𝑨𝑮-𝑼𝑰 says it keeps your agent and frontend "𝑝𝑒𝑟𝑓𝑒𝑐𝑡𝑙𝑦 𝑠𝑦𝑛𝑐ℎ𝑟𝑜𝑛𝑖𝑧𝑒𝑑." Read the reference code.
When a 𝐒𝐓𝐀𝐓𝐄_𝐃𝐄𝐋𝐓𝐀 fails to apply, the handler logs a warning nobody sees and keeps the old state. No error. No resync.
Just silent drift - until a user on a train approves an email and the agent sends it to someone else.
The protocol named the escape hatch (request a snapshot) and declined to build it. Detecting drift is your job. So is paying what I call the 𝐬𝐧𝐚𝐩𝐬𝐡𝐨𝐭 𝐭𝐚𝐱: the bytes you spend re-snapshotting every time a flaky connection forces recovery - which can quietly exceed everything deltas saved you.
New piece on why 𝐒𝐓𝐀𝐓𝐄_𝐃𝐄𝐋𝐓𝐀 drifts in production, and the sequence-and-resync pattern that fixes it:
https://t.co/N4cJgHqynu
Follow for more production-realities writing on agentic systems.
#AgenticAI #AIEngineering #AGUI #LLM #SystemsDesign #HumanInTheLoop #DistributedSystems
𝐂𝐥𝐚𝐮𝐝𝐞 𝐂𝐨𝐝𝐞 𝐨𝐧 𝐄𝐧𝐭𝐞𝐫𝐩𝐫𝐢𝐬𝐞 𝐖𝐒𝐋: 𝐄𝐥𝐞𝐯𝐞𝐧 𝐄𝐫𝐫𝐨𝐫𝐬, 𝐄𝐥𝐞𝐯𝐞𝐧 𝐅𝐢𝐱𝐞𝐬, 𝐚𝐧𝐝 𝐭𝐡𝐞 𝐎𝐧𝐞 𝐅𝐥𝐚𝐠 𝐍𝐨𝐛𝐨𝐝𝐲 𝐃𝐨𝐜𝐮𝐦𝐞𝐧𝐭𝐬
You set ANTHROPIC_API_KEY. You run claude. A browser opens to https://t.co/oswPW5cn7p. You have an enterprise API key. You do not have a https://t.co/8MTJ9zMCgo account. You stare. Nothing happens.
If your company provisioned Claude Code with OAuth and SSO, this is not your problem. This is for the rest of us - developers whose companies bought API access, handed you a key, and stopped there. Your company did not set up the OAuth flow. The CLI does not know that. It tries OAuth anyway. Then it hits SSL inspection. Then stripped-down WSL. Then missing npm certs. Then eleven walls in sequence.
Anthropic shipped a fix months ago. The flag is --bare. It is one line in claude --help. Nobody documents it. Not the install guide. Not the quickstart. Not the enterprise setup docs. Every API-key-only developer hits the same cascade independently and loses the same afternoon.
𝐓𝐡𝐞 𝐜𝐨𝐫𝐞 𝐩𝐫𝐨𝐛𝐥𝐞𝐦: Claude Code ships with personal-machine defaults. Personal machines have OAuth. They have full distros. They have unrestricted networks. Corporate WSL machines have none of these. The tool assumes you are on a MacBook with a https://t.co/8MTJ9zMCgo subscription. You are on a Windows laptop with an API key and SSL inspection. The gap between those two worlds is eleven distinct failures that cascade into each other.
This article walks the full cascade - from distro identity mismatches through SSL certificate chains through npm configuration through the undocumented --bare flag that closes it all. I named every error, gave you the fix for each, and included the setup script your team should have shipped on day one.
If you are deploying Claude Code across an API-key-only team, you need to know this cascade exists so you can document it upfront. If you are an individual engineer hitting wall after wall, you need to know there are eleven walls, not infinity walls, and they end at one flag.
Read the full article to see all eleven errors, the Personal-Default Trap pattern that connects them, and the enterprise setup you should be using now.
https://t.co/fEeuomFQhp
Follow for more practitioner-focused deep dives on AI tooling and systems engineering.
#ClaudeCode #WSL #EnterpriseAI #DeveloperTooling #AIEngineering #DevOps #PlatformEngineering
𝐇𝐍𝐒𝐖 𝐕𝐞𝐜𝐭𝐨𝐫 𝐒𝐞𝐚𝐫𝐜𝐡 𝐑𝐞𝐜𝐚𝐥𝐥 𝐅𝐚𝐢𝐥𝐮𝐫𝐞𝐬 𝐢𝐧 𝐏𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧
You benchmarked on glove-100. Your users ask long-tail questions. The Index-Access Pattern Mismatch is silently destroying your RAG recall.
Your HNSW index shipped with 0.95 recall@10 in testing. Three months in production, users say the assistant "doesn't know anything." You check latency - fine. Error rates - zero. You rechunk, swap embedding models, open GitHub issues. Nothing helps. You were debugging the wrong layer.
The embedding is not the problem. The index is.
HNSW dominates https://t.co/OUY2GPZGP1 because those benchmarks test uniform query distributions - the exact opposite of production RAG systems. Your corpus is non-uniform. Some topics have hundreds of chunks; others have one. Your queries are non-uniform too. Common questions live in dense clusters; rare, long-tail questions get stranded in sparse regions where HNSW's greedy graph traversal fails silently.
When a query falls near a sparse neighborhood, the algorithm short-circuits, returning a nearby result from a dense cluster instead. High cosine similarity. Wrong answer. This compounds as corpus size grows - controlled experiments show HNSW recall degrading faster than flat search at 200k+ vectors.
The real trap: treating leaderboard position as a proxy for fit. ScaNN wins on x86 with AVX and MIPS distance. On ARM or with L2 distance, that advantage vanishes. IVF-PQ crushes memory but needs careful nprobe tuning. DiskANN handles a billion vectors in 5ms but SSD I/O adds latency on small corpora.
The question is never "which algorithm wins?" It is "𝑤ℎ𝑖𝑐ℎ 𝑎𝑙𝑔𝑜𝑟𝑖𝑡ℎ𝑚 𝑤𝑖𝑛𝑠 𝑜𝑛 𝑚𝑦 𝑐𝑜𝑟𝑝𝑢𝑠, 𝑚𝑦 𝑞𝑢𝑒𝑟𝑦 𝑑𝑖𝑠𝑡𝑟𝑖𝑏𝑢𝑡𝑖𝑜𝑛, 𝑚𝑦 ℎ𝑎𝑟𝑑𝑤𝑎𝑟𝑒, 𝑚𝑦 𝑟𝑒𝑐𝑎𝑙𝑙 𝑡𝑎𝑟𝑔𝑒𝑡, 𝑎𝑛𝑑 𝑚𝑦 𝑙𝑎𝑡𝑒𝑛𝑐𝑦 𝑏𝑢𝑑𝑔𝑒𝑡?"
Most teams ship HNSW without answering that question. By production, the failure is already silent.
𝑅𝑒𝑎𝑑 𝑡ℎ𝑒 𝑓𝑢𝑙𝑙 𝑏𝑟𝑒𝑎𝑘𝑑𝑜𝑤𝑛 𝑎𝑛𝑑 𝑡ℎ𝑒 𝑓𝑟𝑎𝑚𝑒𝑤𝑜𝑟𝑘 𝑓𝑜𝑟 𝑚𝑒𝑎𝑠𝑢𝑟𝑖𝑛𝑔 𝑦𝑜𝑢𝑟 𝑎𝑐𝑡𝑢𝑎𝑙 𝑖𝑛𝑑𝑒𝑥-𝑎𝑐𝑐𝑒𝑠𝑠 𝑝𝑎𝑡𝑡𝑒𝑟𝑛 𝑚𝑖𝑠𝑚𝑎𝑡𝑐ℎ:
https://t.co/Ri7AVczdxP
𝐅𝐨𝐥𝐥𝐨𝐰 𝐟𝐨𝐫 𝐦𝐨𝐫𝐞 𝐩𝐫𝐚𝐜𝐭𝐢𝐭𝐢𝐨𝐧𝐞𝐫-𝐟𝐨𝐜𝐮𝐬𝐞𝐝 𝐀𝐈 𝐬𝐲𝐬𝐭𝐞𝐦𝐬 𝐰𝐫𝐢𝐭𝐢𝐧𝐠.
#VectorSearch #RAG #HNSW #ANN #VectorDatabases #ProductionML #AIEngineering
𝐖𝐡𝐲 𝐘𝐨𝐮𝐫 𝐑𝐀𝐆 𝐏𝐢𝐩𝐞𝐥𝐢𝐧𝐞 𝐀𝐬𝐬𝐞𝐦𝐛𝐥𝐞𝐬 𝐂𝐨𝐧𝐭𝐞𝐱𝐭 𝐖𝐫𝐨𝐧𝐠
You found the right document. The retriever returned it at position 1. The LLM ignored it anyway - because you placed it at position 4 in a 12-document context, buried in the middle where transformer attention flattens to near-zero.
