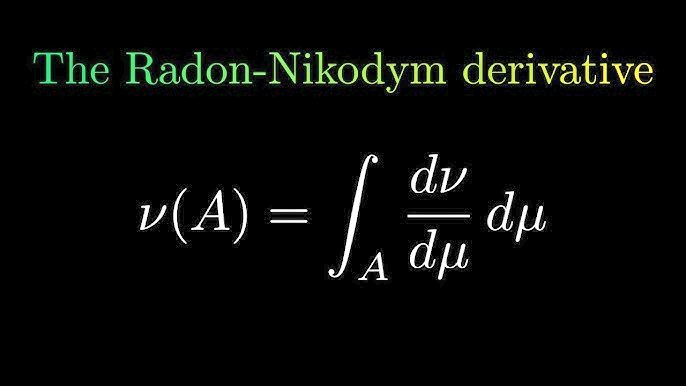@volatilitysfray@UnivHesperides Evitaría matemáticos muy conocidos y desconocidos. Teoría de probabilidad es la intersección de las tres, así que Andréi Kolmogórov es una opción por axiomatizar la probabilidad. Otro es Robert V. Kohn, relacionado con PDE y finanzas y más moderno. Por último, Louis Nirenberg.
Most people in machine learning still misunderstand probabilities.
A model can be perfectly calibrated and still be completely useless.
This was proven more than 40 years ago by DeGroot & Fienberg (1983).
Yet many ML papers still miss this point.
Here is the idea.
"Nobody is learning C++ in 2026" is just bullshit.
C++ is a programming language that is still highly in demand.
If you want to learn or get better at C++, check the following resources: (details below) ↓
A point that is sometimes overlooked is that PDEs in physics and economics have a subtle but important difference.
When a physicist solves the Schrödinger equation (see my slide below), the potential is given. The coefficients of the equation are part of the problem statement. You pick your grid, refine your mesh, and the equation never changes on you. Better numerics give a better approximation to a fixed target.
In economics, this is not the case. Look at the Hamilton-Jacobi-Bellman equation for the neoclassical growth model (also slide below). The drift of capital depends on a derivative of the value function, the very object you are trying to solve for. The “coefficients” of the PDE are endogenous to the optimal choices of the agents. This is what @UncertainLars and Sargent referred to as the cross-equation restrictions implied by optimizing behavior.
This is what @MahdiKahou and I call the “equilibrium loop”: improving your approximation changes the policy, which changes the dynamics, which changes where in the state space the economy spends its time, which changes where your approximation needs to be accurate. You are not chasing a fixed target with a better net. Moving the net moves the target.
This has serious consequences for computation. You cannot just borrow neural network architectures from deep learning in the natural sciences. The loss function comes from equilibrium conditions, not from labeled data. The evaluation points are not given. Instead, they are regenerated each epoch from the current approximation. Ignoring it is why you often get solutions that look good on a training set but fall apart in simulation.
My programming setup (2026)
I use VS Code as my main text editor: It works the same everywhere I care about (macOS, Windows, Linux). It is fast enough. It has useful features like the ability to mount a remote Linux system and work on my MacBook as if I were directly on the remote machine. It has GitHub Copilot.
I’m not an advanced VS Code user. I use few extensions — the fewer, the better. I don’t do fancy editing (like multi-cursor editing). I don’t customize shortcuts. I could probably save a few seconds here and there, but I don’t care. I waste more time making coffee than I do editing files suboptimally.
I spend little time on Windows. I have one Windows laptop with VS Code preconfigured. It has a shell that can compile C/C++ using CMake. I never remember exactly how it works, but I set it up once each time I update the machine. I use Windows only to debug and benchmark.
Although I started programming professionally with Borland and Microsoft tools in a debugger-heavy style, these days I rarely use a debugger. I prefer to write more tests. People are often surprised at how many tests I write and run. I use continuous integration fanatically.
