Great Stanford + MIT + Harvard + Anthropic paper.
Gives a clear training-based reason for why larger models learn abilities smaller models miss.
Says bigger AI models learn rare skills because they forget them less during training, their extra space protects weak learning signals.
The authors say the issue is not just whether a small model could represent the task, but whether training lets it keep that task while many common tasks keep pushing on the same limited parts.
Their core idea is that common tasks take up the model’s neurons first, so rare tasks get overwritten before they appear often enough to build into stable knowledge.
In a crowded data mixture, common patterns get first claim on the model’s internal machinery.
Small models may briefly pick up a rare signal, but the next wave of common-task updates overwrites it before the signal appears again.
They tested this first with controlled toy tasks where they could change how rare and complex each task was, then with OLMo language models from 4M to 4B parameters.
The main result is that bigger models learned low-frequency tasks much better, kept more task features inside their representations, and showed less gradient interference, which means common-task updates disturbed rare-task learning less.
Larger models can remember weak rare signals long enough to turn them into real learned skills.
----
Link – arxiv. org/abs/2605.29548
Title: "Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention"
// Continual Learning Bench //
One of the research areas with lots of investments is continual learning.
While there are many efforts, there is very little progress in measuring it.
So the big question is, do dedicated memory systems actually make agents learn from experience?
Continual Learning Bench says not yet. Across six expert-validated domains with shared learnable structure, naive in-context learning outperforms systems purpose-built for memory management.
CL-Bench introduces a gain metric that isolates genuine learning from prior capability, then shows agents frequently overfit to immediate observations or fail to reuse knowledge across instances.
If a plain ICL baseline beats your memory architecture, the architecture is adding overhead rather than learning.
Paper: https://t.co/iFd5SZFe3O
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
🚨 Anthropic just showed a 27-minute workshop on how to actually do prompts for Claude.
Taught by the people who built it.
Free. No registration. No paywall.
I've seen $300 courses that don't cover what they teach in the first 8 minutes.
Watch it and bookmark it now.
This was one of the standout AI papers of the week.
(bookmark it)
It tackles a question most self-improving AI agents ignore: is the agent actually discovering anything, or just remixing what it already knows?
How can you tell whether the agent is doing real discovery or just confident retrieval?
The authors give three clean buckets:
- Retrieval is looking something up in a notebook you already have.
- Search is combining tools you already own in new ways.
- Discovery is inventing a new concept that wasn't in your toolkit before.
The issue is that most agents stop at the first two.
The math behind their definition (category theory plus a left Kan extension, if you care) is basically a bookkeeping trick to ask: could the old version of me have produced this result? If yes, it's not discovery. If no, something genuinely new showed up.
They build a Builder/Breaker agent that studies protein mechanics. Over four rounds, the model's fit accuracy actually drops (R² goes from 0.48 to 0.68 to 0.54 to 0.41). At first glance, that looks like a failing agent.
It isn't.
The agent kept taking on harder proteins and rewriting its theory to cover them. Data grew almost 10x while the model code grew only 1.3x. A smaller theory covering a bigger world is exactly what good science looks like.
Why does it matter?
If you optimize for accuracy alone, your self-improving agent will just settle into easy benchmarks and stop. This paper offers a cleaner success signal and asks whether the agent is compressing more of the world into less code over time.
Paper: https://t.co/Vb4TcCb5YD
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
New Google paper: A forecast needs context, not just history.
Some patterns are caused by events, not time. Nexus reframes forecasting as a reasoning problem, where events and numbers have to explain each other.
Nexus argues that forecasting improves when models read the world around the numbers, not just the numbers themselves.
In the Zillow tests, one Claude-based version cut average MAPE by 86.6% versus direct chain-of-thought prompting.
That matters because most time series models are fluent in pattern, but mute about cause.
A housing inventory curve can reflect seasonality, mortgage pressure, migration, layoffs, and local supply, while a stock price can be bent by earnings, regulation, hype, and fear.
Nexus separates those jobs instead of asking one prompt to do everything.
One agent turns messy historical text into a clean event timeline, one reads the broad regime, another tracks local shocks, and a synthesizer reconciles them with calibration from past errors.
The interesting result is not merely that context helps, but that structure helps the language model use context without losing the time series.
The evidence is still narrow: Zillow counts, seven equities, post-cutoff data, and single-run evaluations, so this is not a universal law of forecasting.
But the direction is clear: future forecasters will not only extrapolate curves; they will argue about what made the curve move.