This is the Context Assembly Gap - the quality delta between what retrieval finds and what the LLM actually processes. It compounds four ways:
- 𝐏𝐨𝐬𝐢𝐭𝐢𝐨𝐧𝐚𝐥 𝐝𝐞𝐠𝐫𝐚𝐝𝐚𝐭𝐢𝐨𝐧: LLMs exhibit U-shaped attention across the context window. Position 4 of 12 receives significantly less attention than positions 1 or 12. Concatenating retrieved chunks in score order means your highest-relevance documents often sit in the dead zone.
- 𝐃𝐮𝐩𝐥𝐢𝐜𝐚𝐭𝐢𝐨𝐧 𝐧𝐨𝐢𝐬𝐞: RAG systems commonly retrieve overlapping chunks - the same paragraph from multiple sources, or adjacent chunks from the same document. You pay token cost twice for the same fact while the model over-weights it in generation.
- 𝐁𝐮𝐝𝐠𝐞𝐭 𝐦𝐢𝐬𝐚𝐥𝐥𝐨𝐜𝐚𝐭𝐢𝐨𝐧: Without explicit token allocation policy, retrieved context expands freely, crowding out conversation history or system prompt. Unmanaged budget is unmanaged cost at 100:1 input-to-output ratios.
- 𝐂𝐨𝐦𝐩𝐫𝐞𝐬𝐬𝐢𝐨𝐧 𝐟𝐚𝐢𝐥𝐮𝐫𝐞: When context exceeds budget, naive pipelines truncate or reduce retrieval count. Both sacrifice recall. Selective compression - summarizing low-relevance chunks while preserving high-relevance ones verbatim - reduces tokens while preserving what matters.
Most documentation treats context assembly as a pass-through. Karpathy named it in June 2025 as "context engineering" - the deliberate architecture of what the model sees, how much, in what order, with what structure. The LangChain State of Agent Engineering survey found context engineering the top production challenge across 1,340 respondents.
This article walks the four-stage context assembly pipeline: ordering by attention curves, deduplication across retrieved chunks, explicit token budgeting, and selective compression. These are not nice-to-haves - they are where you reclaim accuracy and cost lost upstream.
Read the full breakdown:
https://t.co/DblEbq0CjW
Follow for more on RAG engineering and production AI systems:
#RAG #ContextEngineering #LLMInfrastructure #AIEngineering #ProductionAI #Retrieval #TokenEfficiency
𝐖𝐡𝐲 𝐘𝐨𝐮𝐫 𝐀𝐠𝐞𝐧𝐭𝐢𝐜 𝐑𝐀𝐆 𝐒𝐲𝐬𝐭𝐞𝐦 𝐂𝐨𝐬𝐭𝐬 𝟏𝟎𝐱 𝐌𝐨𝐫𝐞 𝐓𝐡𝐚𝐧 𝐈𝐭 𝐒𝐡𝐨𝐮𝐥𝐝
Your agent loop is multiplying every cost in the retrieval stack by the number of times it decides to iterate - and most teams have no per-session budget cap, no cost visibility at decision time, and no circuit breaker before the API call completes.
Here is what happened: a market research pipeline ran two agents in an unintended loop - one analyzing content, the other asking for further analysis. Neither had a budget ceiling. The loop ran for 264 hours. The bill was $47,000. Nobody noticed until it was over.
The root cause was structural. When you wrap a single-pass RAG pipeline in an agent control loop, you inherit three compounding cost drivers - the 𝐋𝐨𝐨𝐩 𝐓𝐚𝐱 (paying for retrieval N times instead of once), 𝐂𝐨𝐧𝐭𝐞𝐱𝐭 𝐀𝐜𝐜𝐮𝐦𝐮𝐥𝐚𝐭𝐢𝐨𝐧 (token cost grows linearly with each iteration), and the 𝐆𝐨𝐯𝐞𝐫𝐧𝐚𝐧𝐜𝐞 𝐕𝐚𝐜𝐮𝐮𝐦 (no enforcement layer between agent decision and API execution). Together, they create a system where cost is structurally unpredictable in production.
Most teams treat every query the same way - routing everything through the agent loop regardless of complexity, tracking confidence heuristics the agent designed for itself, with no hard budget enforcement and no per-session spend tracking. Simple queries loop unnecessarily. Edge cases loop indefinitely. Cost becomes visible only on the billing statement.
The 𝐟𝐢𝐱 is direct: 𝑐𝑙𝑎𝑠𝑠𝑖𝑓𝑦 𝑞𝑢𝑒𝑟𝑦 𝑖𝑛𝑡𝑒𝑛𝑡 𝑏𝑒𝑓𝑜𝑟𝑒 𝑡ℎ𝑒 𝑎𝑔𝑒𝑛𝑡 𝑙𝑜𝑜𝑝 𝑎𝑐𝑡𝑖𝑣𝑎𝑡𝑒𝑠, 𝑒𝑛𝑓𝑜𝑟𝑐𝑒 ℎ𝑎𝑟𝑑 𝑡𝑜𝑘𝑒𝑛 𝑏𝑢𝑑𝑔𝑒𝑡𝑠 𝑖𝑛𝑠𝑖𝑑𝑒 𝑡ℎ𝑒 𝑙𝑜𝑜𝑝 𝑤𝑖𝑡ℎ 𝑒𝑥𝑝𝑙𝑖𝑐𝑖𝑡 𝑒𝑛𝑓𝑜𝑟𝑐𝑒𝑚𝑒𝑛𝑡 (not just monitoring), and 𝑡𝑟𝑎𝑐𝑘 𝑝𝑒𝑟-𝑠𝑒𝑠𝑠𝑖𝑜𝑛 𝑠𝑝𝑒𝑛𝑑 𝑎𝑡 𝑑𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑡𝑖𝑚𝑒, not in a dashboard. Agentic RAG is worth the cost premium for queries that need it. The problem is applying it uniformly to all queries without measurement or enforcement.
Read the full diagnostic and implementation patterns here:
https://t.co/NacqOCdKFL
Follow for more practitioner-focused AI systems thinking.
#RAG #AgenticAI #LLMInfrastructure #CostGovernance #LangGraph #MLOps #ProductionAI
𝐖𝐡𝐲 𝐘𝐨𝐮𝐫 𝐑𝐀𝐆 𝐊𝐧𝐨𝐰𝐥𝐞𝐝𝐠𝐞 𝐁𝐚𝐬𝐞 𝐈𝐬 𝐋𝐲𝐢𝐧𝐠 𝐀𝐛𝐨𝐮𝐭 𝐖𝐡𝐚𝐭 𝐈𝐭 𝐊𝐧𝐨𝐰𝐬 - 𝐒𝐭𝐚𝐥𝐞𝐧𝐞𝐬𝐬 𝐆𝐚𝐩
Your vector index stopped being current the moment indexing finished. A document from 18 months ago can score 0.94 cosine similarity and still be completely wrong today - and nothing in your RAG pipeline will tell you.
𝐓𝐡𝐞 𝐩𝐫𝐨𝐛𝐥𝐞𝐦: vector indexes are point-in-time snapshots that age from ingestion onward. Most teams architect them as live mirrors of their knowledge base. The gap between those two assumptions is where production failures accumulate silently.
Standard evaluation metrics (faithfulness, context recall, answer relevancy) all assume retrieved documents are currently true. They measure correctness given retrieval, not whether retrieval reflects ground truth. Your RAGAS scores keep passing while underlying documents decay. The old SSO guide scores 0.94 similarity to "how do I configure SSO" - your evals don't care that the system it describes was deprecated 14 months ago.
The 𝐒𝐭𝐚𝐥𝐞𝐧𝐞𝐬𝐬 𝐆𝐚𝐩 has three dimensions: 𝑓𝑟𝑒𝑠ℎ𝑛𝑒𝑠𝑠 𝑤𝑖𝑛𝑑𝑜𝑤 (how often you re-index), 𝑎𝑐𝑐𝑢𝑚𝑢𝑙𝑎𝑡𝑖𝑜𝑛 𝑟𝑎𝑡𝑒 (stale documents pile up as corpus grows), and 𝑑𝑒𝑡𝑒𝑐𝑡𝑖𝑜𝑛 𝑣𝑜𝑖𝑑 (no signal that answers came from outdated context). Add in document update conflicts, orphaned deletions, and version collisions, and you're running outdated information confidently, without qualification, with zero downstream warning.
This isn't a retrieval problem or an embedding problem. It's a document lifecycle problem that requires its own detection layer on top of your evaluation framework.
