Thanks all for coming to Paris @ICCVConference and making it such an amazing event.
As warned, we brought the whole @valeoai family, interns and seniors alike, and it was a blast!
We are so happy to share good papers, discussions and laughs. What an amazing community #ICCV2023
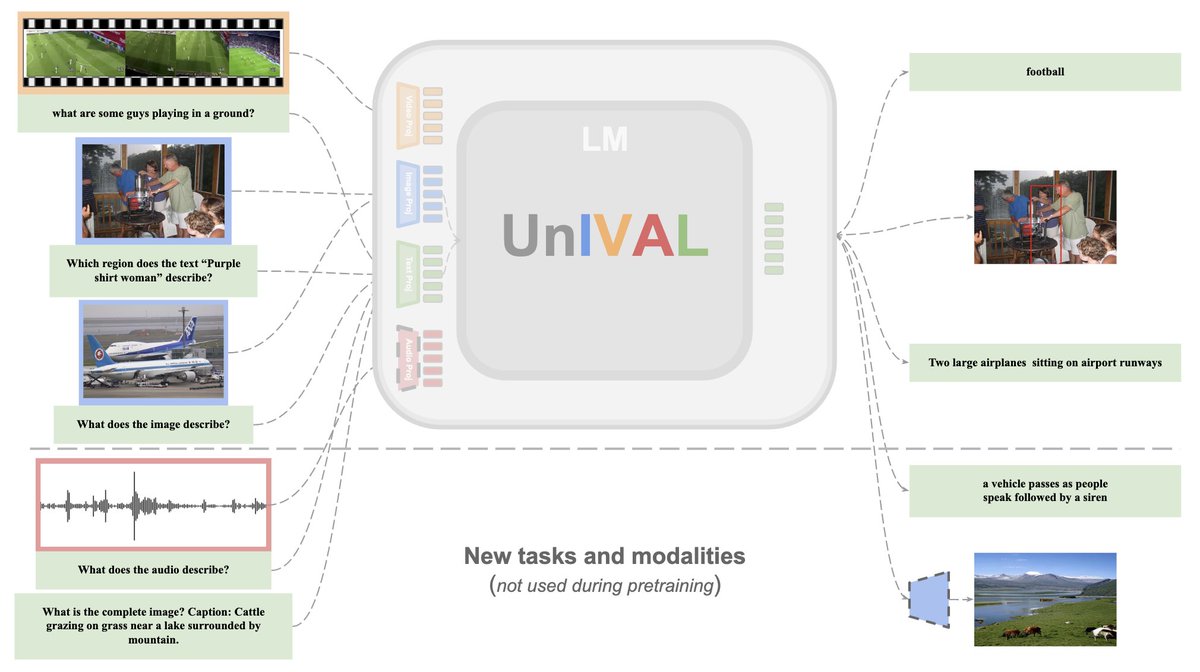
UnIVAL: Unified Model for Image, Video, Audio and Language Tasks. 👉A unified foundation model that can process images, videos and audios-language tasks, trained with academic compute budget, on public datasets. Project: https://t.co/un1lQeqW25 Workshop: Monday in MMFM
The team is active at #ICCV2023, come and say Hi to the Chordettes! They are talking about LLMs, multimodality, foundation models, diffusion models and more! Check their papers: 👇
Félicitations à @HugoTouvron qui a obtenu le prix de thèse Signal, Image et Vision 2023 décerné par le GdR ISIS !
"Architectures and Training for visual understanding"
et supervisée par @quobbe et @hjegou from @meta
https://t.co/yspQM0xrNe
@Sorbonne_Univ_@ISIR_labo
We're happy to announce the #ICCV2023 BRAVO Workshop: roBust and Reliability of Autonomous Vehicles in the Open-world. We welcome full papers and extended abstracts on robustness, generalization, transparency, and verification of computer vision models https://t.co/mlVAa71Rgm
@chriswolfvision@CSProfKGD Same. My biggest fear is not the Terminator apocalypse, but more what could happen if a large number of people ask an LLM "Sum up the candidates ideas and tell me which one is the most aligned with me" during the next elections.
Not voting, because yes/no is too restrictive.
