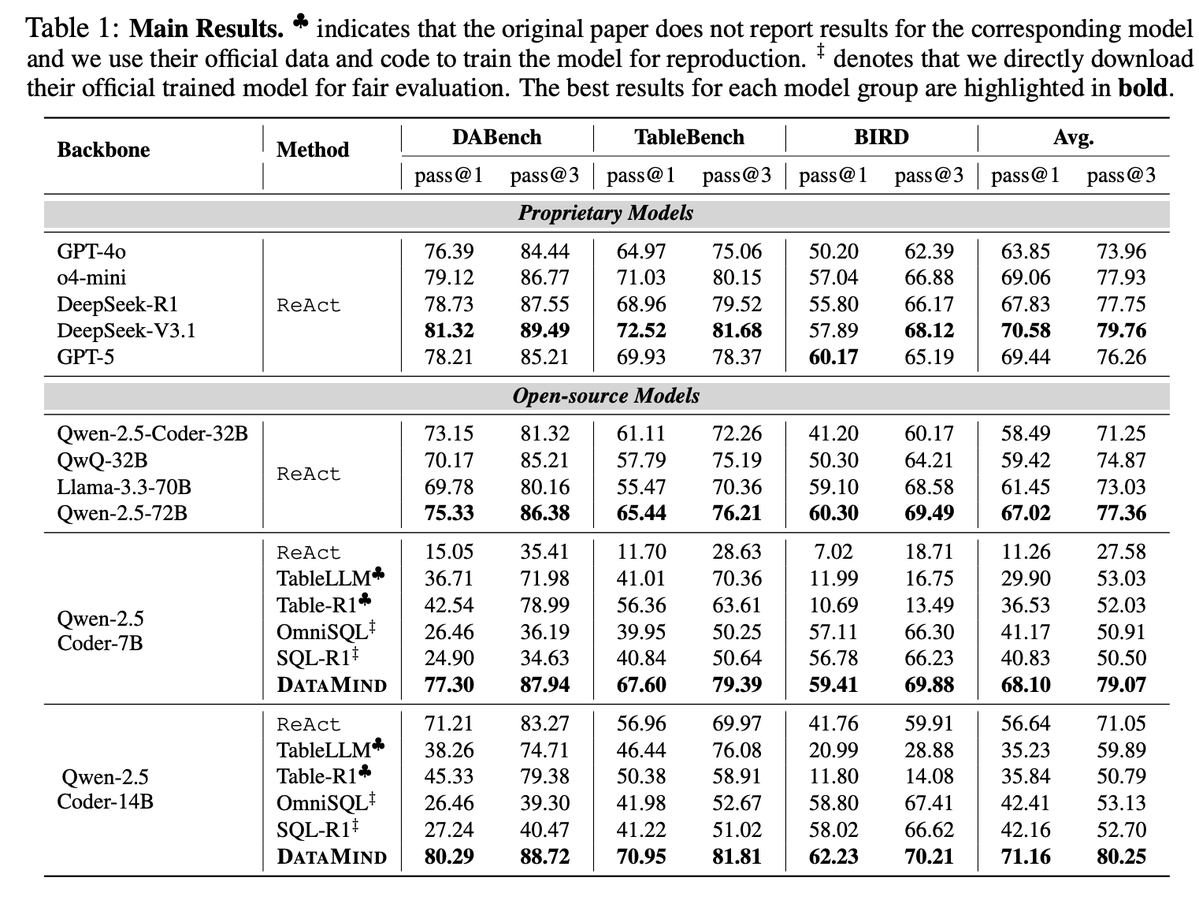
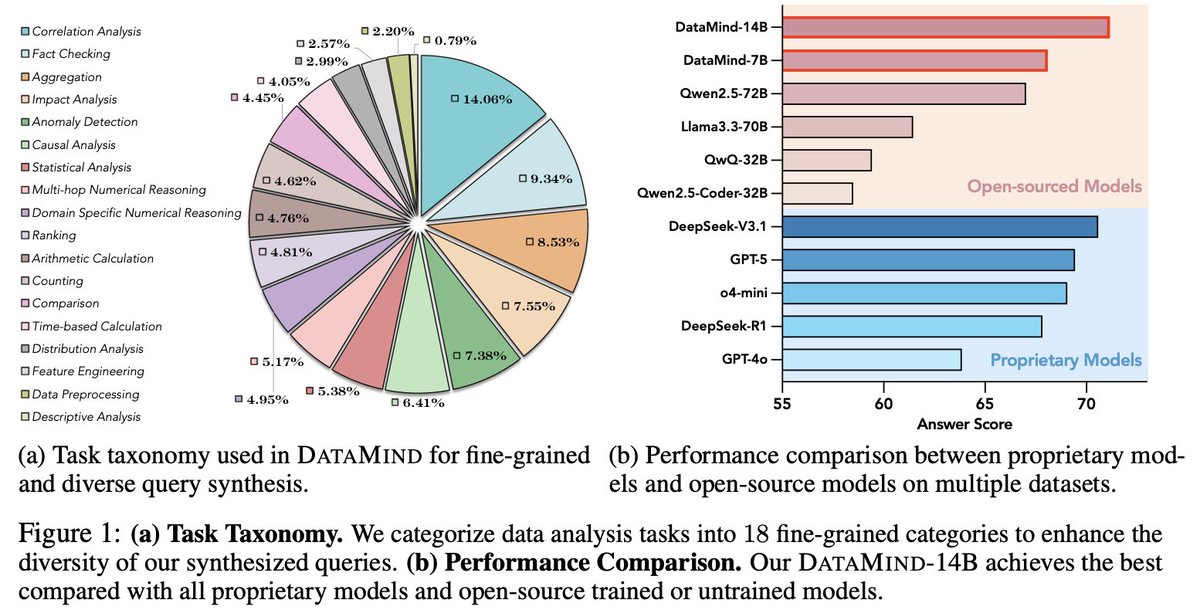
📊 Results:
Our DataMind-14B achieves SOTA 71.16% avg score across multiple benchmarks, surpassing GPT-5 and DeepSeek-V3.1.
DataMind-7B also leads all open-source models with 68.10% — trained on 12K high-quality trajectories!
---
💡 Key Insights:
- Self-consistency filtering > best trajectory selection.
- SFT loss is an effective stabilizer for RL training, but can also be the culprit of unstable training.
- RL narrows performance gaps but doesn’t reverse model ranking.
---
We have released DataMind-12K dataset and DataMind-7B/14B models to empower the community.
Let’s build smarter, more capable open-source agents together! 🧠📈
#AI #DataScience #LLM #Agents #OpenSource #DataAnalysis #ReinforcementLearning #NLP
Although the ICLR main conference is coming to an end, we are excited to invite you to the Reasoning and Planning for LLMs Workshop, which will be held all day on Monday, April 28.
We are honored to host an outstanding lineup of keynote speakers and panelists from Meta, OpenAI, Google DeepMind, Oxford, UW, UCLA, NTU, and HKUST. They will share their latest research breakthroughs, cutting-edge perspectives, and deep insights on world models and beyond.
In addition to keynote talks and panel discussions, we encourage you to also check out 7 oral presentations and over 110 poster presentations accepted at the workshop, covering a wide range of topics related to reasoning and planning.
The full workshop schedule is attached below.