Read the full breakdown on detection strategies, architecture patterns for incremental indexing, and streaming RAG approaches:
https://t.co/Fo9ew2d9FK
Follow for more practitioner-focused RAG engineering patterns.
#RAG #VectorDatabases #LLMInfrastructure #AIEngineering #ProductionAI #Retrieval #RagSystems
𝐖𝐡𝐲 𝐘𝐨𝐮𝐫 𝐑𝐀𝐆 𝐒𝐲𝐬𝐭𝐞𝐦 𝐂𝐚𝐧𝐧𝐨𝐭 𝐓𝐞𝐥𝐥 𝐖𝐡𝐞𝐧 𝐈𝐭 𝐈𝐬 𝐖𝐫𝐨𝐧𝐠
Your retrieval pipeline is failing silently right now. You just don't know it yet.
𝐌𝐨𝐬𝐭 𝐩𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧 𝐑𝐀𝐆 𝐬𝐲𝐬𝐭𝐞𝐦𝐬 𝐦𝐞𝐚𝐬𝐮𝐫𝐞 𝐨𝐧𝐞 𝐭𝐡𝐢𝐧𝐠: whether the final answer sounds good. They ignore whether the retrieved context actually contained the right information. This gap - the Evals Blind Spot - means your Chunking Debt, Precision Gap, and retrieval failures are accumulating invisibly until they cause a compliance incident or a customer complaint.
𝐓𝐡𝐞 𝐬𝐭𝐫𝐮𝐜𝐭𝐮𝐫𝐚𝐥 𝐩𝐫𝐨𝐛𝐥𝐞𝐦 𝐢𝐬 𝐛𝐫𝐮𝐭𝐚𝐥: LLMs are too good at generating coherent answers from wrong context. When retrieval returns approximately-correct documents - the right topic, wrong time period; the general policy, missing the specific carve-out - the model produces an answer that is 𝑓𝑎𝑖𝑡ℎ𝑓𝑢𝑙 𝑡𝑜 𝑤ℎ𝑎𝑡 𝑤𝑎𝑠 𝑟𝑒𝑡𝑟𝑖𝑒𝑣𝑒𝑑 but 𝑢𝑛𝑓𝑎𝑖𝑡ℎ𝑓𝑢𝑙 𝑡𝑜 𝑤ℎ𝑎𝑡 𝑖𝑠 𝑡𝑟𝑢𝑒. Your user satisfaction ratings and thumbs-up metrics cannot distinguish between these. Only retrieval-layer metrics can.
You need four things your team probably doesn't have right now:
- 𝐂𝐨𝐧𝐭𝐞𝐱𝐭 𝐑𝐞𝐜𝐚𝐥𝐥 (does retrieved content contain the answer?) - requires ground truth but is the direct signal of retrieval quality
- 𝐂𝐨𝐧𝐭𝐞𝐱𝐭 𝐏𝐫𝐞𝐜𝐢𝐬𝐢𝐨𝐧 (what fraction of retrieved content is actually relevant?) - reference-free, catches noise and reranking failures
- 𝐅𝐚𝐢𝐭𝐡𝐟𝐮𝐥𝐧𝐞𝐬𝐬 (does the generated answer match the retrieved context?) - generation layer, catches hallucination
- 𝐂𝐨𝐧𝐭𝐢𝐧𝐮𝐨𝐮𝐬 𝐦𝐨𝐧𝐢𝐭𝐨𝐫𝐢𝐧𝐠 - not just launch evaluation, but production drift detection as your knowledge base changes
The legal team in this article discovered their contract review assistant had been recommending wrong termination periods for six months. The clause was in the corpus. The embedding was domain-aligned. The reranker had seen it. But no one measured context recall since launch. By the time they checked, they had no idea which other clauses had been silently wrong.
𝑅𝑒𝑎𝑑 𝑡ℎ𝑒 𝑓𝑢𝑙𝑙 𝑔𝑢𝑖𝑑𝑒 𝑜𝑛 𝑐𝑙𝑜𝑠𝑖𝑛𝑔 𝑡ℎ𝑖𝑠 𝑏𝑙𝑖𝑛𝑑 𝑠𝑝𝑜𝑡 - 𝑎𝑛𝑑 ℎ𝑜𝑤 𝑡𝑜 𝑖𝑚𝑝𝑙𝑒𝑚𝑒𝑛𝑡 𝑡ℎ𝑒 𝑚𝑒𝑡𝑟𝑖𝑐 𝑙𝑎𝑦𝑒𝑟 𝑦𝑜𝑢 𝑎𝑐𝑡𝑢𝑎𝑙𝑙𝑦 𝑛𝑒𝑒𝑑:
https://t.co/RV2ZqWM9q0
𝐹𝑜𝑙𝑙𝑜𝑤 𝑓𝑜𝑟 𝑚𝑜𝑟𝑒 𝑝𝑟𝑎𝑐𝑡𝑖𝑡𝑖𝑜𝑛𝑒𝑟-𝑓𝑜𝑐𝑢𝑠𝑒𝑑 𝑅𝐴𝐺 𝑎𝑛𝑑 𝐿𝐿𝑀 𝑖𝑛𝑓𝑟𝑎𝑠𝑡𝑟𝑢𝑐𝑡𝑢𝑟𝑒 𝑑𝑒𝑒𝑝 𝑑𝑖𝑣𝑒𝑠.
#RAG #Evaluation #LLMEngineering #Production #Retrieval #AIEngineering #SystemsDesign
𝐖𝐡𝐲 𝐘𝐨𝐮𝐫 𝐑𝐞𝐫𝐚𝐧𝐤𝐞𝐫 𝐈𝐬 𝐭𝐡𝐞 𝐋𝐚𝐬𝐭 𝐋𝐢𝐧𝐞 𝐘𝐨𝐮 𝐅𝐨𝐫𝐠𝐨𝐭 𝐭𝐨 𝐁𝐮𝐢𝐥𝐝
Retrieval gets you recall. Reranking gets you precision. Skipping it means your LLM reads the wrong documents with complete confidence - and you will not know until production.
Your hybrid retrieval returns 50 candidates. You pass the top 5 to the LLM. The answer is confident, specific, and wrong in the exact way that damages trust: it cites the right topic from the wrong document, or the right document from the wrong time period, or a clause that was superseded months ago and sits two positions below the one that would have answered correctly.
That document was in position 7. Your bi-encoder ranked it there because it measures approximate semantic similarity between independently encoded vectors. Position 7 was close. It was not the answer.
This is the 𝐏𝐫𝐞𝐜𝐢𝐬𝐢𝐨𝐧 𝐆𝐚𝐩 - the quality delta between your first-stage retriever's top-k and the true top-k. Bi-encoders and BM25 are recall engines optimized to find probably relevant documents across millions of candidates. They were never trained to score query-document interaction jointly. They encode each side independently and compute vector distance.
Reranking converts that broad candidate set into precision. It runs a second-stage model that sees both query and document simultaneously - joint attention, full token interaction. Slower by design, but you only run it against 50-100 candidates. Exactly the right place to run it.
The core thesis: 𝐚 𝐑𝐀𝐆 𝐩𝐢𝐩𝐞𝐥𝐢𝐧𝐞 𝐰𝐢𝐭𝐡𝐨𝐮𝐭 𝐚 𝐫𝐞𝐫𝐚𝐧𝐤𝐞𝐫 𝐢𝐬 𝐧𝐨𝐭 𝐚 𝐩𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧 𝐑𝐀𝐆 𝐩𝐢𝐩𝐞𝐥𝐢𝐧𝐞 - 𝐢𝐭 𝐢𝐬 𝐚 𝐝𝐞𝐦𝐨 𝐰𝐚𝐢𝐭𝐢𝐧𝐠 𝐟𝐨𝐫 𝐭𝐡𝐞 𝐪𝐮𝐞𝐫𝐲 𝐭𝐡𝐚𝐭 𝐛𝐫𝐞𝐚𝐤𝐬 𝐢𝐭. Adding a reranker to hybrid retrieval reduces retrieval failure rate from 5.7% to 1.9% - a 67% reduction verified against production benchmarks. That should be the business case for every team that has not built one yet.
Read the full breakdown on how to architect this correctly, identify when reranking actually matters, and implement it without the overhead killing your latency budget.
𝑅𝑒𝑎𝑑 𝑡ℎ𝑒 𝑎𝑟𝑡𝑖𝑐𝑙𝑒:
https://t.co/RZo0OEfTsP
𝐹𝑜𝑙𝑙𝑜𝑤 𝑓𝑜𝑟 𝑚𝑜𝑟𝑒 𝑝𝑟𝑜𝑑𝑢𝑐𝑡𝑖𝑜𝑛 𝑅𝐴𝐺 𝑒𝑛𝑔𝑖𝑛𝑒𝑒𝑟𝑖𝑛𝑔 𝑝𝑎𝑡𝑡𝑒𝑟𝑛𝑠.
