Document Index for Vectorless, Reasoning-based RAG!
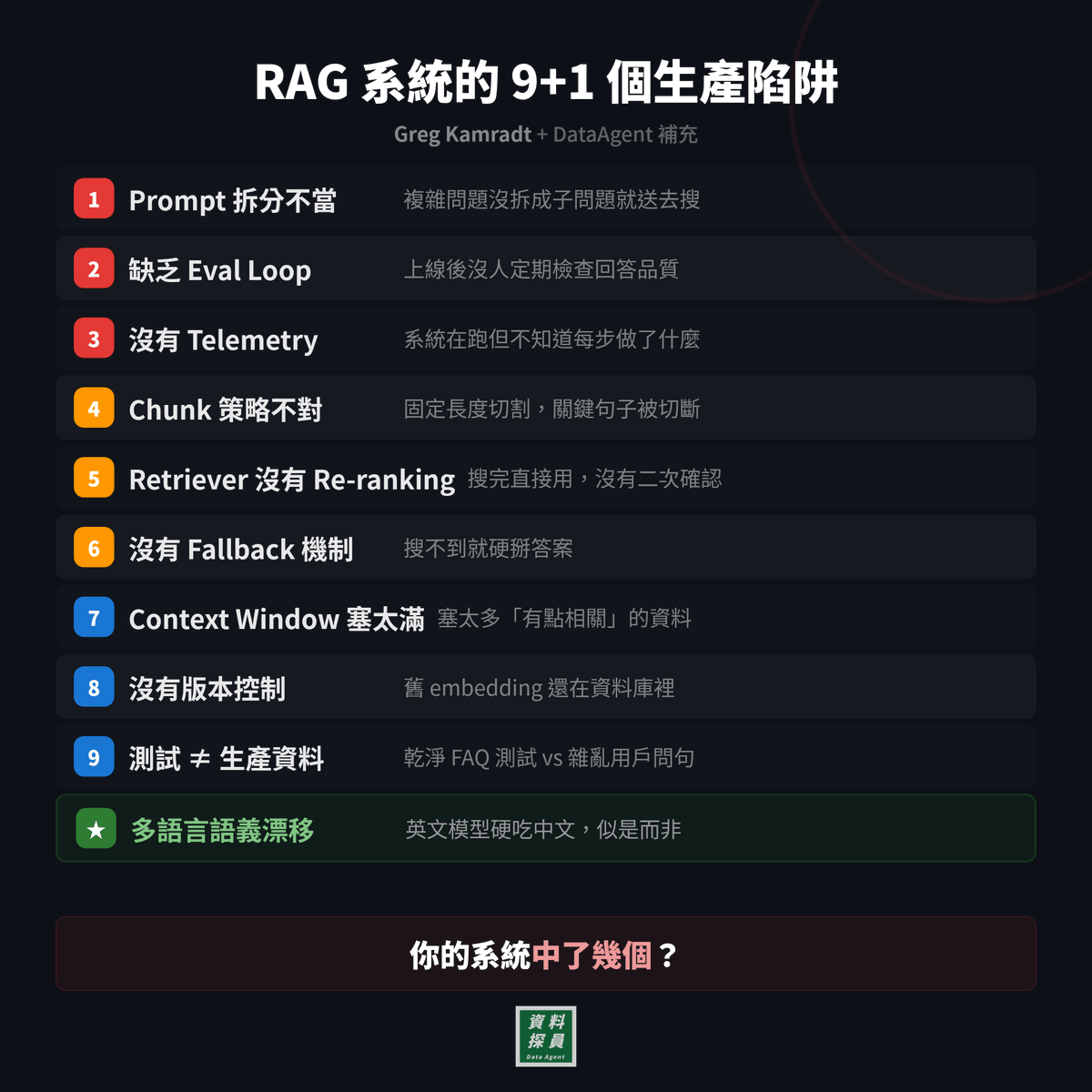
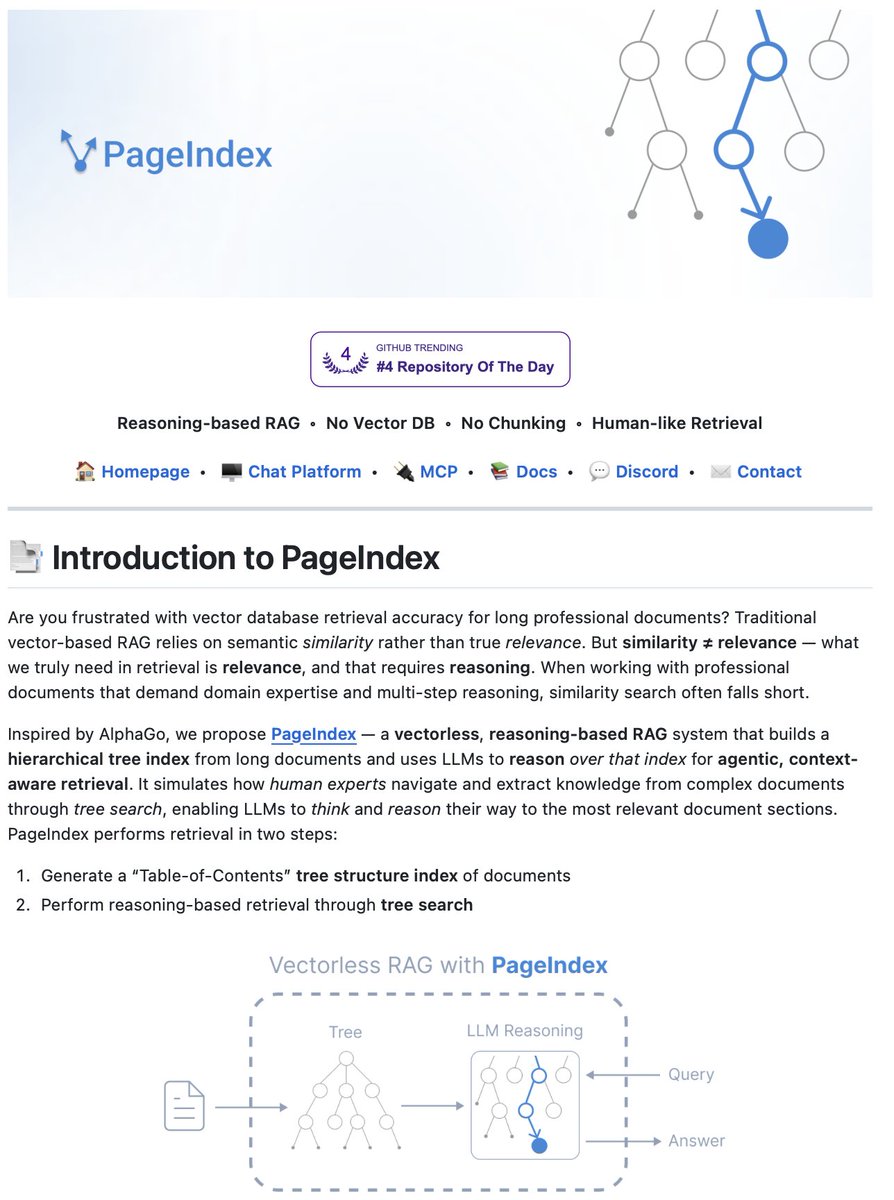
PageIndex is an open-source RAG framework that removes vector databases and chunking from document retrieval.
Most RAG systems rely on semantic similarity. They chunk documents arbitrarily, embed them into vectors, and retrieve based on what looks similar.
But similarity ≠ relevance.
Professional documents like financial reports, legal filings, and technical manuals require multi-step reasoning and domain expertise. Vector search falls short when every section contains similar terminology.