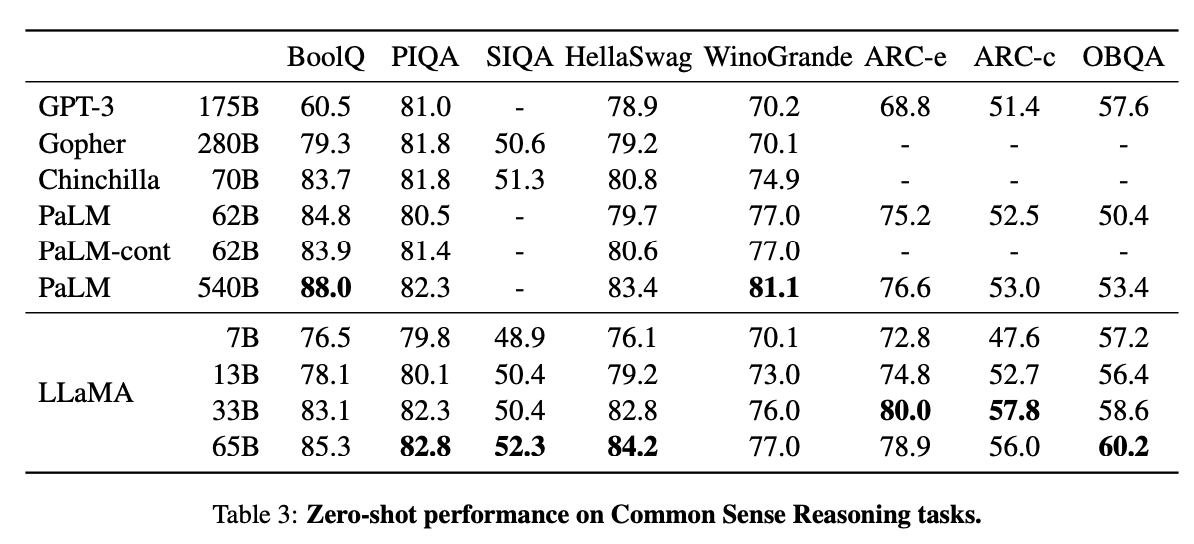
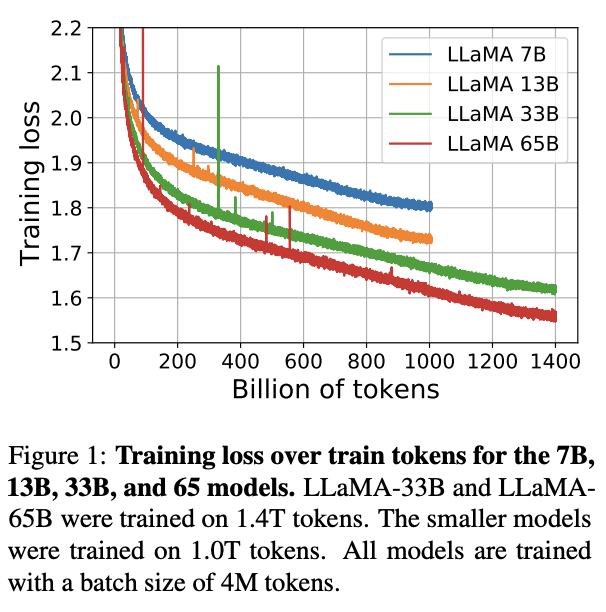
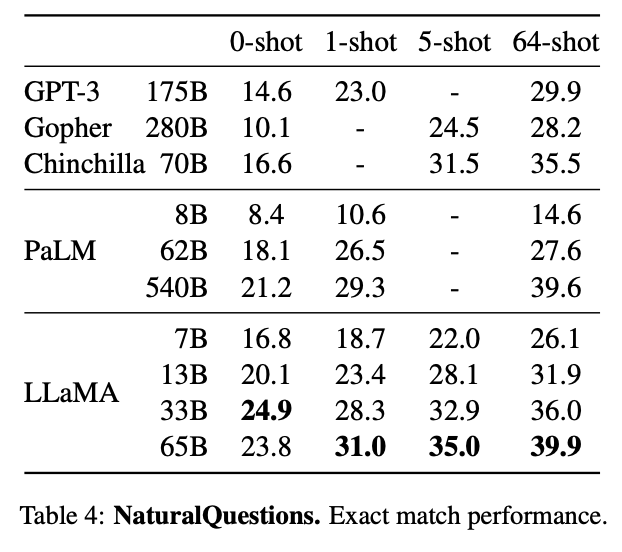
Today we release LLaMA, 4 foundation models ranging from 7B to 65B parameters.