#RAGEngineering #RerankerModels #CrossEncoder #LLMProduction #RetrievalAugmentedGeneration #AIEngineering #ProductionAI
𝐖𝐡𝐲 𝐘𝐨𝐮𝐫 𝐄𝐦𝐛𝐞𝐝𝐝𝐢𝐧𝐠𝐬 𝐀𝐫𝐞 𝐭𝐡𝐞 𝐖𝐫𝐨𝐧𝐠 𝐒𝐡𝐚𝐩𝐞 𝐟𝐨𝐫 𝐘𝐨𝐮𝐫 𝐃𝐨𝐦𝐚𝐢𝐧
Your embedding model was trained on the internet. Your documents are not. A healthcare RAG system retrieved regulations with high similarity scores - they were from 2019, legally superseded, and worthless. The model had no way to signal the mismatch.
Here is the hard truth: MTEB leaderboard rankings do not predict domain-specific retrieval quality. The FinMTEB benchmark found statistically insignificant correlation between general MTEB scores and financial domain performance. Top-ranked models do not rank at the top on specialized datasets.
When you embed domain-specific text with a general-purpose model, you lose the semantic distinctions that matter most.
Vocabulary collapse happens silently - "EBITDA covenant breach" lands near "contract violation" instead of financial specifics. Context window truncation erases tail content without warning - a 512-token model silently discards anything beyond 512 tokens. Your chunks are incomplete in the index and you never know.
This is not a retrieval strategy problem. This is not a chunking problem. This is an embedding geometry problem. The wrong model costs you retrieval quality no downstream tuning will recover.
Embedding model selection is a domain alignment decision. Most teams treat it as infrastructure. That mismatch is why RAG systems built for specialized domains fail silently in production.
𝑅𝑒𝑎𝑑 𝑡ℎ𝑒 𝑓𝑢𝑙𝑙 𝑏𝑟𝑒𝑎𝑘𝑑𝑜𝑤𝑛 𝑜𝑛 𝑑𝑜𝑚𝑎𝑖𝑛-𝑠𝑝𝑒𝑐𝑖𝑓𝑖𝑐 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑠𝑒𝑙𝑒𝑐𝑡𝑖𝑜𝑛, 𝑣𝑜𝑐𝑎𝑏𝑢𝑙𝑎𝑟𝑦 𝑐𝑜𝑙𝑙𝑎𝑝𝑠𝑒 𝑚𝑒𝑐ℎ𝑎𝑛𝑖𝑐𝑠, 𝑐𝑜𝑛𝑡𝑒𝑥𝑡 𝑤𝑖𝑛𝑑𝑜𝑤 𝑡𝑟𝑢𝑛𝑐𝑎𝑡𝑖𝑜𝑛, 𝑎𝑛𝑑 𝑡ℎ𝑟𝑒𝑒 𝑐𝑜𝑛𝑐𝑟𝑒𝑡𝑒 𝑑𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑓𝑟𝑎𝑚𝑒𝑤𝑜𝑟𝑘𝑠:
https://t.co/56jadr3cak
𝐹𝑜𝑙𝑙𝑜𝑤 𝑓𝑜𝑟 𝑡ℎ𝑒 𝑛𝑒𝑥𝑡 𝑝𝑎𝑟𝑡 𝑜𝑛 𝑓𝑖𝑛𝑒-𝑡𝑢𝑛𝑖𝑛𝑔 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔𝑠 𝑓𝑜𝑟 𝑝𝑟𝑜𝑑𝑢𝑐𝑡𝑖𝑜𝑛 𝑑𝑜𝑚𝑎𝑖𝑛 𝑓𝑖𝑡.
#RAG #EmbeddingModels #DomainAdaptation #AIEngineering #ProductionAI #RetrievalAugmentedGeneration #NLP
𝐖𝐡𝐲 𝐘𝐨𝐮𝐫 𝐑𝐀𝐆 𝐂𝐡𝐮𝐧𝐤𝐬 𝐀𝐫𝐞 𝐋𝐲𝐢𝐧𝐠 𝐭𝐨 𝐘𝐨𝐮𝐫 𝐑𝐞𝐭𝐫𝐢𝐞𝐯𝐞𝐫
Your retriever is not broken. Your chunks are incomplete.
Three weeks after shipping their internal knowledge base, a compliance team got a confident answer about contractor onboarding - missing the exception clause that changed everything. The exception was in the document. It was ingested. It was embedded. But the chunk containing it had been split at the paragraph boundary where the rule ended and the qualification began. One chunk had the rule. Another had the exception. Neither was complete enough to surface.
This is not an embedding problem. It is not a model problem. It is chunking - and no downstream tuning compensates for broken splits upstream.
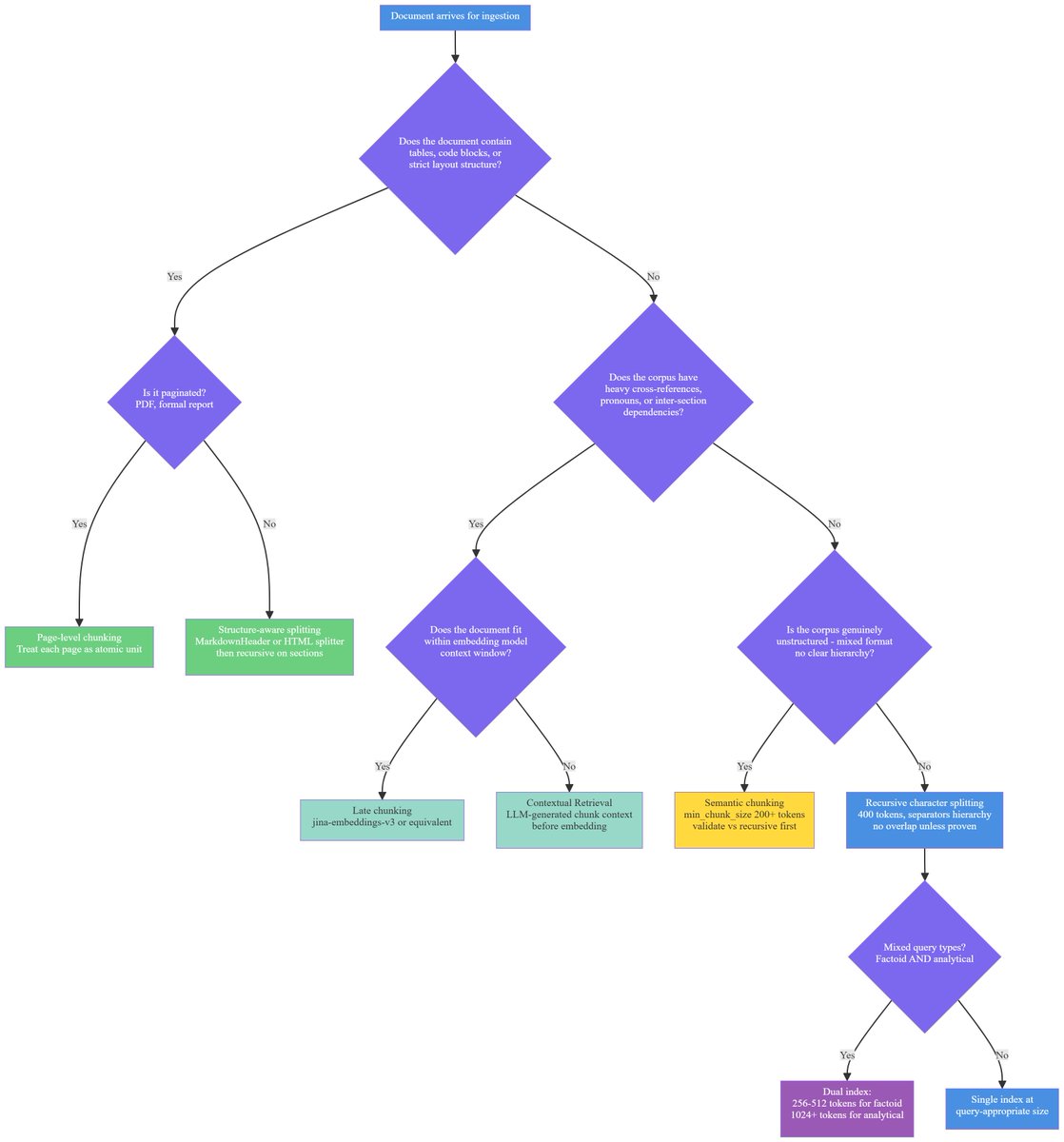
Most teams optimize their embedding model and ignore chunking strategy. But research across 1,080 configurations and 6 domains proves content-aware chunking significantly outperforms naive fixed-length splitting - and the gap widens with scale. You are probably running the wrong chunking strategy. Here is what breaks:
𝐁𝐨𝐮𝐧𝐝𝐚𝐫𝐲 𝐟𝐫𝐚𝐠𝐦𝐞𝐧𝐭𝐚𝐭𝐢𝐨𝐧 - fixed-size cuts destroy semantic units. A three-clause legal exception gets split across chunks. Neither answers properly alone.