I use different programming languages: C, C++, Go, Java, C#, Python, and JavaScript. I try to keep everything under VS Code so I don’t have to learn different tools when switching languages. I use the command line a lot.
I also use AI heavily. I like Claude CLI and GitHub Copilot. Grok is available by way of GitHub Copilot and it works well. These are great tools. I ask the AI to build tools, create tests, and more. For example, I recently asked AI to create a tool that checks whether my new function is branch-free by compiling the code, disassembling it, and analyzing the instructions. It is quite clear that I will be building more and more custom tools with AI, to help me.
One great use of AI are reviews. Instead of using AI to generate more code faster, I get AI to slow me down, review my code more carefully, throw in more tests. In many instances, quality matters more than volume. I love how AI lets me quickly test ideas: “What if we did it this way instead?” AI really nails down the standard optimizations, letting me concentrate on original techniques. It allows me to up my game. I don't trust the AI, but Iet it try things for me. If the AI can make something work, then I explore further.
For profiling, I like perf under Linux. When needed, I use Xcode Instruments on macOS. I prefer to profile under Linux. For building websites for my projects, I default to Hugo. The core idea is that you write content in Markdown and it generates static HTML. No backend required. I adopted Hugo years ago for my homepage (https://t.co/o5rjMo5NV3).
My blog itself runs on WordPress. After 20+ years, it is a highly tuned (though imperfect) setup. Migrating it would be too much work. I don’t like typing content directly in WordPress. So I write my posts in Markdown using VS Code, convert them to HTML, and copy/paste into WordPress. Yeah, there are MarkDown plugins but none of them work well enough.
I don’t understand Substack. I will never charge for my blog content or put ads on it. You can still subscribe by email (no ads, ever). I like staying in control.
I love MarkDown. I wrote an entire book using Markdown in VS Code: Mastering Programming: From Testing to Performance in Go (https://t.co/IjvE8303nm). I convert it to LaTeX and then to PDF.
I make generous use of Docker containers — for example, to run old versions of Hugo or exotic compilers. I avoid system-specific dependencies whenever possible.
I have a few web services and I use AWS Lightsail for them. Build a container, deploy, and forget. Ready to use.
Had a lot of fun at https://t.co/MZw5WEmzGJ this weekend. Got inspired to port @bulatov_org 's symmetric gray-scott visualizer into a standalone repo https://t.co/bioyICKLd0
During a volcanic eruption, lava forms a scorching, chaotic river. But once it cools enough to enter a state of equilibrium, mathematicians can describe it using a class of equations called elliptic PDEs, which a recent proof has finally illuminated.
https://t.co/WkJLzXEaDv
@Miru_NeeChan Disculpa Miri. He empezado torpe el año 😅.
Input
La mala costumbre
El ritmo de la guerra
Los peligros de fumar en la cama
Panza de burro
Output
la mala costumbre de fumar en la cama
Los peligros de la guerra
El ritmo de la panza de burro
Un consejo, una obviedad y inquietante
@Miru_NeeChan (2/2)Sobre tus lecturas, me he entretenido seleccionando y combinando tres de ellas. En el última hice trampa, tuve poner un de y la como "pegamento". El tercero tiene un título que te deja pensando, o al menos a mí me ha pasado.
🎊Feliz Año Miri. Espero que te vaya bien.🎊
@Miru_NeeChan (1/2) Comparto mi lectura de este año para mantener la tradición. Mi conclusión es que machine learning y sucedáneos, a grandes rasgos, son estadística con algoritmos muy pesados.