For more details, please scan the QR code or visit the official website:
🔗 https://t.co/SHxAtvGWhp
#ICLR2025 #LLMs #Reasoning #workshop
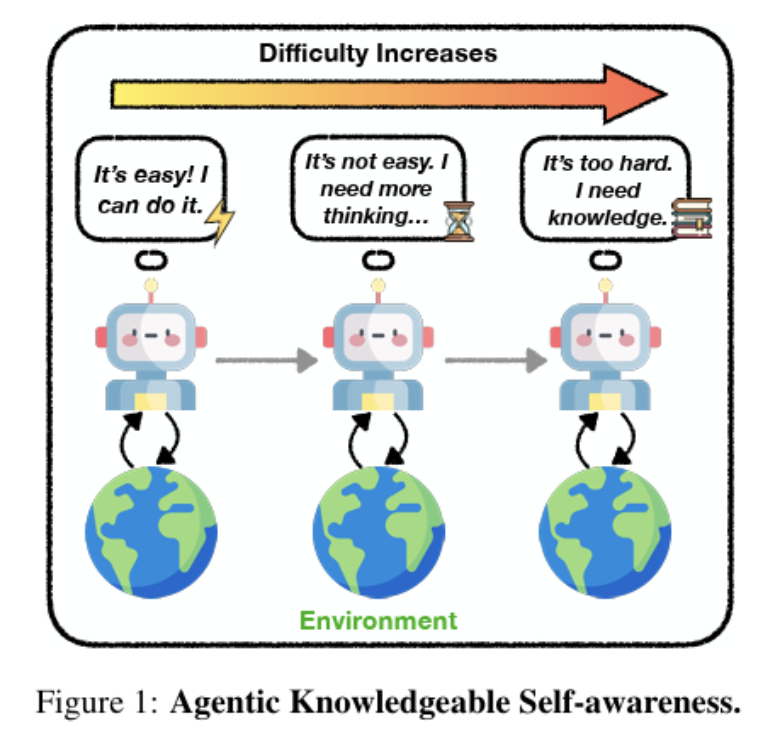
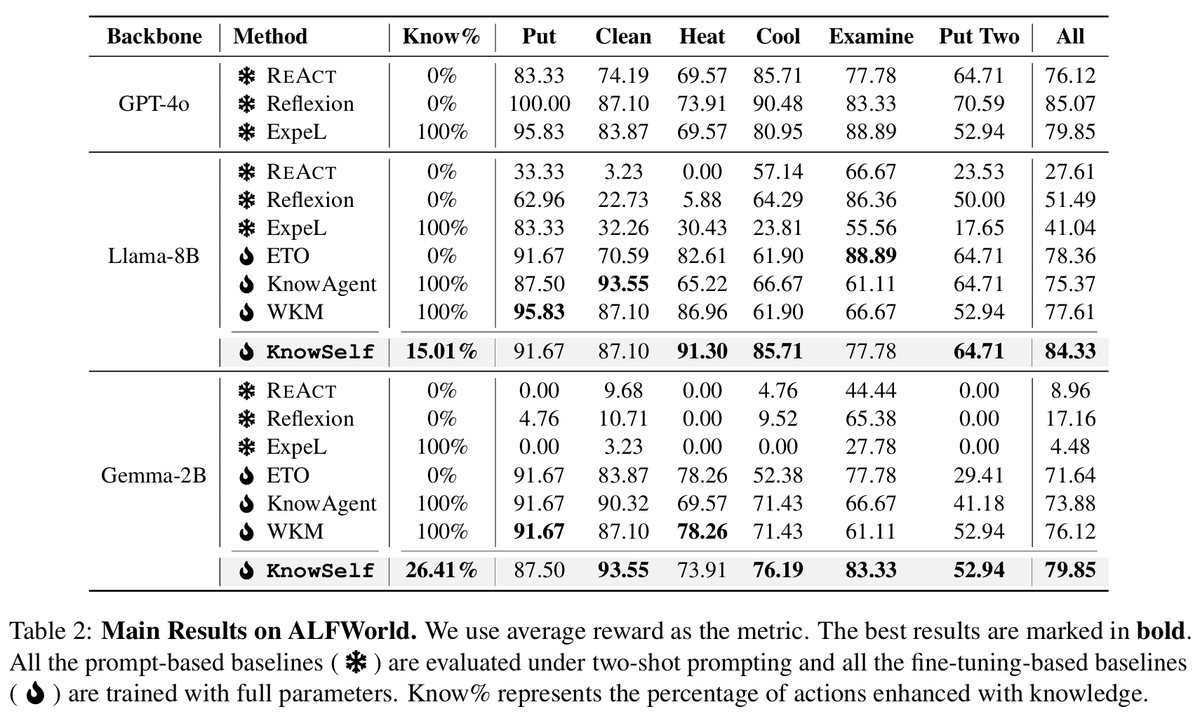
Tired of agents that mindlessly follow patterns? 🤖💡
We introduce "Agentic Knowledgeable Self-awareness", enabling agent to dynamically assess situations and strategically use resources!