𝐀𝐧𝐚𝐩𝐡𝐨𝐫𝐢𝐜 𝐫𝐞𝐟𝐞𝐫𝐞𝐧𝐜𝐞 𝐟𝐚𝐢𝐥𝐮𝐫𝐞 - chunks embedded in isolation lose document context. "Berlin" in chunk 4. "Its population exceeds 3.85 million" in chunk 5. When chunk 5 is embedded alone, "Berlin" is gone from the encoding. The retriever matches nothing.
𝐓𝐚𝐛𝐥𝐞 𝐝𝐞𝐬𝐭𝐫𝐮𝐜𝐭𝐢𝐨𝐧 - fixed-size tokenization linearizes two-dimensional data. Headers separate from values. Cells lose row and column context. Page-level chunking measured 0.648 accuracy; token-based chunking failed.
𝐂𝐨𝐧𝐭𝐞𝐱𝐭 𝐜𝐥𝐢𝐟𝐟 - there is a measurable threshold around 2,500 tokens where retrieval degrades. Factoid queries need 256-512 token chunks. Analytical queries need 1024+. One chunk size is wrong for both.
Read the full breakdown on practical chunking strategies - fixed-size, recursive, semantic, hierarchical, late, and contextual - and when each one silently breaks your system.
https://t.co/O1CxBTTXT4
Follow for more practitioner-focused RAG engineering insights.
#RAG #ChunkingStrategy #LLMEngineering #RetrievalAugmentedGeneration #AIEngineering #DocumentProcessing #ProductionAI
𝐖𝐡𝐲 𝐘𝐨𝐮𝐫 𝐑𝐀𝐆 𝐒𝐲𝐬𝐭𝐞𝐦 𝐈𝐬 𝐔𝐬𝐢𝐧𝐠 𝐭𝐡𝐞 𝐖𝐫𝐨𝐧𝐠 𝐑𝐞𝐭𝐫𝐢𝐞𝐯𝐚𝐥 𝐒𝐭𝐫𝐚𝐭𝐞𝐠𝐲
𝐴 𝑝𝑟𝑎𝑐𝑡𝑖𝑡𝑖𝑜𝑛𝑒𝑟'𝑠 𝑔𝑢𝑖𝑑𝑒 𝑡𝑜 𝑣𝑒𝑐𝑡𝑜𝑟-𝑏𝑎𝑠𝑒𝑑, 𝑣𝑒𝑐𝑡𝑜𝑟𝑙𝑒𝑠𝑠, ℎ𝑦𝑏𝑟𝑖𝑑, 𝑐𝑜𝑟𝑟𝑒𝑐𝑡𝑖𝑣𝑒, 𝑎𝑛𝑑 𝑎𝑔𝑒𝑛𝑡𝑖𝑐 𝑟𝑒𝑡𝑟𝑖𝑒𝑣𝑎𝑙 𝑎𝑟𝑐ℎ𝑖𝑡𝑒𝑐𝑡𝑢𝑟𝑒𝑠.
Your LLM generated a confident, well-structured answer. The problem is the context it was handed - retrieved by the wrong method for the wrong query type. When RAG fails, retrieval is the culprit 73% of the time, not generation. Yet most teams default to the same retrieval strategy regardless of what they're building: chunk, embed, vector search, pass to LLM. Done.
That default costs you more than you realize.
The RAG landscape has fractured into five distinct paradigms - vector-based, vectorless, hybrid, corrective, and agentic - each with fundamentally different cost, latency, accuracy, and failure profiles. Picking the wrong one locks in a compounding tax: inflated token spend, unnecessary latency, answers grounded in the wrong documents. The uncomfortable truth is that "which vector database" is the wrong question. The right question is "should I be using vector retrieval at all?"
Vector search sacrifices precision for recall. It finds semantically similar text, not necessarily correct text. A query for "Q1 2025 revenue" surfaces Q2 projections because embeddings place them close in latent space. Hybrid retrieval - combining vector and BM25 with reranking - closes this gap measurably. Recent benchmarks show hybrid + cross-encoder reranking achieves 39% better Recall@5 than dense-only retrieval on financial documents. Vectorless patterns (keyword, SQL, tree-based) outperform vectors entirely on structured data, technical terminology, and hierarchical documents.
The default vector-only approach works for large unstructured corpora only. For everything else - structured data, exact identifiers, specialized terminology, financial documents - you're paying a retrieval tax for the wrong architecture.
Read the full breakdown of each paradigm, their failure modes, and when to use them:
https://t.co/OM1WuMVCdP
Follow for more practitioner-focused AI engineering insights.
#RAG #VectorSearch #HybridRetrieval #LLMInfrastructure #ProductionAI #AIEngineering #Retrieval
𝐇𝐨𝐰 𝐭𝐨 𝐊𝐧𝐨𝐰 𝐘𝐨𝐮𝐫 𝐂𝐥𝐚𝐮𝐝𝐞 𝐂𝐨𝐝𝐞 𝐒𝐞𝐭𝐮𝐩 𝐀𝐜𝐭𝐮𝐚𝐥𝐥𝐲 𝐖𝐨𝐫𝐤𝐬: 𝐓𝐞𝐬𝐭𝐢𝐧𝐠 𝐁𝐞𝐲𝐨𝐧𝐝 𝐭𝐡𝐞 𝐒𝐤𝐢𝐥𝐥 𝐋𝐞𝐯𝐞𝐥
Your skill evals pass. Your hooks look clean. Your CLAUDE.md is well-structured. Then a Claude Code update ships, or Anthropic releases a model change, and suddenly your agent is producing worse code - more iteration loops, shallower reasoning, outputs that pass type checks but miss intent. You have no systematic way to know until it breaks in production.
The problem: skill evals test components in isolation. They do not test your complete system - CLAUDE.md + skills + hooks + subagents + model version, all interacting. When that system degrades through a product update, a model change, or accumulated config drift, individual skills still pass their evals while overall output quality tanks.
Workflow-level evals catch what skill evals miss. They exercise your full setup against real tasks and grade outputs against criteria that matter - not just type correctness, but whether the code solves the actual problem. This is what separates teams that detected the March-April 2026 Claude Code regression from those who only felt it as vague inconsistency.
The testing pyramid has three layers: hook tests (fastest, run on every change), skill evals (fast, run on skill modifications), and workflow evals (slower, run on schedule or before ship). Most teams have only the middle layer. The article walks through what to test in each layer, how to write tests that work for agent behavior, how to run them automatically, and how to interpret drops in pass rates as early warning signals.
𝑅𝑒𝑎𝑑 𝑡ℎ𝑒 𝑓𝑢𝑙𝑙 𝑔𝑢𝑖𝑑𝑒 𝑜𝑛 𝑤𝑜𝑟𝑘𝑓𝑙𝑜𝑤 𝑒𝑣𝑎𝑙𝑠, 𝑗𝑢𝑑𝑔𝑒 𝑎𝑔𝑒𝑛𝑡𝑠, 𝑟𝑒𝑔𝑟𝑒𝑠𝑠𝑖𝑜𝑛 𝑏𝑎𝑠𝑒𝑙𝑖𝑛𝑒𝑠, 𝑎𝑛𝑑 ℎ𝑒𝑎𝑑𝑙𝑒𝑠𝑠 𝑒𝑥𝑒𝑐𝑢𝑡𝑖𝑜𝑛 𝑝𝑎𝑡𝑡𝑒𝑟𝑛𝑠:
https://t.co/T714mGM9Rz
𝐹𝑜𝑙𝑙𝑜𝑤 𝑓𝑜𝑟 𝑚𝑜𝑟𝑒 𝐶𝑙𝑎𝑢𝑑𝑒 𝐶𝑜𝑑𝑒 𝑒𝑛𝑔𝑖𝑛𝑒𝑒𝑟𝑖𝑛𝑔 𝑝𝑎𝑡𝑡𝑒𝑟𝑛𝑠 𝑎𝑛𝑑 𝑝𝑟𝑜𝑑𝑢𝑐𝑡𝑖𝑜𝑛 𝑝𝑙𝑎𝑦𝑏𝑜𝑜𝑘𝑠.
