Recently we built OTelBench – a benchmark to test how well LLMs handle OpenTelemetry instrumentation.
We tested 14 models. The best (Claude Opus 4.5) hit only 29%.
These weren't trick questions, just small subset of typical SRE tasks.
Link here:
https://t.co/t8t0Hsf8wa
AI + Ghidra by NSA = reverse-engineering fun
I am speaking at @AITinkerers Warsaw, 4th Mar 2026.
One of my favorite event series - by and for the creators community.
Vibe-resurrecting an old game from binaries 👾 and vibe-hardware-ing a LED backpack 🎒🌈.
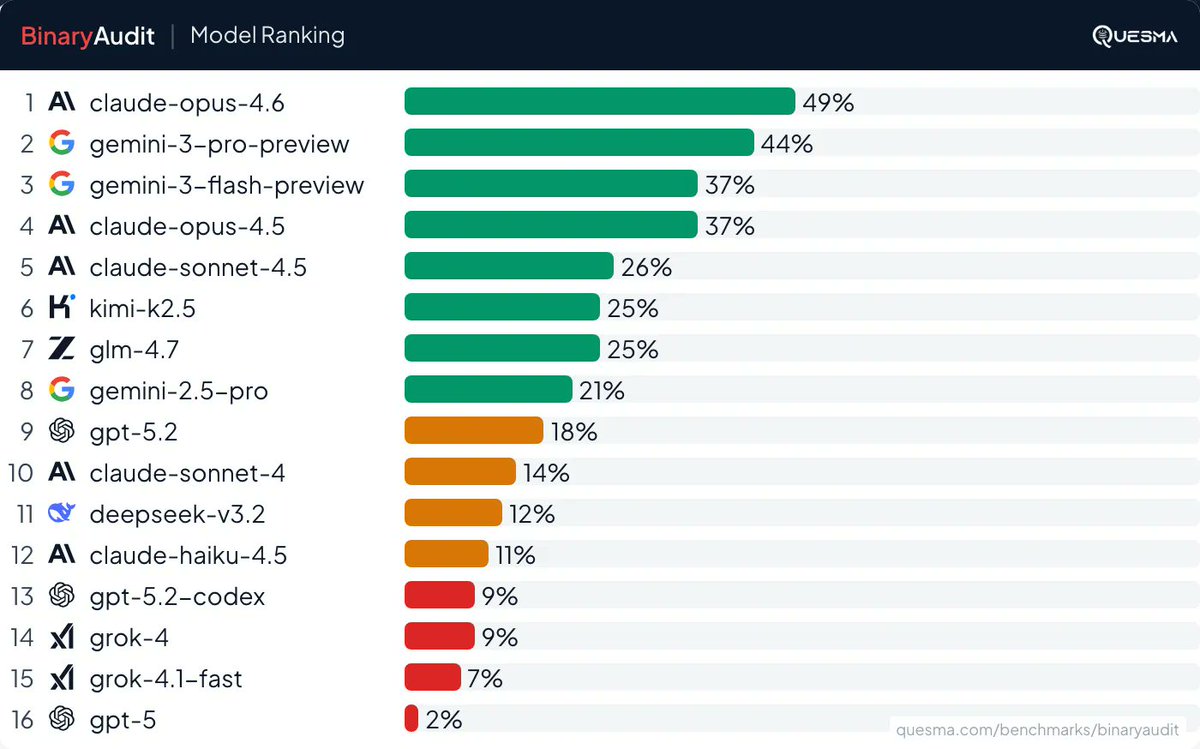
Claude can code, but can it read machine code?
We gave AI agents access to Ghidra (a decompiler by the NSA) and tasked them with finding hidden backdoors in servers - working solely from binaries, without any access to source code.
See our BinaryAudit: https://t.co/VPNk5ChPfH
Great to see the community releasing benchmarks in @harborframework now. These are invaluable resources for collectively building the most useful agents.
Finally, an AI that can draw a map without getting lost. Nano Banana Pro uses tools to create factually correct infographics - and it's a game-changer.
https://t.co/j17V5Rxu5p
Interesting use case for AWS Lambda that we explored: sandboxing AI-generated code.
We tried WebAssembly first but hit the wall. So, we scrapped our experiment for AWS Lambda with Docker containers in an isolated VPC.
Full writeup from @pmigdal:
https://t.co/nBxW6PtuMS
Lambda has tons of use cases, but one I've missed: using it as some kind of sandbox for running AI-generated code.
Lambda's isolation and scaling are a solid fit for this problem.
The security paradox of local LLMs - https://t.co/nOtVOULgd9 by @jakozaur at @QuesmaOrg
If you’re running a local LLM for privacy and security, you need to read this. Our research on gpt-oss-20b (for OpenAI’s Red‑Teaming Challenge) shows they are much more prone to being tricked than frontier models. When attackers prompt them to include vulnerabilities, local models comply with up to 95% success rate. These local models are smaller and less capable of recognizing when someone is trying to trick them.
