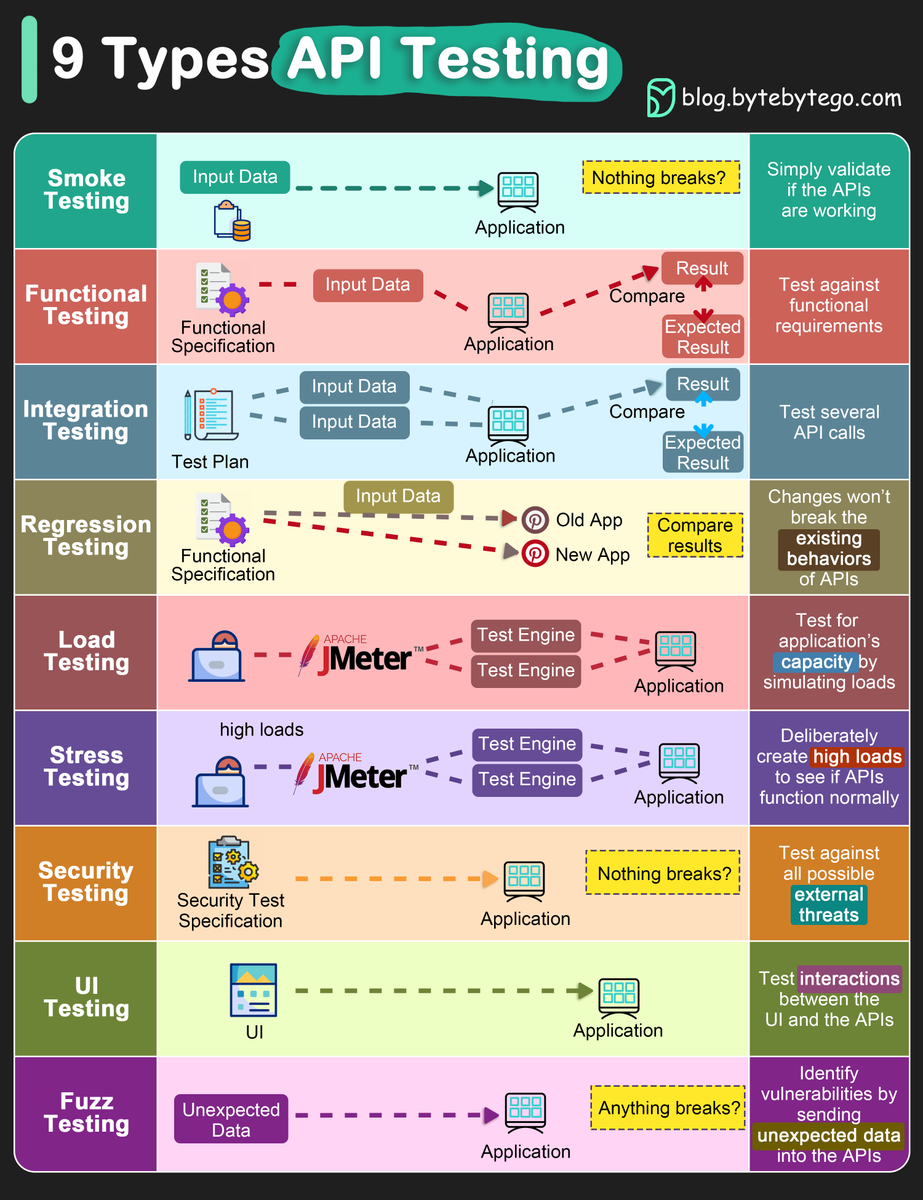
@DiegoAcuOficial Es una necesidad, se pierde capacidades, se puede perder la oferta y tirarse un proceso que duró años y ahora viene con otra postergación, tanto tiempo y es ilógico, la defensa del pais va más allá de cualquier período de gobierno.
RAG vs. CAG, explained visually for AI engineers 🧠
(with must-know design considerations)
RAG changed how we build knowledge-grounded systems, but it still has a weakness.
Every time a query comes in, the model often re-fetches the same context from the vector DB, which can be expensive, redundant, and slow.
Cache-Augmented Generation (CAG) fixes this.
It lets the model "remember" stable information by caching it directly in the model's key-value memory.
And you can take it one step ahead by fusing RAG and CAG.
Here's how it works:
→ In regular RAG setup: Query goes to vector database, retrieves relevant chunks, feeds to LLM
→ In RAG + CAG: You divide knowledge into two layers:
• Static rarely changing data (company policies, reference guides) gets cached in model's KV memory
• Dynamic frequently updated data (recent customer interactions, live documents) continues via retrieval
This way, the model doesn't reprocess the same static information every time.
It uses cache instantly and supplements with new data via retrieval for faster inference.
The key: Be selective about what you cache.
Only include stable, high-value knowledge that doesn't change often.
If you cache everything, you'll hit context limits. Separating "cold" (cacheable) and "hot" (retrievable) data keeps this system reliable.
You can see this in practice - many APIs like OpenAI and Anthropic already support prompt caching.
👉 Over to you: Have you ever used CAG?
Guía de cómo las empresas despliegan código a producción.
Te explico todos los pasos:
1: El Product Owner redacta User Stories basándose en las necesidades identificadas.
2: El equipo de desarrollo convierte las User Stories en tareas específicas.
3: Los desarrolladores integran el código en el repositorio de GitHub.
4: Se lanza una build en Jenkins o GitHub Actions. El código debe pasar pruebas unitarias y validaciones en SonarQube o a través del linter.
5: Se genera un artefacto y se despliega en un entorno de desarrollo.
6: Si hay varios equipos trabajando en distintas características, se crean múltiples entornos de desarrollo.
7: El equipo de QA realiza pruebas de calidad, regresión y rendimiento.
8: Se pueden hacer pruebas de aceptación del usuario (UAT) en un entorno de prueba.
9: Si las pruebas en el entorno UAT son exitosas, las builds se convierten en candidatas para la liberación y se programan para el despliegue en producción.
10: El equipo de Ingeniería de Fiabilidad del Sitio (SRE) monitorea la producción.
Este es solo un ejemplo de cómo se puede desplegar el código a producción. Dependiendo de la empresa, se pueden usar otras herramientas o seguir más o menos pasos.
Por ejemplo, algunas compañías no usan entornos de prueba y optan por Feature Toggle, A/B Testing o Canary Releases.
¡Seguramente no necesites usar más git checkout!
Desde Git 2.23 existen switch y restore.
La idea es que cada comando haga una sola cosa.
Aquí tienes algunos ejemplos de cómo usarlos:
🎉 ¡He desbloqueado un reto en Codember!
➡️ https://t.co/v3vz0rUhzf
¿Quieres mejorar tu lógica de programación?
¡No te pierdas este juego con retos que puedes resolver en cualquier lenguaje de programación!
🚨 ¡Notición!
GitHub acaba de presentar su propia conferencia tecnológica global de habla hispana...
¡La OCTOGATOSCONF! 😍
🥳 Celebrando el mes del patrimonio de la comunidad Latina
🗓 15 Septiembre
🎤 30 Speakers
🗣 Charlas en Español y Portugués
🎟 GRATIS
🧵⬇️