The narratives in crypto are always changing and as a marketer it's extremely hard to keep up.
Working at @chaoslabs, I interface with 20+ protocols on a typical day across verticals like lending, derivatives, and infra.
Tbh it's a struggle to context switch across these niche protocols (with very exciting tech) while staying on top of our core products across the risk management stack.
Not to mention the daily information overload from crypto newsletters, tech newsletters, CT, podcasts, macro, Trump, and everything else.... It gets overwhelming and scary really quick.
But not anymore 💪
Since using Chaos AI, I've cut my research time by over 60% and can respond to technical questions way faster than before. I no longer need to stay on top of every protocol update and can simply prompt Chaos AI while I focus on execution and other higher-impact initiatives.
Here's how I use Chaos AI.
• Go direct with my questions. Rather than searching numerous sites or platforms for metrics, I ask questions directly to the Chaos AI agent. I no longer need to bug our data scientist (🤣 @whale_hunter_) or query @Dune to get metrics on @aave, @GMX_IO, or @VenusProtocol.
• No more reading 100+ page technical docs (unless I want to ofc). I can upload whitepapers and research and use this as a framework to understand protocol mechanics. I'm not an engineer so this puts me on equal footing with my more technical colleagues.
• Power up my market intelligence: This is by far the most context-aware onchain intelligence platform in the market. I can easily analyze token performance, protocol metrics, and feed in market info to identify trends and opportunities before they become mainstream narratives. Very useful.
With Chaos AI, marketers and non-technical folks like myself can go direct with questions and get precise, actionable insights in seconds!
1/ Introducing Chaos AI—The World’s First AI-Powered Crypto Researcher.
Built on years of proprietary data from securing trillions in trading volume, Chaos AI transforms fragmented market data into institutional-grade financial intelligence.
Get Early Access: https://t.co/b1ASMY1x1D
1/ Recent debates around AI have focused on inference economics.
Far less attention has been paid to retaining, reusing, and compounding the outputs of inference across workflows and time.
Work units connect inference to ROI.
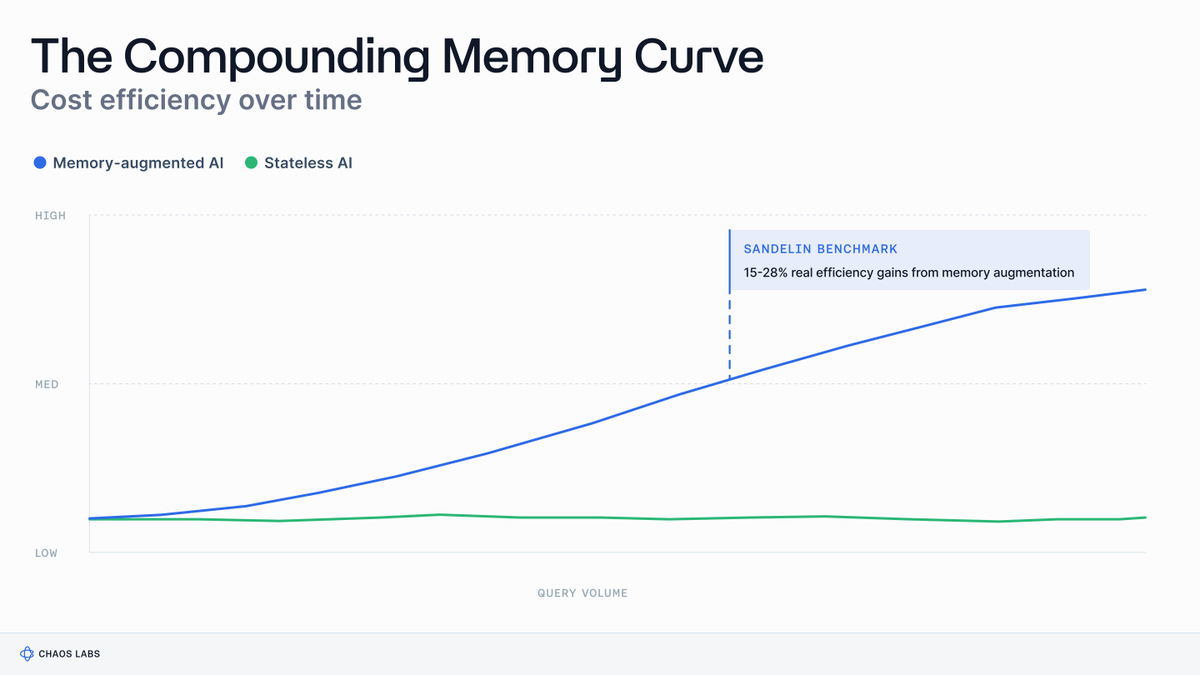
The Compounding Economics of AI Memory
Memory reduces the marginal cost of inference by making prior computation reusable, creating a compounding efficiency curve as query volume grows.