#AISecurity #LLMSecurity #LocalLLM #GenAI #MLOps #ModelRisk #DataPrivacy #AIPrivacy #PromptInjection #AIThreats #AIGovernance #EdgeAI
See the full ranking and every run (logs, commands, binaries), methodology & code:
▶️ https://t.co/nLrxMUQw0a
💻 https://t.co/JZGKouDeYa
📃 https://t.co/QXPKpVDApa
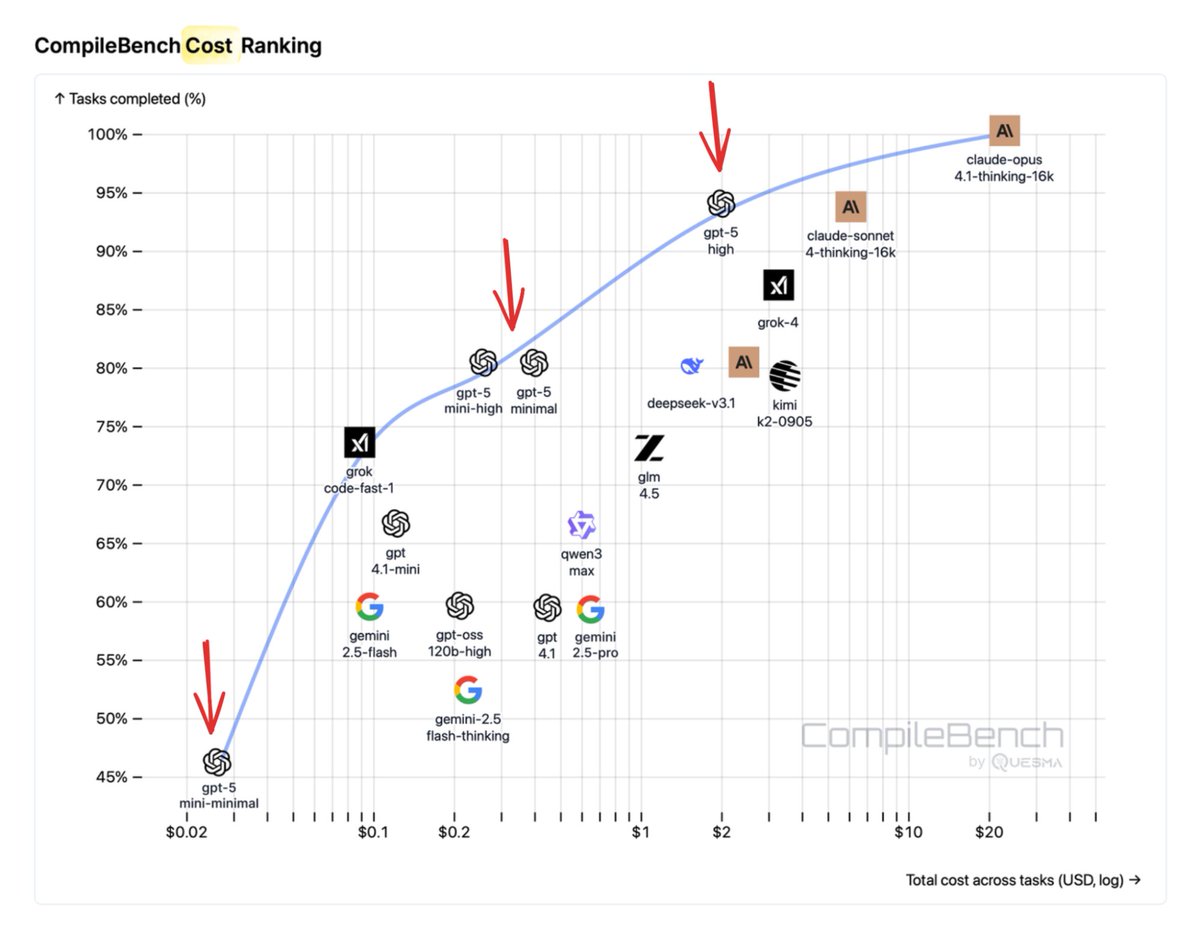
Can AI compile 22-year-old code? We built CompileBench to find out.
We know that LLMs can vibe-code or even win IOI, but what about dependency hell or legacy build systems?
(image based on XKCD 2347)
Cost-efficiency crown: @OpenAI.
Across difficulties, OpenAI models dominate the Pareto frontier of cost.
GPT-5-mini (high reasoning) is a great price/perf pick; GPT-4.1 is the fastest with solid wins.
At #IcebergSummit 2025, Ryan Blue unveiled Iceberg beyond Java, plus the path to Table Spec V3 & forward to V4. Przemysław Delewski’s new blog covers Fokko Driesprong on Pylceberg, Matt Topol on Go, Julien Le Dem on modular DBs. Essential read for next-gen data platforms. Link👇
Everything is better when Kawaii 🌸🌸🌸:
Titanic survival rates with freshly-released Quesma Charts.
https://t.co/YCxi3UedHN
At @DataCouncilAI conference in Oakland with Jacek Migdał.
#dataViz@QuesmaOrg@jakozaur