PageIndex takes a different approach.
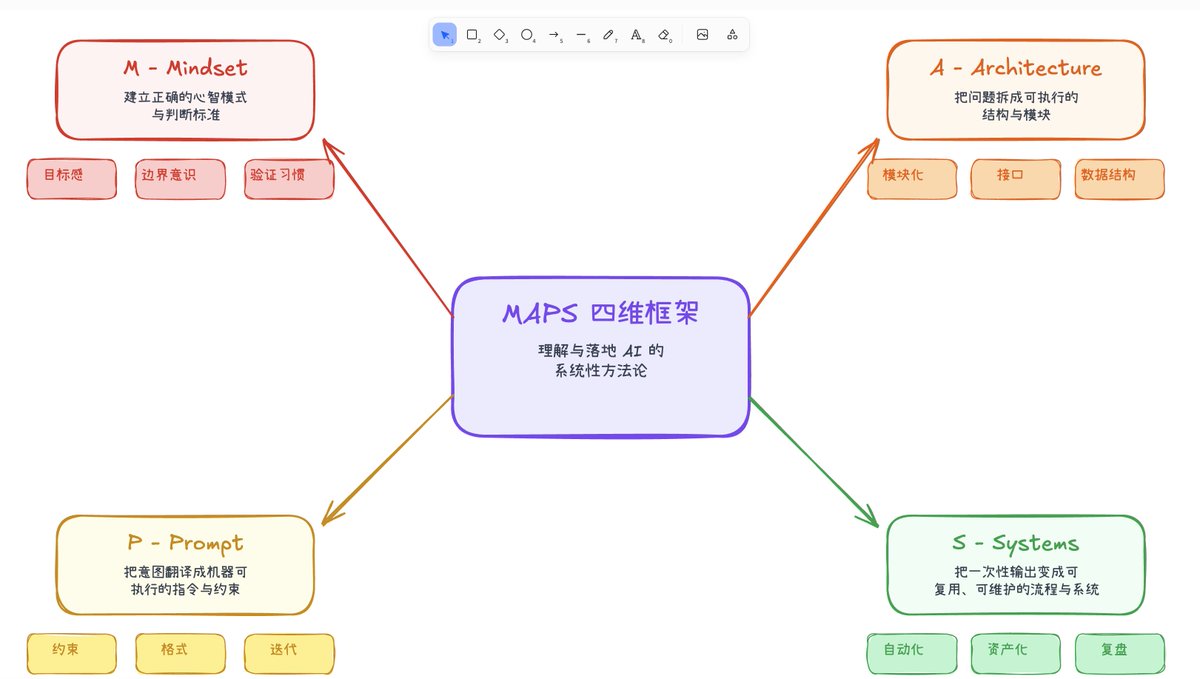
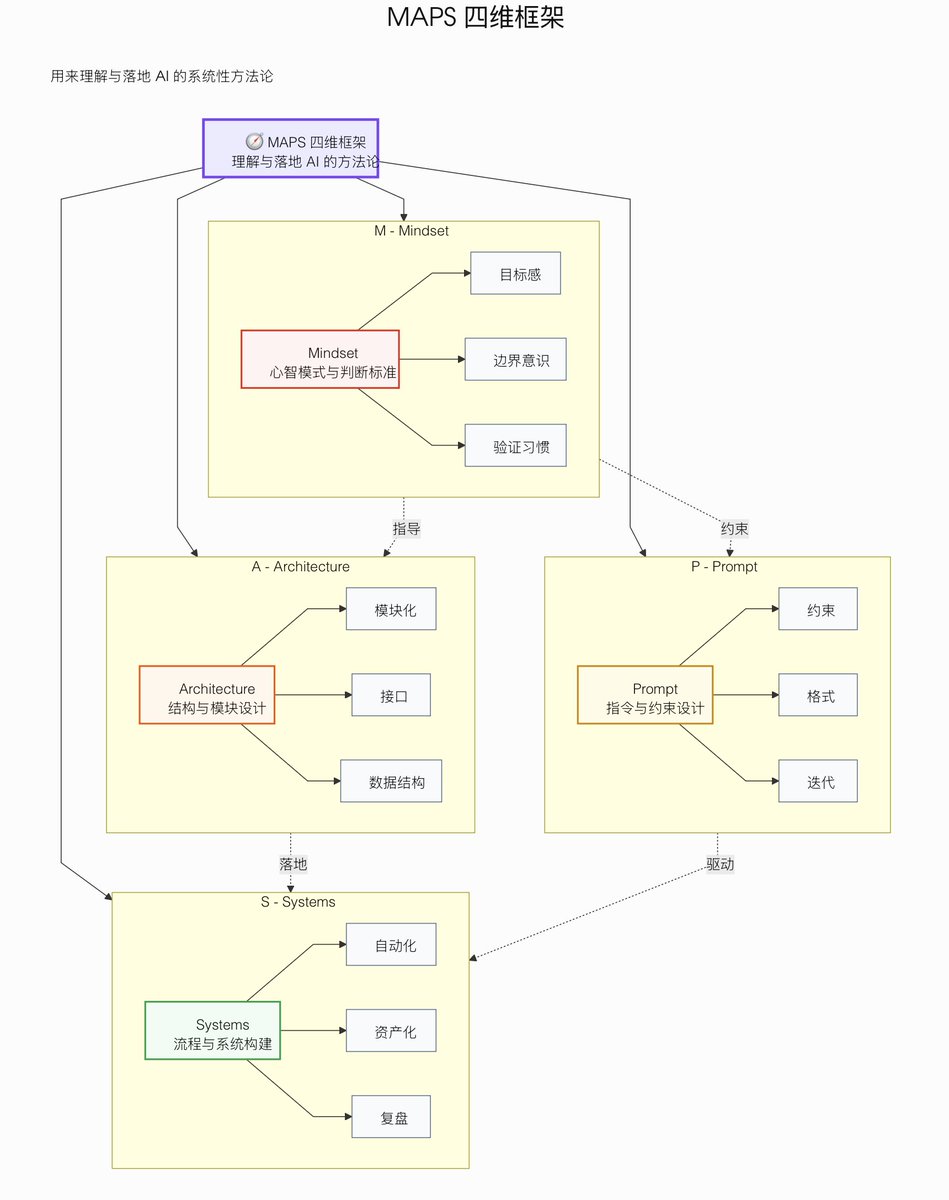
It builds a hierarchical tree structure from documents, similar to a table of contents but optimized for LLMs. Then it uses reasoning-based tree search to navigate and retrieve information the way human experts would.
Two-step process:
Generate a tree structure index of the document → Perform reasoning-based retrieval through tree search.
The LLM can "think" about document structure. Instead of matching embeddings, it reasons: "Debt trends are usually in the financial summary or Appendix G, let's look there."
Key features:
• No vector database infrastructure or embedding pipelines
• No artificial chunking that breaks context across boundaries
• Traceable retrieval with exact page-level references
• Reasoning-based navigation that mirrors human document analysis
PageIndex powers Mafin 2.5, achieving 98.7% accuracy on FinanceBench for financial document analysis.
The best part?
It's 100% open source.
Link to the GitHub repo in the comments!