----
Paper Link – arxiv. org/abs/2605.14389
Paper Title: "Nexus : An Agentic Framework for Time Series Forecasting"
Most of us spend years trying to change outcomes without examining the internal framework producing them.
This article gets to the root by examining and then stripping away the conditioning that keeps you from becoming fully yourself and finding your bliss.
Great read @thedankoe !
Pay attention to this one if you build multi-agent systems.
Coordination is as important as prompts or agent architecture.
Multi-agent LLM systems fail in production at rates between 41% and 87%.
The majority of those failures are coordination defects, not base-model capability. Most published comparisons of multi-agent architectures can't even tell you whether the gain came from coordination or from one configuration just having larger context windows.
This new research argues that coordination should be treated as a configurable architectural layer, separable from agent logic and from information access. Then it backs the position with an information-controlled experiment: same LLM, same tools, same prompt template, same per-call output cap. The only thing that varies is coordination structure.
Why it matters:
until you control for information access, "multi-agent beats single-agent" doesn't actually mean coordination won. This paper gives you a cleaner methodology for actually testing it, and a vocabulary for reasoning about coordination as architecture instead of plumbing.
Paper: https://t.co/8m0P8kCQ2a
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
Karpathy这段话把AI工具使用的核心逻辑说透了:你不应该是那个瓶颈。
以前用AI是一问一答的形式,你在loop里面当调度员。
现在的正确姿势是——你设计好系统,按一下go,然后该干嘛干嘛去。
1. "Arrange things such that they're completely autonomous" = 把Skills、Rules、Hooks、验证循环全搭好,让Agent能自己跑完整流程
2. "Maximize token throughput and not be in the loop" = 你的杠杆率取决于系统设计得有多好,不取决于你打了多少字prompt
3. "I put in very few tokens, a huge amount of stuff happens" = 一次性投入设计成本,换持续的自动化产出
以前的工作模式是:写prompt → 看结果 → 改prompt → 看结果 → 循环。你的产出上限等于你打字的速度。
现在应该是:设计好Harness → 配好feedback loop → 点go → 去做别的事。产出上限等于系统的并发能力。
不过这一切有一个前提:
前提是你的工程基础得够好:
1. 要有好的验证循环——Agent跑完了能自己check对不对
2. 要有好的错误恢复——跑歪了能自己退回来重试
3. 要有好的模块化——每个环节可以独立测试和替换
Most AI assistants wait for you to ask.
But a truly useful agent should notice you need help before you say anything.
New research takes a serious shot at building proactive agents that work in real time.
The work introduces PASK with three components: IntentFlow for streaming demand detection, a hybrid memory system (workspace, user, global) for long-term context, and a proactive agent framework that forms a closed loop.
They also release LatentNeeds-Bench, built from real user-consented data refined through thousands of rounds of human editing. IntentFlow scores 84.2 overall, matching Gemini-3-Flash (80.8) while most other models, including GPT-5-Mini (77.2) and Claude-Haiku-4.5 (66.2), struggle badly at this task.
Why does it matter?
The hardest part isn't complex reasoning. It's reliably detecting when a user has an unstated need versus when they don't.
Most models are either too helpful or too silent, but rarely both calibrated. This is one of the first systems to tackle proactive assistance as a real product problem.
Paper: https://t.co/EYIt2pv6fQ
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
SciPredict: Can LLMs Predict the Outcomes of Research Experiments in Natural Sciences?
"SciPredict addresses two critical questions: (a) can
LLMs predict the outcome of scientific experiments with sufficient accuracy? and (b) can such predictions be reliably used in the scientific research process? Evaluations reveal fundamental limitations on both fronts. Model accuracies are 14-26% and human expert performance is ≈20%."