Paper: https://t.co/ySgwkIVqwA
Code: https://t.co/vr4kS7JBzg
🧠 Key Idea:
Agents learn to recognize when they need to reflect, when to seek knowledge, and when to act directly. This avoids overfitting to planning patterns and reduces unnecessary knowledge usage.
🔍 How It Works:
1️⃣ Data-Driven Training: Special tokens mark fast, slow, and knowledgeable thinking.
2️⃣ Two-Stage Learning: Supervised fine-tuning + RPO loss for robust self-awareness.
3️⃣ Inference: Agents generate tokens to reflect or query knowledge based on context.
📈 Results:
Outperforms baselines with minimal knowledge usage!
Breaks pattern overfitting and enhances generalization!
Scales efficiently with model size and training data!
🌐 Future:
KnowSelf paves the way for smarter, more efficient agents. Maybe in the future, we can train models to develop stronger agentic self-awareness through reinforcement learning + powerful verifier engineering. #AI #LLMs #AgentPlanning #SelfAwareness #NLP #agent #KnowledgeAugmentation
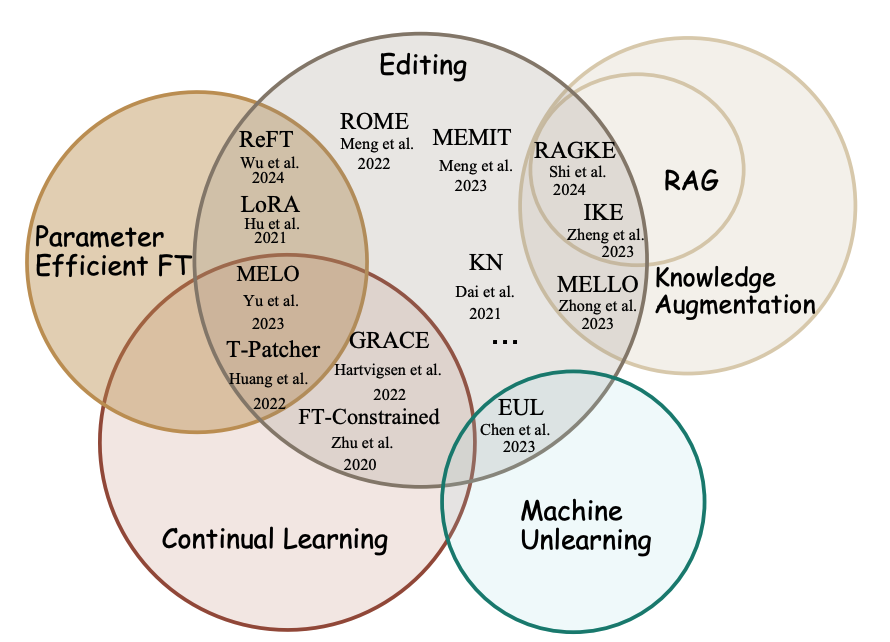
We are going to present the following works at #NeurIPS2024 covering knowledge editing, mechanism and agents. Welcome to discuss with the presenters @dsmall2apple1@yyzTodd ! (ps: I'm not attending)
[Knowledge Editing] WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models
Location: East Exhibit Hall A-C #3403
Time: Wed 11 Dec 4:30 p.m. PST — 7:30 p.m. PST
Also at Foundation Model Interventions Workshop
Location: West Meeting Room 121, 122
Time: Sun 15 Dec, 8:15 a.m. PST
[Knowledge Mechanism] Knowledge Circuits in Pretrained Transformers
Location: East Exhibit Hall A-C #3211
Time: Thu 12 Dec 4:30 p.m. PST — 7:30 p.m. PST
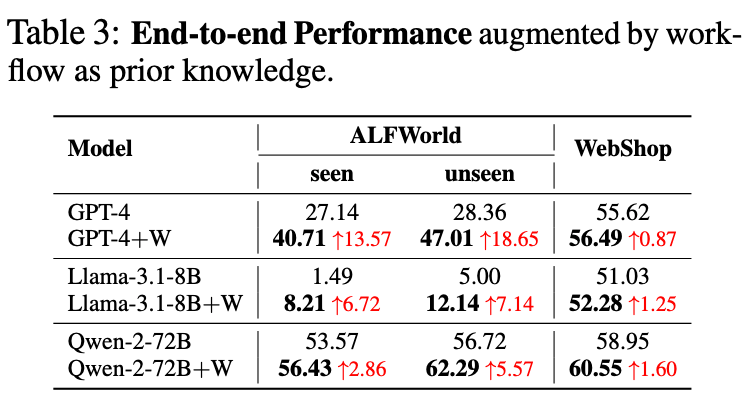
[Knowledgeable Agents] Agent Planning with World Knowledge Model
Location: East Exhibit Hall A-C #3311