Future inference benefits from prior inference.
Investment research, risk management, and portfolio construction increasingly depend on AI, yet most workflows remain session-based.
As analytical output grows, the ability to accumulate knowledge becomes as important as the ability to generate it.
Enterprises often recompute the same analytical work through different prompts, workflows, and users.
Semantic clustering addresses this by:
→ Identifying equivalent work
→ Reusing validated conclusions
→ Accumulating new knowledge as it is produced
At enterprise scale, intelligence compounds through memory.
→ Semantic clustering identifies equivalent work
→ Work lineage traces decisions to evidence
→ Validated state preserves conclusions
→ Outcome correlation connects decisions to results
The enterprise memory stack:
At enterprise scale, statelessness becomes a tax paid in tokens, time, and analytical inconsistency.
Once reasoning becomes a production workload, it must be retained, validated, and reused.
We explore the architecture behind this shift:
Organizations are investing heavily in AI, yet much of the reasoning produced disappears at the session boundary.
The result is an architecture where validated reasoning is repeatedly recomputed rather than retained.
Here's a map of the stateless vs memory-augmented AI loop:
1/ What You Need to Know to Start Your Day
> S&P 500 and Nasdaq closed May at record highs, driven by AI & semiconductor rallies
> Payrolls week begins with ISM Manufacturing today; jobs data Friday expected at +93K
> $HPE earnings offer the next read on AI spending
Institutional memory begins where retrieval ends.
Persistent state enables:
→ Reuse of validated conclusions
→ Shared reasoning across teams and workflows
→ Continuous updates as evidence changes
Without these capabilities, AI workflows remain isolated inference events.
> Microsoft canceled claude code licenses + Uber burned its 2026 AI budget in ~4months.
> Same root cause (stateless inference) which was never really designed for insti reasoning
> Our piece on what the infra response should look like
Most AI architectures rely solely on retrieval.
→ Documents retrieved
→ Reasoning recomputed
→ Conclusions reset between workflows
We see a shift from retrieval to persistent state, where validated reasoning is retained and compounded across teams, workflows, and time.
1/ What You Need to Know to Start Your Day
> Micron $MU rose ~8% premarket after crossing a $1T valuation
> Zscaler fell 20% after weak guidance; Salesforce, HP and Marvell report today
> Iran negotiations remain fragile as BOJ caution keeps macro sentiment restrained
1/ Three Things Markets Are Watching Today
> Futures jumped after Trump said Iran negotiations are “proceeding nicely”
> Kevin Warsh begins Fed tenure this week; April PCE now a key macro test
> Consumer confidence data lands today after UMich sentiment hit a record low
1/ Three Things Markets Are Watching Today
> S&P 500 heads toward an eighth straight weekly gain, the longest streak since 2023
> University of Michigan sentiment data lands at 10 am ET with inflation expectations in focus
> Nvidia momentum continued spilling into global tech
1/ Three Things Markets Are Watching Today
> Iran tensions escalate; Brent climbed back above $106
> Quantum stocks jumped on reports Washington will deploy $2B across strategic computing
> $WMT fell ~2% after softer guidance raised new concerns around U.S. consumer demand