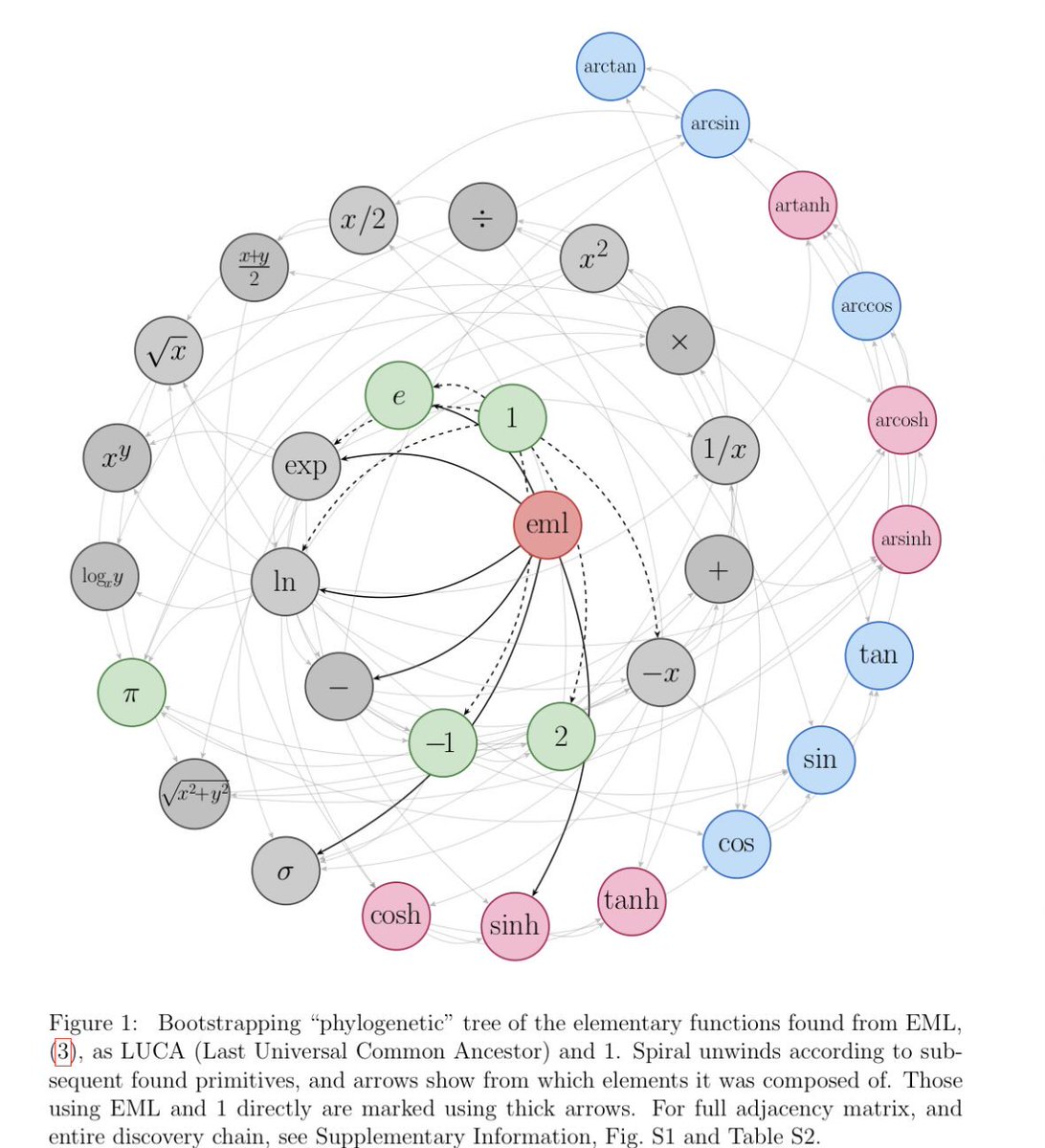
Physicist has written a fascinating big beautiful paper.Let’s not be afraid to call it what it is - groundbreaking. For hundreds of years, mathematics had dozens of “basic” functions: sine, cosine, logarithm, square root, exponential. You know these from school. Everyone does. Now it turns out that all of it is one single operator:
E(x, y) = exp(x) - ln(y), and the constant 1.
Sin, cos, π - everything follows from this neatly , just nest it properly. Nature hid the simplest possible description of reality. And it was just been found. The whole thing is beautiful and remarkable, here the word “groundbreaking” is not a marketing buzzword.
For instance, instead of writing π or 3.14, one can now elegantly write E(E(E(1,E(E(1,E(1,E(E(1,E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(E(E(E(E(1,E(E(1,E(1,E(E(1,E(E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(E(1,E(E(1,E(E(1,E(E(1,1),1)),E(E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(1,1)),1))),1)),1)),1)),1))),1)),E(E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(E(1,E(E(1,E(1,E(E(1,E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(1,1))),1))),1)),1)),1)),1),1),1))),1))),1)),E(E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(E(1,E(E(1,E(1,E(E(1,E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(1,1))),1))),1)),1)),1)),1)
https://t.co/Pv2UUbTEay