TL;DR Photometric robustness in VLA models is achievable. One model already proved it.
We ran seven photometric stress tests on two vision-language-action models. Same benchmark, same perturbations, same severity levels. Pi 0.5 held flat. SmolVLA lost ground on nearly every one.
Jack Dorsey just published something that should be required reading for every founder.
The premise: the org chart needs to be replaced entirely. And the argument starts 2,000 years ago.
For thousands of years, every organization on earth has run on the same logic the Roman Army invented.
Small teams report to a leader → Leaders report to managers → Managers report to executives.
The whole structure exists for one reason: to route information up and down the chain.
That's it. The whole system exists to solve a bandwidth problem.
Jack's argument is simple: AI solves it better.
Block built what they call a "world model" - a continuously updated picture of everything happening across the company. Every decision. Every customer. Every transaction. Every bottleneck. In real time.
No status update needed. No weekly sync. No manager to translate what's happening on the ground into language the executive can understand.
When the world model carries the information, you don't need the layers.
So they eliminated them.
Block now runs on three roles:
Individual contributors who build.
DRIs who own specific outcomes for a fixed period.
Player-coaches who develop people while still doing the work themselves.
No middle layer. The system handles coordination. The humans handle the work.
I've coached thousands of founders. The number one problem is always the same: information latency.
By the time a problem surfaces from your front line to leadership, it's already compounded. By the time a decision travels back down, the damage is done.
That lag costs you deals, people, and momentum. And most founders accept it as the price of scale.
Block is trying to prove you don't have to anymore.
I think they're right.
Because the hierarchy was never the point - it was just the best tool we had. The moment something better exists, the layers eventually collapse.
This is either the biggest structural shift since the 1850s - or it breaks at scale like everything else before it.
Either way - every founder should be asking the same question: how much of your org exists just to route information?
If the answer is "most of it" - that's your problem. And your opportunity.
-DM
Lighting changes constantly: time of day, weather, different rooms, sensor drift. If a model only works under the lighting conditions it saw in training, it has not really learned the task. It has learned one appearance regime.
We put this to the test. Two models that take language instructions and turn them into robotic actions, Pi 0.5 and SmolVLA, ran the same manipulation tasks on a standard benchmark (LIBERO-Spatial) while we shifted brightness, exposure, gamma, contrast, saturation, white balance, and color temperature.
Same geometry, same objects, same tasks. Only appearance changed.
Pi 0.5 barely moved. Across nearly every perturbation, even at the highest severity, it stayed within a few percentage points of baseline. The only measurable dip was contrast, to around 94% of baseline. Not a collapse. A graceful decline.
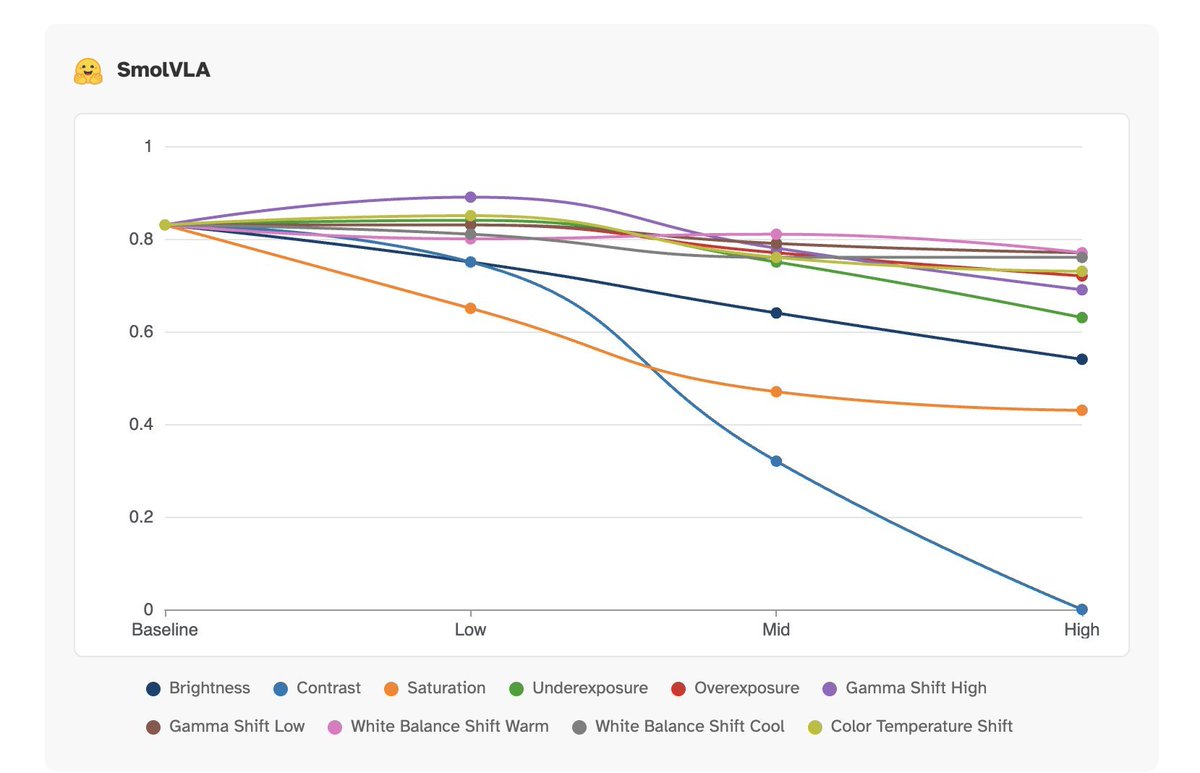
SmolVLA degraded under nearly every one. Saturation cut performance roughly in half. Brightness produced steady losses. Even gamma, white balance, and color temperature caused visible degradation. And then there was low contrast. SmolVLA went from baseline to near-zero. Not a degradation curve. A complete collapse.
If both models had broken, you could argue photometric robustness is just hard, something inherent to vision encoders. Pi 0.5’s near-total immunity rules that out. Photometric robustness is achievable. SmolVLA’s failure is diagnostic.
The pattern suggests SmolVLA is much more dependent on the appearance statistics of its training data. Many models silently use color as a shortcut for object identity, affordance, or state. When color shifts, those shortcuts break.
By contrast, Pi 0.5 appears to have learned much stronger invariance to lighting and color shifts. Training augmentation is likely part of that story.
The two models do share one vulnerability: low contrast.
Pi 0.5 dips gently. SmolVLA collapses.
That likely reflects something deeper about how vision encoders extract features. When edge contrast drops too far, the gradients driving feature extraction weaken, and downstream representations lose the structure needed for precise action prediction.
Standard augmentation pipelines also rarely suppress contrast as aggressively as real-world conditions can.
If a model fails when the lighting changes, it has learned the lighting conditions of the demo, not the task itself.
Full analysis with interactive visualizations:
https://t.co/NJvEl0acBg
Mid/back office bros in finance, your 2026 career pivot chance just got fatter. Nothing says ‘please review our AI tool stack’ like accidentally shipping your entire Claude Code source map to npm 😂
Got it—bookmarked!
Full technical blog + interactive UX on photometric perturbations here: https://t.co/1H1W1sOoVS
Pi 0.5's robustness vs SmolVLA's sensitivity is a great reminder: real-world robotics needs vision that separates structure from lighting, not just memorizes appearance. Solid analysis.