We have been working closely with @nvidia to ensure Hermes Agent works smoothly on their new @NVIDIARTXSpark superchip and integrates with the new OpenShell runtime, which connects Hermes to @Microsoft's security primitives.
Watch our feature in the big announcement at Computex:
Claude i do have this idea, yes make no mistake. yes make it little bit interactive. yes show logs on the screen. Oh you put live radar nice. You put automatic targeting too??? Excellent !
Palantir’s PRISMA software is actively running inside Ukrainian long-range drone strike command posts — confirmed on camera by CNN’s Nick Paton Walsh, who filmed inside a unit planning kamikaze drone strikes deep into Russia.
Screens showed real-time maps, flight paths, and AI-processed data overlays while a masked commander (“Vector”) walked through strike planning live.
The AI ingests thousands of parameters — crucially including where Russian air defenses are intercepting drones — then calculates optimal routes for the next wave to slip through the gaps.
It’s essentially learning the holes in Russia’s air defense net in real time.
Step 3.7 Flash is now free for 30 days via Nous Portal
It is a new MoE vision-language model focused on agent efficiency, coding, search, and multimodal workflows — and Hermes Agent users have been loving it, so thank you to @StepFun_ai for hooking them up!
llama.cpp now has an official website: https://t.co/vztdUpdBWL
Our goal is to make local AI accessible to everyone, and improving the user experience is a big part of that. On the new landing page you’ll find a single-line cross-platform installer. The installation provides a single unified `llama` entrypoint which you can use to run/serve models and interface with 3rd-party agentic applications.
While oriented towards simplified user experience, the new `llama` application also provides all the advanced functionality of the existing llama.cpp tooling with which experienced users are already familiar. Also note that all GGUF models that you might have already downloaded with llama.cpp in the past will be automatically available to use without downloading again (they are stored in the common HF cache on your machine).
We have many improvements in the pipeline both at the UX and at the engine level and we plan to iteratively ship new things over the coming months. One of the main focuses will be seamless integration with local-friendly 3rd-party agents (such as Pi). In the meantime, we’ll continue to listen for feedback from the community and adjust accordingly, so keep letting us know what you think and need.
Hermes Agent v0.15.0 is out now!
747 PRs by 321 Contributors - thank you all for the work on this release!
Some Highlights:
- NFTY Platform added to gateway channels
- Skill Bundles and MCP Catalog
- Krea 2, Opus 4.8, Qwen 3.7 and more models supported
- Deep xAI Integrations
Huge performance optimizations and code cleanup:
- Load times 50% faster
- Session Search 750x faster
- No more godfile scripts
- Kanban redux
Security Updates:
- Bitwarden native integration
- Brainworm prompt injection defense
- Auto supply chain defense
And a whole lot more, check it all out below
🚀 Better inference efficiency, lower costs, broader access.
MiMo-V2.5 Series API pricing is now permanently reduced — by up to 99% compared to previous pricing.
✨ Unified pricing across all context lengths.
MiMo Token Plans have also been upgraded:
• 5–8× more usable tokens at the same price
• Simpler and more transparent billing rules
🎁 As a thank-you to current users, all current Token Plan credits will be fully reset.
