A solid browser-agent task has 5 parts: goal, allowed actions, forbidden actions, success check, stop condition. Without those, you are hoping the agent shares your assumptions.
A task contract gives the agent a finish line and a guardrail.
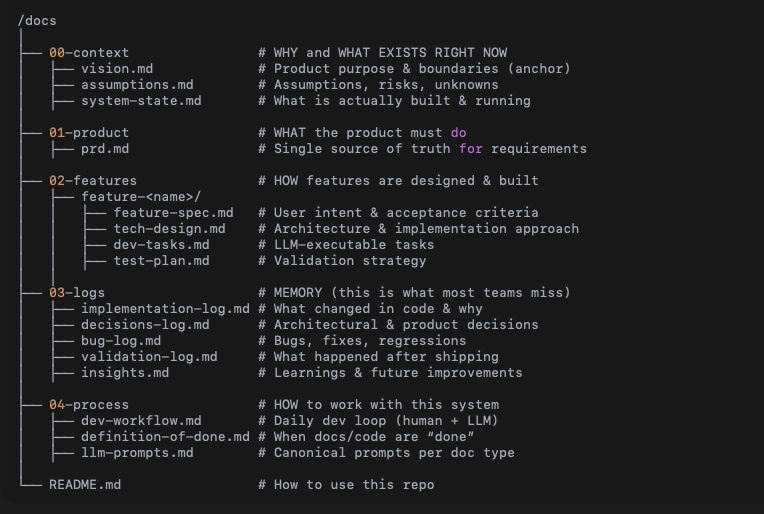
A good knowledge system shortens the next loop. Faster setup, better prompt, clearer test, safer deploy, quicker diagnosis. If a note does not improve a future action, it probably belongs in the archive.
The goal is not memory for its own sake. It is a shorter next loop.
Your local DB should be boringly close to prod. Same engine, same migrations, same constraints. SQLite locally and Postgres in prod can be fine, but know where their behavior differs.
Local shortcuts are fine only when you know exactly where prod differs.
Do a monthly key audit.
Which API keys exist?
Who created them?
What can they access?
When were they last used?
Which ones belong to dead prototypes?
AI projects multiply credentials quickly. Old experiments become quiet liabilities.
AI makes broad refactors feel cheap. Integration makes them expensive.
Changing 40 files is easy for the model.
Understanding 40 files is still your job.
Shrink scope until you can explain the blast radius in one sentence.
Edge cases are cheaper when they are sentences.
"If the import fails, keep the old data and show the error."
Write that before coding and the implementation has a spine. Skip it and you discover the product policy inside a bug.
AI can implement the ticket and still miss the product.
It will not know that this empty state is scary, this retry is expensive, or this permission copy will confuse admins.
Code correctness is only one layer of the work.
AI can generate the feature, but you still need to touch the screen.
Click the slow path.
Resize the window.
Use bad input.
Refresh mid-flow.
Try the empty account.
A lot of "AI bugs" are really skipped human QA.