#ClaudeCode #AIEngineering #AgenticAI #Testing #MLOps #LLMProduction #WorkflowEvals
𝐂𝐥𝐚𝐮𝐝𝐞 𝐂𝐨𝐝𝐞 𝐎𝐛𝐬𝐞𝐫𝐯𝐚𝐛𝐢𝐥𝐢𝐭𝐲: 𝐖𝐡𝐞𝐧 𝐘𝐨𝐮𝐫 𝐀𝐈 𝐀𝐠𝐞𝐧𝐭 𝐆𝐨𝐞𝐬 𝐒𝐢𝐥𝐞𝐧𝐭 ̲(̲𝐏̲𝐚̲𝐫̲𝐭̲ ̲𝟕̲ ̲𝐨̲𝐟̲ ̲𝐒̲𝐞̲𝐫̲𝐢̲𝐞̲𝐬̲ ̲𝐓̲𝐡̲𝐞̲ ̲𝐂̲𝐥̲𝐚̲𝐮̲𝐝̲𝐞̲ ̲𝐂̲𝐨̲𝐝̲𝐞̲ ̲𝐄̲𝐧̲𝐠̲𝐢̲𝐧̲𝐞̲𝐞̲𝐫̲𝐢̲𝐧̲𝐠̲ ̲𝐏̲𝐥̲𝐚̲𝐲̲𝐛̲𝐨̲𝐨̲𝐤̲ ̲)̲
You've deployed an agentic system using Claude, it's working in dev, and then production hits you with cryptic errors and silent failures. You can't see what Claude is thinking, what it's doing mid-task, or where it actually broke. You're flying blind.
This isn't a Claude problem - it's an observability problem. Most teams treat AI agents like black boxes, logging inputs and outputs. That leaves huge gaps.
Here's what actually matters:
- Token usage patterns reveal inefficiency and cost bleed before they spiral
- Intermediate reasoning steps show you where the model actually went wrong - not just that it failed
- Tool call chains expose logic errors that look like model hallucinations but aren't
- Latency breakdowns tell you if delays are API calls, tool execution, or token processing
𝐓𝐡𝐞 𝐫𝐞𝐚𝐥 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞: you need observability that's lightweight enough to run in production but detailed enough to debug agentic behavior at the reasoning level. Standard application monitoring wasn't built for this.
𝑅𝑒𝑎𝑑 𝑡ℎ𝑒 𝑓𝑢𝑙𝑙 𝑏𝑟𝑒𝑎𝑘𝑑𝑜𝑤𝑛 𝑜𝑛 𝑝𝑟𝑎𝑐𝑡𝑖𝑐𝑎𝑙 𝑜𝑏𝑠𝑒𝑟𝑣𝑎𝑏𝑖𝑙𝑖𝑡𝑦 𝑠𝑡𝑟𝑎𝑡𝑒𝑔𝑖𝑒𝑠 𝑓𝑜𝑟 𝐶𝑙𝑎𝑢𝑑𝑒-𝑏𝑎𝑠𝑒𝑑 𝑠𝑦𝑠𝑡𝑒𝑚𝑠:
https://t.co/hkX2PvrAvY
𝐹𝑜𝑙𝑙𝑜𝑤 𝑓𝑜𝑟 𝑚𝑜𝑟𝑒 𝑝𝑟𝑎𝑐𝑡𝑖𝑡𝑖𝑜𝑛𝑒𝑟-𝑓𝑜𝑐𝑢𝑠𝑒𝑑 𝐴𝐼 𝑒𝑛𝑔𝑖𝑛𝑒𝑒𝑟𝑖𝑛𝑔 𝑝𝑎𝑡𝑡𝑒𝑟𝑛𝑠 𝑡ℎ𝑎𝑡 𝑎𝑐𝑡𝑢𝑎𝑙𝑙𝑦 𝑠𝑐𝑎𝑙𝑒.
#AgenticAI #AIEngineering #Claude #Observability #Debugging #ProductionAI #MLOps
𝐓𝐡𝐞 𝐂̲𝐥̲𝐚̲𝐮̲𝐝̲𝐞̲ ̲𝐂̲𝐨̲𝐝̲𝐞̲ 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠 𝐏𝐥𝐚𝐲𝐛𝐨𝐨𝐤 (𝐒𝐄𝐑𝐈𝐄𝐒 𝐨𝐟 𝟔 𝐚𝐫𝐭𝐢𝐜𝐥𝐞𝐬/𝐠𝐮𝐢𝐝𝐞𝐬)
Most engineers treat Claude as a code completion tool. That's leaving 80% of its capabilities on the table.
The real win isn't faster typing - it's better architectural decisions, faster iteration cycles, and catching design problems before they become production nightmares.
Here's what separates practitioners who extract real value:
- Prompt structure matters more than prompt length. Claude responds best to explicit context, clear constraints, and staged reasoning - not magical incantations
- Context windows are a feature, not a bug. You can feed entire codebases, design docs, and error logs to get contextually aware refactoring and debugging
- Knowing when Claude breaks down - refactoring legacy systems, handling ambiguous requirements, cross-language migrations - is as important as knowing when to lean on it
- The feedback loop is where the work happens. One prompt rarely ships. Iteration, validation, and incremental refinement separate production-ready code from plausible-looking outputs
This playbook cuts through the hype and gives you the practical patterns that actually work.
𝐑𝐞𝐚𝐝 𝐭𝐡𝐞 𝐟𝐮𝐥𝐥 𝐠𝐮𝐢𝐝𝐞: https://t.co/3YO2PhbzYc
𝐅𝐨𝐥𝐥𝐨𝐰 𝐦𝐞 𝐟𝐨𝐫 𝐦𝐨𝐫𝐞 𝐩𝐫𝐚𝐜𝐭𝐢𝐭𝐢𝐨𝐧𝐞𝐫-𝐟𝐨𝐜𝐮𝐬𝐞𝐝 𝐀𝐈 𝐞𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠 𝐢𝐧𝐬𝐢𝐠𝐡𝐭𝐬.
#AIEngineering #LLMs #Claude #CodeGeneration #SoftwareArchitecture #EngineeringPractices #ProductionAI
𝐒𝐮𝐛𝐚𝐠𝐞𝐧𝐭𝐬: 𝐇𝐨𝐰 𝐭𝐨 𝐑𝐮𝐧 𝐏𝐚𝐫𝐚𝐥𝐥𝐞𝐥𝐢𝐬𝐦 𝐈𝐧𝐬𝐢𝐝𝐞 𝐚 𝐒𝐢𝐧𝐠𝐥𝐞 𝐀𝐠𝐞𝐧𝐭 𝐒𝐞𝐬𝐬𝐢𝐨𝐧 𝐖𝐢𝐭𝐡𝐨𝐮𝐭 𝐏𝐨𝐢𝐬𝐨𝐧𝐢𝐧𝐠 𝐭𝐡𝐞 𝐏𝐚𝐫𝐞𝐧𝐭
Your agent is four hours into a complex session. It has read 40 files, run a test suite, drafted three variants, explored two dead ends. Now it's auditing a diff it can barely see anymore because its context is drowning in noise from everything it did before. The model is still smart. The context is not.
This is the core failure mode of single-context agents at scale: every operation they perform is also an operation they must carry forever. The exploration that found a dead end still occupies 8,000 tokens. The test output still sits in the thread. The rejected draft is still there. The parent agent is paying for every decision it ever made, not just the ones that matter now.
Subagents solve this at the architectural level. Not by making the parent smarter or compressing history, but by delegating focused work to child agents that spawn in fresh context windows, do their work, and return only the result. The parent gets approximately 400 tokens of summary back. The child's entire working process - every file read, every intermediate step, every failed attempt - is discarded. The parent stays sharp. The child burns its own context so the parent doesn't have to.
This is not a convenience feature. It is the mechanism that makes sustained, high-quality agent work possible at production time horizons.
The article walks through why single-context agents break at depth, the exact subagent contract, decision frameworks for spawn-or-stay-inline, and practical patterns for isolation without overhead.