🎧 MiMo-V2.5-TTS remains free for a limited time.
⏰ Effective May 26 at 6:00 PM PDT.
These improvements are powered by continued inference optimization and serving efficiency upgrades across the MiMo stack.
🛠️ We’ll also publish a detailed technical blog on the inference optimizations later — stay tuned.
@witcheer Build looks solid! Have fun with it. I probably pair it with the dense Qwen 3.6 27B (Q8) and also if you can try Qwopus3.6-27B let us how it performs.
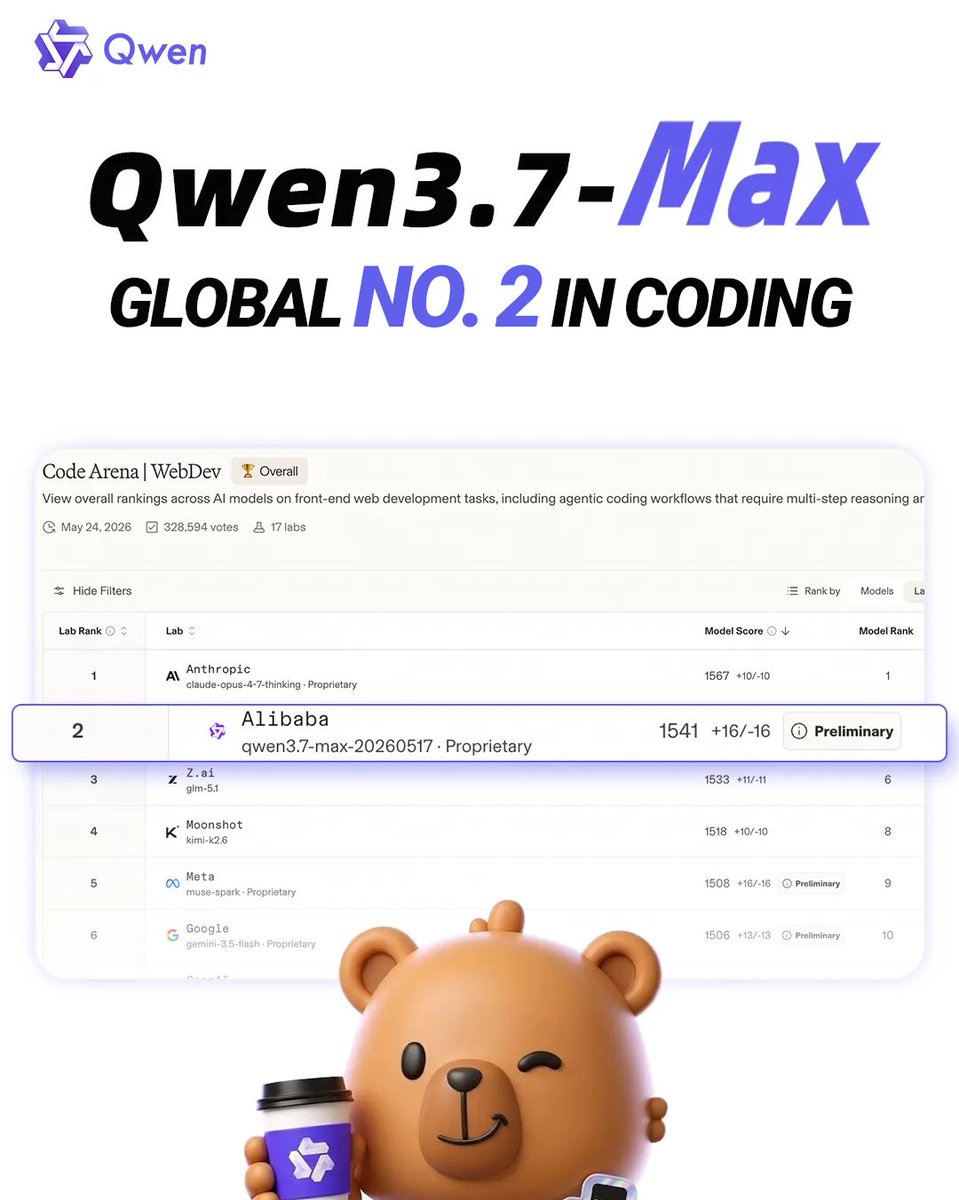
Qwen3.7-Max is officially the #2 AI coding model globally. Scoring 1541 on Code Arena, it trails only Claude. Built for production: runs 35-hour tasks, 1000+ tool calls, and ships 2-week projects in hours.
Hello again, everyone!
We've got another really fun 9b, this one specifically trained for tool calling and agentic coding workflows in @NousResearch Hermes agent.
Happy to report that it crushes, and as a 9b it runs on super affordable hardware. We also hit this one with some coding domain-specific training, and it scored a 53.33% on SWE bench on a slice of 200 samples!
To me, I was really shocked to see this high of a score on a 9B model in swe, correct me if I'm wrong, but I think that's nipping at the heels of the Gemma 4 series, much larger models on this particular benchmark, which is really incredible to see!
It also crushes the HermesAgent-20 benchmark, scoring an 85 vs the base model's 71!
Make sure to run it hot, --temp around 1, that seems to be the sweet spot for running these particular fine tunes in harnesses. If you have trouble, you can work your way down, but it does a much better job departing from base models, overthinking when you run it, high temp ~1.
Please spin it up in Hermes and let us know your thoughts! Looking forward to hearing your feedback as always!
Also, those of you waiting for Qwopus 3.6 27B, I have put together a preliminary evaluation for you in my HF repo, go check it out; we will be releasing the full model very soon! I will put the preliminary repo in the comments!
https://t.co/vP2s9iP6wL
🚀 BREAKTHROUGH: DeepSeek-V4-Flash with SSD KV Cache Offload on Blackwell
We achieved 63 tok/s inference of DeepSeek-V4-Flash-FP8 (284B) on 4× RTX PRO 6000 Blackwell (TP=4) with full 1M context via SSD KV cache offload! 🎯
🧠 sglang + SM120 custom flash_mla kernel
💾 KV cache → Optane SSD (ds4-server inspired disk offload)
📐 1,048,576 token context — not a typo
⚡ 63 tok/s throughput with CUDA graphs
🔄 L1 GPU → L2 DRAM → L3 SSD hierarchical caching
The secret sauce: everything runs on Optane SSD — model weights, KV cache, and OS. Low latency all the way down.
• DeepSeekV4TokenToKVPoolHost — host-side pool for DS4V's compressed MLA
• DiskOffloadBackend — L3 SSD backend with LRU eviction
• HiRadixCache patch — full DS4V compatibility
• Hybrid pool assembler integration
First time DS4V runs at production speed with SSD-backed long context on Blackwell hardware. 🌊
Repo & full write-up coming soon! 📝
#DeepSeek #Blackwell #SM120 #sglang #AI #LocalLLM #Optane
I don’t know a ton about AM5 motherboards, but swapping it for one that supports PCIe x16 + x8 would make a lot more sense. After that, adding more RAM would be a beast. You’ll probably need a stronger PSU (or power-limit the GPUs), but with GPU sharding this setup should work really well for MoE models or hosting 27b dense on 4090 and 35b3a on 4060.
I currently run an RTX 4070 12GB and I’m thinking about adding a 3090 24GB + upgrading the motherboard and PSU.
But need some people who actually use something like this to comment here...