LLaMA-13B outperforms OPT and GPT-3 175B on most benchmarks. LLaMA-65B is competitive with Chinchilla 70B and PaLM 540B.
The weights for all models are open and available at https://t.co/q51f2oPZlE
1/n
Our researchers are attending @NeurIPSConf#NeurIPS2023
Do not hesitate to reach them and discuss with them.
Review once again our papers in the following thread ⬇️⬇️⬇️
First #ECCV2022 evening with @quobbe in a nice restaurant in town. It's been a long time since the last time and we had a lot of things to talk about. There are few things as enjoyable as meeting your PhD supervisor at a conference long after you defended. 10/10, would recommend.
Cookbook for Vision Transformers https://t.co/s7Yl9sEjgk
Good insight about our DeiT III in the @AndrewYNg’s news letter
I will present it with Hugo at ECCV 2022!
I’d like to address the serious matter of some newcomers to AI experiencing imposter syndrome, where someone wonders if they’re a fraud or really belong in the AI community. Lets build a community that encourages and welcomes everyone. https://t.co/mWi5hy4D3p
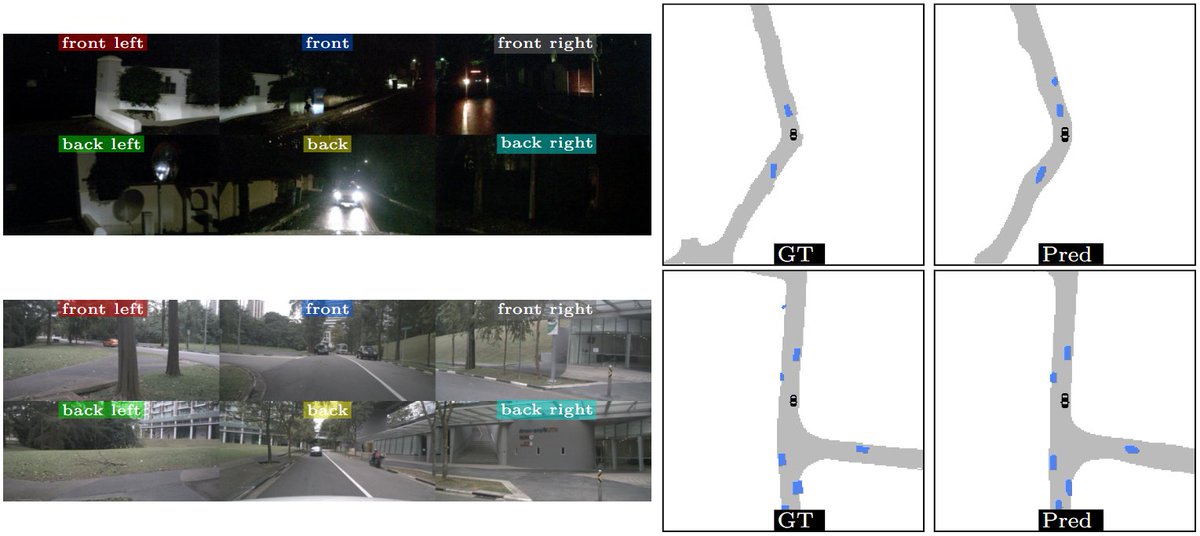
Our paper "LaRa: Latents and Rays for Multi-Camera Bird's-Eye-View Semantic Segmentation" made it to #CoRL2022 🥳
w/ F. Bartoccioni, A. Bursuc (@abursuc), P. Pérez, Matthieu Cord (@quobbe) & K. Alahari (@inthebrownbag)
arxiv: https://t.co/l46y7SZEYC
code: https://t.co/Fbz4qpDJGh
Congratulations to @HugoTouvron who brightly defended his PhD thesis today! 👏👏👏
Thank you for the very interesting presentation of your work! Good luck for the future!
One of my all-time favorite illusions: The spinning dancer
If you look at the dancer on the left and the one in the middle, the one in the middle spins clockwise.
If you look at the dancer on the *right* and the one in the middle, the one in the middle spins counterclockwise.