𝐑𝐞𝐚𝐝 𝐭𝐡𝐞 𝐟𝐮𝐥𝐥 𝐚𝐫𝐭𝐢𝐜𝐥𝐞: https://t.co/g9Dc2QOL80
𝐅𝐨𝐥𝐥𝐨𝐰 𝐟𝐨𝐫 𝐩𝐫𝐚𝐜𝐭𝐢𝐭𝐢𝐨𝐧𝐞𝐫-𝐟𝐨𝐜𝐮𝐬𝐞𝐝 𝐀𝐈 𝐞𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠: 𝐡𝐭𝐭𝐩𝐬://𝐥𝐢𝐧𝐤𝐞𝐝𝐢𝐧.𝐜𝐨𝐦/𝐢𝐧/𝐫𝐚𝐧𝐣𝐚𝐧𝐤𝐮𝐦𝐚𝐫
#SubAgents #AgentArchitecture #ContextEngineering #AIEngineering #MultiAgent #LLMProduction #PromptEngineering
𝐅𝐨𝐮𝐫 𝐇𝐚𝐛𝐢𝐭𝐬 𝐟𝐫𝐨𝐦 𝐭𝐡𝐞 𝐂𝐫𝐞𝐚𝐭𝐨𝐫 𝐨𝐟 𝐂𝐥𝐚𝐮𝐝𝐞 𝐂𝐨𝐝𝐞 𝐓𝐡𝐚𝐭 𝐖𝐢𝐥𝐥 𝐂𝐡𝐚𝐧𝐠𝐞 𝐇𝐨𝐰 𝐘𝐨𝐮 𝐒𝐡𝐢𝐩
Most developers using Claude Code treat it like a pair programmer. Boris Cherny treats it like an engineer you delegate to. That difference in operating model is why he ships 20-30 PRs a day while running 10-15 parallel sessions. It is not the configuration. It is the four habits.
His first PR at Anthropic got rejected for being hand-written. At the world's leading AI lab, surrounded by engineers who expected code from AI, he had typed it himself. That moment catalyzed a complete rethinking of how to work with an AI coding agent at scale.
The four habits are simple. Treat context like a resource you manage, not a recording of everything. Brief Claude the way you brief an engineer - clear goal, constraints, success criteria. Run five worktrees in parallel. Automate the repetitive parts.
Each habit addresses a specific failure mode. Together they form a complete operating model.
https://t.co/4MCVfxvp1M
Read the full breakdown and start shipping faster this week.
𝐹𝑜𝑙𝑙𝑜𝑤 𝑓𝑜𝑟 𝑚𝑜𝑟𝑒 𝑝𝑟𝑎𝑐𝑡𝑖𝑡𝑖𝑜𝑛𝑒𝑟-𝑓𝑜𝑐𝑢𝑠𝑒𝑑 𝐴𝐼 𝑒𝑛𝑔𝑖𝑛𝑒𝑒𝑟𝑖𝑛𝑔 𝑝𝑎𝑡𝑡𝑒𝑟𝑛𝑠.
#ClaudeCode #AIEngineering #ProductivityHacks #DeveloperWorkflow #Automation #AgenticAI #CodingPatterns
𝐇𝐚𝐫𝐧𝐞𝐬𝐬 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠: 𝐓𝐡𝐞 𝐌𝐢𝐬𝐬𝐢𝐧𝐠 𝐋𝐚𝐲𝐞𝐫 𝐁𝐞𝐭𝐰𝐞𝐞𝐧 𝐋𝐋𝐌𝐬 𝐚𝐧𝐝 𝐏𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧 𝐒𝐲𝐬𝐭𝐞𝐦𝐬
You shipped a "production-ready" LLM feature. The demo was flawless. Then at 2am on Tuesday your agent gets stuck in a loop, wrapped a number in quotes, and your downstream system collapsed. The model worked fine. Your system didn't.
This is the core problem most teams miss: 𝐋𝐋𝐌𝐬 𝐚𝐫𝐞 𝐧𝐨𝐭 𝐫𝐞𝐥𝐢𝐚𝐛𝐥𝐞 𝐬𝐨𝐟𝐭𝐰𝐚𝐫𝐞 𝐜𝐨𝐦𝐩𝐨𝐧𝐞𝐧𝐭𝐬 - 𝐭𝐡𝐞𝐲'𝐫𝐞 𝐩𝐫𝐨𝐛𝐚𝐛𝐢𝐥𝐢𝐬𝐭𝐢𝐜 𝐞𝐧𝐠𝐢𝐧𝐞𝐬. You can't wire them directly to production. You need a harness.
Prompt engineering is local optimization. You tune inputs and hope outputs cooperate. Harness Engineering is systems design. It's the deterministic wrapper around the probabilistic engine - the execution layer that prevents the model from breaking your system regardless of what it outputs.
Most teams confuse frameworks (LangChain, LangGraph, CrewAI) with harnesses. Frameworks assemble your agent. A harness governs how it executes in production - managing context, enforcing constraints, validating output, gating execution, handling failures. You can build a framework-based agent without a harness. That's why agents that demo well fail in production.
A production harness is seven layered execution pipelines: Normalization, Context Orchestration, Constraints, Gated Execution, Validation & Repair, Circuit Breaking, and State Management. Each layer absorbs a specific failure mode before it hits users. Skip any layer and you're running on luck, not design.
The shift in mental model: a good prompt makes a demo work. A good harness makes a product survive.
𝑅𝑒𝑎𝑑 𝑡ℎ𝑒 𝑓𝑢𝑙𝑙 𝑏𝑟𝑒𝑎𝑘𝑑𝑜𝑤𝑛 𝑜𝑛 𝑎𝑟𝑐ℎ𝑖𝑡𝑒𝑐𝑡𝑢𝑟𝑒, 𝑡𝑟𝑎𝑑𝑒𝑜𝑓𝑓𝑠, 𝑎𝑛𝑑 𝑒𝑎𝑐ℎ 𝑙𝑎𝑦𝑒𝑟 𝑖𝑛 𝑝𝑟𝑎𝑐𝑡𝑖𝑐𝑒:
https://t.co/JFNNmw4ZvS
𝐹𝑜𝑙𝑙𝑜𝑤 𝑓𝑜𝑟 𝑡ℎ𝑒 𝑛𝑒𝑥𝑡 𝑝𝑎𝑟𝑡𝑠 - 𝑤𝑒 𝑔𝑜 𝑑𝑒𝑒𝑝 𝑜𝑛 𝑒𝑎𝑐ℎ 𝑙𝑎𝑦𝑒𝑟.
#HarnessEngineering #LLMReliability #AIEngineering #ProductionAI #SystemsDesign #AIArchitecture #AgenticAI
𝐀𝐠𝐞𝐧𝐭 𝐒𝐤𝐢𝐥𝐥𝐬 𝐀𝐫𝐞 𝐍𝐨𝐭 𝐏𝐫𝐨𝐦𝐩𝐭𝐬. 𝐓𝐡𝐞𝐲 𝐀𝐫𝐞 𝐏𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧 𝐊𝐧𝐨𝐰𝐥𝐞𝐝𝐠𝐞 𝐈𝐧𝐟𝐫𝐚𝐬𝐭𝐫𝐮𝐜𝐭𝐮𝐫𝐞.
Your agent nails the task in testing. It fails in production not because the model broke - but because you explained the workflow once, in one session, and it forgot. The next engineer on your team explains it differently. The third engineer tries yet another phrasing. You are re-teaching your agent everything it needs to know from scratch on every single call. This is not a prompt engineering problem. It is a knowledge persistence problem - and there is now a solved format for it.
Agent Skills - the SKILL.md standard that Anthropic introduced and now runs across Claude Code, GitHub Copilot, and other frameworks - are how you make agent expertise durable, testable, and portable. A skill is a filesystem module that packages your team's workflows, conventions, and domain expertise into something the agent discovers automatically and loads only when relevant. Not per-session instructions. Not API access. Persistent knowledge infrastructure.
The core insight: teams that treat skills as optional will keep paying the re-teaching tax. Every call resets what the agent knows about your standards, your processes, your non-negotiable patterns. Teams that build skills deliberately will compound agent quality across every workflow they own. Verifier skills alone deliver a 2-3x quality multiplier because they encode exactly how your team defines done - which tests block, which documentation fields are required, how to format the output - and the agent stops forgetting.
Skills solve the failure mode most teams don't even name: variability from different prompts, drift as context gets dropped, maintenance chaos when your stack changes. A skill is a single SKILL.md file with trigger metadata and procedural knowledge. Load it on demand. Version it. Test it. Iterate on it. Stop paying taxes.
𝑅𝑒𝑎𝑑 𝑡ℎ𝑒 𝑓𝑢𝑙𝑙 𝑏𝑟𝑒𝑎𝑘𝑑𝑜𝑤𝑛 𝑜𝑛 ℎ𝑜𝑤 𝑠𝑘𝑖𝑙𝑙𝑠 𝑑𝑖𝑓𝑓𝑒𝑟 𝑓𝑟𝑜𝑚 𝑝𝑟𝑜𝑚𝑝𝑡𝑠, 𝑀𝐶𝑃 𝑠𝑒𝑟𝑣𝑒𝑟𝑠, 𝑎𝑛𝑑 𝑝𝑟𝑜𝑗𝑒𝑐𝑡 𝑐𝑜𝑛𝑡𝑒𝑥𝑡 - 𝑎𝑛𝑑 ℎ𝑜𝑤 𝑡𝑜 𝑏𝑢𝑖𝑙𝑑 𝑦𝑜𝑢𝑟 𝑓𝑖𝑟𝑠𝑡 𝑜𝑛𝑒:
https://t.co/7JiKsjR0hZ
𝐹𝑜𝑙𝑙𝑜𝑤 𝑓𝑜𝑟 𝑚𝑜𝑟𝑒 𝑜𝑛 𝑝𝑟𝑜𝑑𝑢𝑐𝑡𝑖𝑜𝑛 𝐴𝐼 𝑠𝑦𝑠𝑡𝑒𝑚𝑠 𝑎𝑛𝑑 𝑎𝑔𝑒𝑛𝑡𝑖𝑐 𝑖𝑛𝑓𝑟𝑎𝑠𝑡𝑟𝑢𝑐𝑡𝑢𝑟𝑒.