Time: Thu 12 Dec 11 a.m. PST — 2 p.m. PST
Introducing our latest paper, "Benchmarking Agentic Workflow Generation"! 🚀
ArXiv: https://t.co/ZvyrxULJo2
Website: https://t.co/IuRqJcRLF1
Data: https://t.co/9qC6G5mwze
Github: https://t.co/jLpW03kuDI
🧠 Large Language Models (LLMs) play a crucial role in breaking down complex tasks into executable workflows. However, we've found that existing workflow evaluation frameworks either focus solely on overall performance or have limitations in scenario coverage, workflow structure, and evaluation standards.
🌈 We present WorFBench, a unified workflow generation benchmark with diverse scenarios and intricate graph-based workflow structures. Coupled with WorFEval, our systematic evaluation protocol using subsequence and subgraph matching algorithms, we accurately quantify the workflow generation capabilities of LLM agents.
🔥 Through comprehensive evaluations across various LLMs, we've discovered a significant gap—about 15%—even between the sequence planning and graph planning capabilities of the most advanced GPT-4. We also conducted case analyses on o1, revealing that LLM lack essential environmental knowledge for planning capabilities.
🔧 We've trained two open-source models and evaluated their workflow generation generalization abilities on held-out tasks. Moreover, we've observed that generated workflows can enhance downstream task performance, reducing inference time and increasing efficiency.
🌟 Our work not only advances LLMs in workflow generation but also lays the foundation for future research and applications. Don't miss this study! #LLM #AIResearch #Workflow #AI #Agent #NLP
@ZhenhengT@ChenHuajun Hi, many thanks for your interest on our work! The project only involves training 7/8B models with lora. So there will be very few computational sources needed. Welcome to try it !