Partial differential equations (PDEs) have become a powerful language for describing training dynamics of modern machine-learning models, especially neural networks trained by gradient descent. When the number of neurons is large, the evolution of network parameters can be described by PDEs such as the Fokker–Planck or Wasserstein gradient-flow equations, which track how the distribution of weights changes over time. This viewpoint comes from probability theory and statistical physics, where similar equations describe particle systems, diffusion, and mean-field limits. Foundational work by probabilists on interacting particle systems, stochastic differential equations, and optimal transport made it possible to rigorously justify these PDE limits. In ML and deep learning, this theory explains why training is stable, why over-parameterized networks generalize, and how noise in stochastic gradient descent acts as an implicit regularizer. Practically, PDE models guide learning-rate schedules, help predict convergence and collapse, and inspire new training algorithms such as Langevin dynamics and mean-field neural networks that are now widely used in large-scale AI systems.
Image: https://t.co/67gqTndijb
The Radon–Nikodym derivative is a fundamental concept that describes how one probability measure changes relative to another, generalizing the idea of a density function. It allows us to express one distribution in terms of another even when working on abstract spaces. In probability theory, it is essential for defining conditional probabilities, likelihood ratios, and changes of measure, such as in martingale theory and financial mathematics. In machine learning, Radon–Nikodym derivatives appear in importance sampling, variational inference, and generative modeling, where one distribution is reweighted to approximate or learn another. In real life, the same idea underlies risk-neutral pricing in finance, Bayesian updating, and signal processing, where observations are reinterpreted under different models of uncertainty.
Image: https://t.co/eMhmVbxZRu
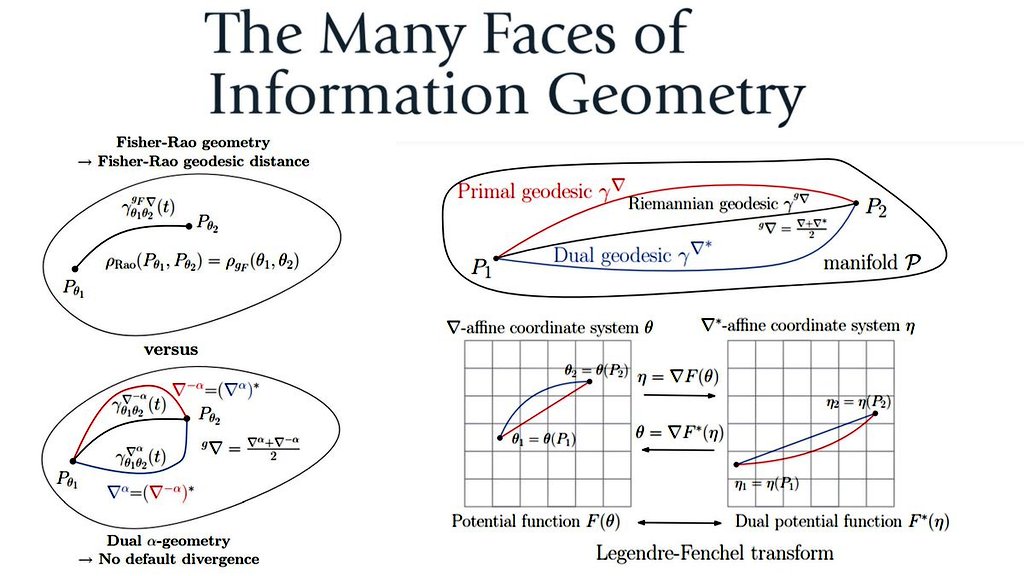
Information geometry studies probability distributions as geometric objects, equipping statistical models with a Riemannian structure derived from Fisher information. This viewpoint turns inference into geometry, where learning corresponds to moving along curved manifolds of distributions. In probability, information geometry clarifies concepts like divergence, sufficiency, and exponential families, and provides precise bounds on estimation and hypothesis testing. In machine learning, it powers natural gradient descent, variational inference, and optimization of deep models by respecting parameter geometry rather than using naive Euclidean updates. In real life, information geometry is applied in signal processing, neuroscience, thermodynamics, finance, and robotics, improving efficiency, stability, and interpretability in systems that learn or adapt under uncertainty.
Image: https://t.co/vbXeZyX7Am