#AgentSkills #AIEngineering #LLMProduction #AgenticAI #KnowledgeManagement #SkillDevelopment #MLOps
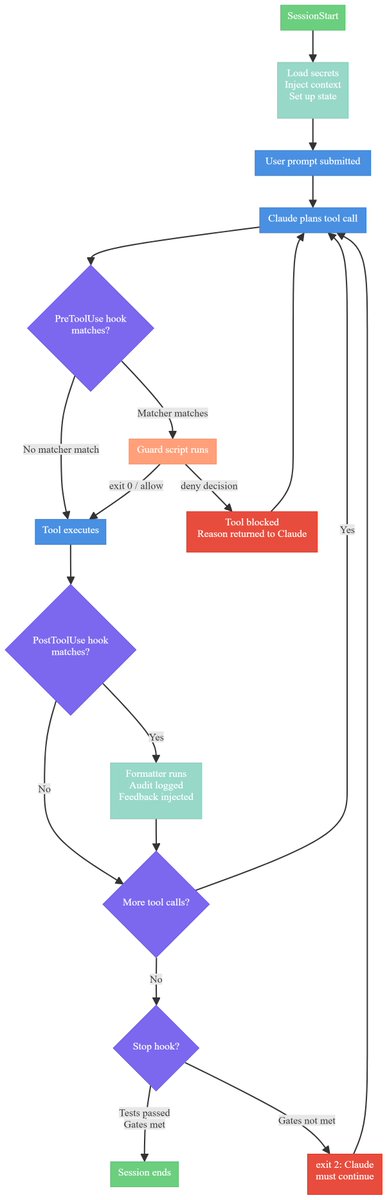
𝐇𝐨𝐨𝐤𝐬: 𝐓𝐡𝐞 𝐄𝐧𝐟𝐨𝐫𝐜𝐞𝐦𝐞𝐧𝐭 𝐋𝐚𝐲𝐞𝐫 𝐓𝐡𝐚𝐭 𝐓𝐮𝐫𝐧𝐬 𝐀𝐠𝐞𝐧𝐭 𝐏𝐨𝐥𝐢𝐜𝐲 𝐈𝐧𝐭𝐨 𝐀𝐠𝐞𝐧𝐭 𝐅𝐚𝐜𝐭
Prompts suggest. Hooks enforce. Until you know the difference, your agent's safety guarantees are probabilistic.
A developer's entire Mac was wiped because Claude executed rm -rf ~/ during a cleanup task. The model had read the safety policy. It had followed it hundreds of times. In one context-heavy session, it didn't. This is the problem: prompts are suggestions. They cannot be trusted to enforce critical rules when conversations get complex, contexts shift, or the framing of a task changes subtly.
Hooks are different. They run as a separate enforcement layer at fixed points in your agent's lifecycle - before tools execute, after they complete, at session start, at completion. A PreToolUse hook that blocks destructive commands does not rely on the model remembering your policy. It runs every time. The model cannot reason around it. The model cannot forget it.
This is 𝐩𝐨𝐥𝐢𝐜𝐲-𝐚𝐬-𝐜𝐨𝐝𝐞 𝐟𝐨𝐫 𝐚𝐠𝐞𝐧𝐭𝐬: every rule you trust to a prompt is a rule the agent 𝑐𝑎𝑛 violate. Every rule encoded in a hook is a rule the agent 𝑐𝑎𝑛𝑛𝑜𝑡 violate. The difference between probabilistic safety and actual enforcement.
The article breaks down the four lifecycle events that matter - SessionStart, PreToolUse, PostToolUse, and Stop - with concrete examples of how to build guard scripts that make agent behavior deterministic. You'll see exactly how to configure hooks in .claude/settings.json, why prompts fail in production, and how this applies beyond Claude Code to any agentic system.
𝐑𝐞𝐚𝐝 𝐭𝐡𝐞 𝐟𝐮𝐥𝐥 𝐚𝐫𝐭𝐢𝐜𝐥𝐞: https://t.co/YBwQ0jKoSV
𝐹𝑜𝑙𝑙𝑜𝑤 𝑓𝑜𝑟 𝑚𝑜𝑟𝑒 𝑝𝑟𝑎𝑐𝑡𝑖𝑡𝑖𝑜𝑛𝑒𝑟-𝑓𝑜𝑐𝑢𝑠𝑒𝑑 𝐴𝐼 𝑒𝑛𝑔𝑖𝑛𝑒𝑒𝑟𝑖𝑛𝑔 𝑖𝑛𝑠𝑖𝑔ℎ𝑡𝑠.
#AgenticAI #AIEngineering #PolicyAsCode #AgentSecurity #LLMProduction #ClaudeCode #Enforcement
𝐓𝐡𝐞 𝐏𝐚𝐧𝐨𝐩𝐭𝐢𝐜𝐨𝐧 𝐀𝐠𝐞𝐧𝐭: 𝐇𝐨𝐰 𝐀𝐠𝐞𝐧𝐭𝐢𝐜 𝐀𝐈 𝐌𝐚𝐤𝐞𝐬 𝐒𝐮𝐫𝐯𝐞𝐢𝐥𝐥𝐚𝐧𝐜𝐞 𝐓𝐫𝐢𝐯𝐢𝐚𝐥 𝐚𝐧𝐝 𝐈𝐧𝐯𝐢𝐬𝐢𝐛𝐥𝐞
Your company just deployed a helpful AI assistant that reads your emails, accesses your calendar, and summarizes Slack conversations. It answers "What meetings do I have?" instantly. Productivity goes up. Nobody asks what else it's seeing or who has access to the patterns it detects.
Here's the problem: You've built perfect surveillance infrastructure and called it productivity software.
Unlike traditional monitoring that requires expensive human analysts or narrow keyword matching, agentic AI breaks that trade-off completely. An agent with email access understands semantic meaning, extracts relationships, and infers intent across thousands of messages. It detects which projects are struggling based on communication frequency and tone. A single agent with calendar, email, Slack, and database access creates comprehensive behavioral profiling as a side effect of being helpful. Each component is defensible individually. Combined, they're total visibility.
The surveillance happens invisibly because nobody queries the agent asking "Build a behavioral profile of employee X." They ask "What's the status of project Y?" and the agent builds the profile anyway. Traditional surveillance creates audit trails. Agent-based surveillance creates none—it's just the agent doing its job.
𝑅𝑒𝑎𝑑 𝑡ℎ𝑒 𝑓𝑢𝑙𝑙 𝑏𝑟𝑒𝑎𝑘𝑑𝑜𝑤𝑛 𝑜𝑓 ℎ𝑜𝑤 𝑡ℎ𝑖𝑠 𝑎𝑐𝑡𝑢𝑎𝑙𝑙𝑦 𝑤𝑜𝑟𝑘𝑠 𝑖𝑛 𝑝𝑟𝑜𝑑𝑢𝑐𝑡𝑖𝑜𝑛 𝑎𝑛𝑑 𝑤ℎ𝑎𝑡 𝑖𝑡 𝑚𝑒𝑎𝑛𝑠 𝑓𝑜𝑟 𝑦𝑜𝑢𝑟 𝑖𝑛𝑓𝑟𝑎𝑠𝑡𝑟𝑢𝑐𝑡𝑢𝑟𝑒:
https://t.co/lXXyWQzfxB
𝐹𝑜𝑙𝑙𝑜𝑤 𝑓𝑜𝑟 𝑚𝑜𝑟𝑒 𝑝𝑟𝑎𝑐𝑡𝑖𝑡𝑖𝑜𝑛𝑒𝑟 𝑖𝑛𝑠𝑖𝑔ℎ𝑡𝑠 𝑜𝑛 𝐴𝐼 𝑠𝑦𝑠𝑡𝑒𝑚𝑠 𝑡ℎ𝑎𝑡 𝑎𝑐𝑡𝑢𝑎𝑙𝑙𝑦 𝑚𝑎𝑡𝑡𝑒𝑟.
#AIEthics #Surveillance #AgenticAI #PrivacyMatters #AIGovernance #EnterpriseAI #DigitalColonialism