Excited to share that our team will be at ACL 2024 in Bangkok from August 11-16! We'll be presenting our latest work on knowledge editing, agent learning, and information extraction at both the main conference and workshops @aclmeeting . Can't wait to connect and chat with everyone there! 🌟 #ACL2024 #AI #NLP #LLMs
1. Mon 11:00-12:30@Convention Center A1, Poster Session A
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models (Demo)
2. Mon 11:00-12:30@Convention Center A1, Poster Session A
OceanGPT: A Large Language Model for Ocean Science Tasks
3. Tue 10:30-12:00@Convention Center A1, Poster Session D
Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View
4. Tue 10:30-12:00@Convention Center A1, Poster Session D
IEPile: Unearthing Large-Scale Schema-Based Information Extraction Corpus
5. Tue 16:00-17:30@Convention Center A1, Poster Session E
Detoxifying Large Language Models via Knowledge Editing
6. Tue 16:00-17:30@Convention Center A1, Poster Session E
Unified Hallucination Detection for Multimodal Large Language Models
7. Wed 10:30-12:00@Convention Center A1, Poster Session F
AutoAct: Automatic Agent Learning from Scratch for QA via Self-Planning
8. Wed 10:30-12:00@Convention Center A1, Poster Session F
EasyInstruct: An Easy-to-use Instruction Processing Framework for Large Language Models (Demo)
Our team will also present works at NLRSE, HuCLLM, Knowledge Augmentation NLP, and KnowledgeableLMs workshops during #ACL2024 in Bangkok! 🎉
Huge thanks to all the organizers for their hard work in making this event happen!
Curious about how knowledge in LLMs is acquired, stored, utilized, and subsequently evolves in individuals and groups?
New Paper: https://t.co/toPmgGhHuF
Our latest research on "Knowledge Mechanisms in Large Language Models: A Survey and Perspective" provides a novel perspective to review the knowledge mechanism in LLMs, delves into the underlying reasons for current challenges, and explores future directions #NLP #LLM #AI #KnowledgeEditing #interpretability.
Previous interpretability surveys typically aim to investigate various methods for explaining the roles of different components within LLMs (at the inference stage) from the local and global taxonomy. Our novel taxonomy, including knowledge utilization and evolution, pioneeringly reviews the mechanism throughout the knowledge life cycle.
We conclude the following hypotheses:
1. Knowledge utilization spans across three levels:
Memorization: LLMs Recall knowledge through Modular Regions or Connections. Note that Modular Regions can be specific neurons, MLP, attention heads, or a transformer block layer. Knowledge circuits are the popular connections in LLMs.
Comprehension and application: LLMs Reuse Certain Components in Reasoning and Planning.
Creation: LLMs May Create Knowledge via Extrapolation.
2. Knowledge evolves in individuals and groups:
Conflict and Integration Coexist in the Dynamic Knowledge Evolution of LLMs.
3. Discussion on some open questions:
LLMs may possess basic world knowledge but hardly master principle knowledge of underlying rules for reasoning and creativity due to architecture limitations.
The fragility of knowledge in LLMs mainly derives from improper learning data.
Besides, we hypothesize that there will still exist dark knowledge for intelligence in the future.
Inspired by the mechanism analysis, we also provide some promising directions for more efficient and trustworthy architecture and learning strategy for future models.
This is just the beginning! Knowledge mechanisms may unlock the golden door to intelligence and illuminate the current darkness.
Join the discussion and share your thoughts!
Current practices in agent research and development are limited to the expert-centric, or model-centric paradigm, which heavily relies on manual efforts to design agentic workflows, prompts, and tools. We believe data-centric agents are crucial for next-generation agent research and development and are super excited to share our recent research at @AIWaves_Inc on data-centric agent learning
We consider agents as symbolic networks where the computational graph is defined by the agentic workflow and the weights are defined by the prompts and tools in each node in the workflow. This makes us able to mimic the connectionist learning procedure: back-propagation and gradient descent with language and LLMs. We use natural language (texts) and LLM+Prompts to simulate loss (functions), gradients, chain rules for back-propagation, and gradient-based optimizers. With the resulting agent symbolic learning framework, agent developers and researchers are able to
The agent symbolic learning framework enables data-centric agent learning and makes agents able to self-evolve after being created and deployed in the wild. This enables agents to do situated life-long learning in web environments or in the real world (with embodied agents?) and continually acquire new workflows and knowledge/tools.
Check our paper at https://t.co/MKOuLjO0Gh. Codes are open-sourced at https://t.co/rZ1Hv7IrY1.