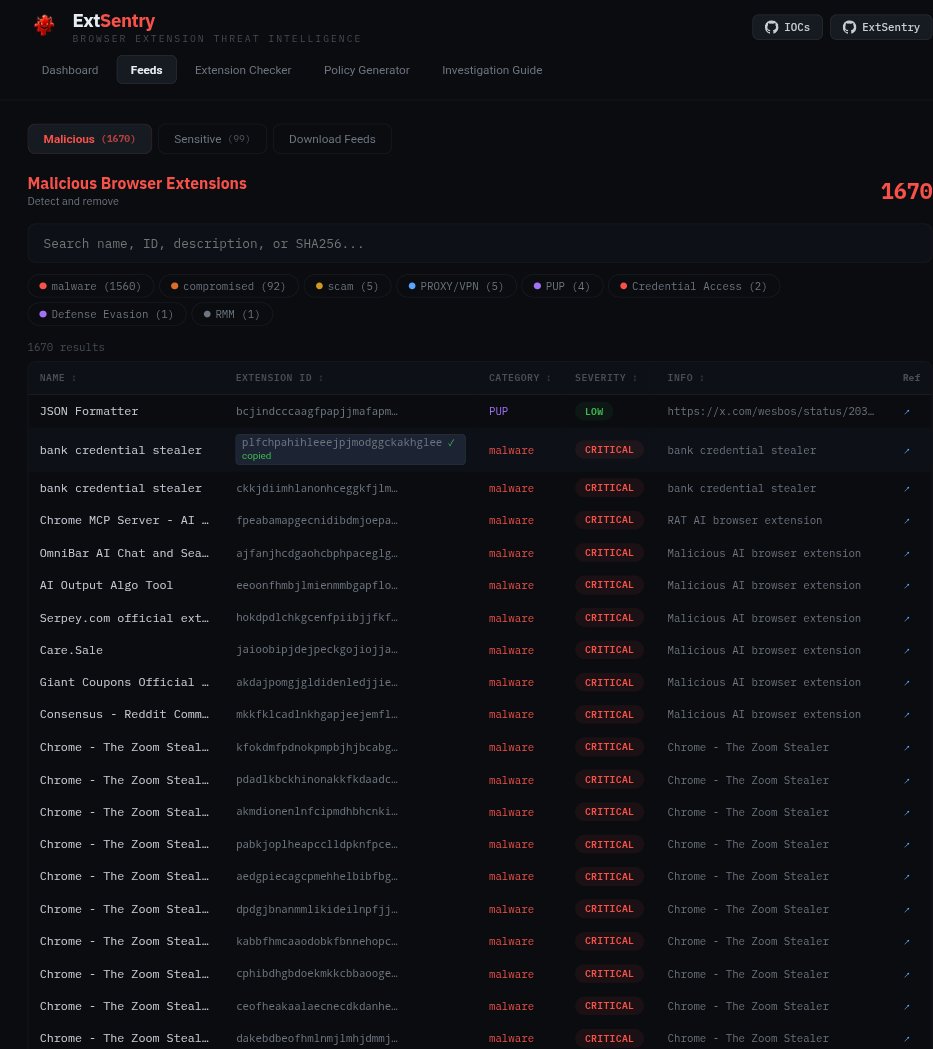
IRFlow Timeline v1.0.7 is live.
This one focuses on a problem I think DFIR teams will see more often: AI assistant usage becoming part of the investigation surface.
You can now collect and normalize local AI usage history from tools like Claude Code, ChatGPT Desktop, Cursor, GitHub Copilot, OpenAI Codex, Gemini CLI, Continue, Windsurf, and Claude Desktop into a unified timeline view.
Also added AI Secret Hunt, which helps identify secrets, tokens, API keys, private keys, and credentials that may have been pasted into AI assistants during real investigations or day-to-day engineering work.
The goal is simple: make AI app activity easier to preserve, search, tag, and correlate during incident response. AI usage is becoming part of the forensic record. We need tooling that treats it that way.
Link in the comment ⬇️
#DFIR #IncidentResponse
One thing I noticed while benchmarking LLMs on security event data:
The models often overfit on narrative plausibility and environmental assumptions.
If an artifact looks like a test, lab artifact or pentest remnant, the model may start inventing an "authorized testing" story around it and dismiss the event as a false positive - even when the technical indicator itself is clearly suspicious or intentionally malicious.
Examples:
- "EDRTest"
- "PentestPersistence"
- "EICAR_Check"
- "InternalSecurityTool"
A human analyst can fall for this too, but with LLM-based SOC workflows this becomes interesting at scale.
An attacker could intentionally name persistence keys, services or binaries in a way that nudges the model toward a benign interpretation.
What surprised me most:
The model often correctly understands the technical artifact first ... and then talks itself out of escalating it.
This is only one of many weird benchmark-design problems I ran into while testing LLMs on DFIR / detection-engineering data 🙂
New blog post: Building a Pipeline for Agentic Malware Analysis
Agentic RE + malware analysis with custom skills, MCP tooling, and persistent case state to automate intial triage
Link: https://t.co/Itj9S3rA9q
Github: https://t.co/kfvjN7ot4d
🤓 Very nice overview of using AI Agents/LLM for malware reversing by @mr_phrazer
It shows clearly how a defined workflow will help an agent do a better analysis. He also addresses valid current limitations and I want to address some of them in this tweet.
1. Human In The Loop (HITL)
On highly obfuscated or unusual samples, the agent alone will not be enough for now. You will need a human in the loop to validate, approve, refine, or guide the analysis. (even on more regular samples HITL remains useful)
2. Static vs dynamic analysis
The limitation discussed in the blog are mostly true for static analysis. But if you add dynamic analysis to your workflow, the agent gets additional context and sample packed, or obfuscated can be solved (in most cases, not all of them). But you also get behavioral data, memory traces, execution data... all of that will reduce blind spots.
3. Context window
With a single agent the context window can get overwhelmed quickly. Binary analysis can fill out the context just by disassembling one function, because of that, the agent can miss important information which will not be processed.
There are multiple ways to address this.
First, a multi-agent architecture split the context across agents so no single agent carries everything. You increase the context windows by leveraging the window of several agents, useful to split tasks too. Tim mentions the use of Subagent which is delegated by the orchestrator skill so in some cases the split may not be sufficient to save enough information, clearly defining multi agents with specific tasks can improve this.
Second, you can architect a persistent memory system. For large data the most common approach is RAG, but the retrieval strategy depends also on what you are building so I will not discuss that here as there is a multitude way to implement with more or less efficiency. In the blog, memory are stored in md files which can be limited for extensive analysis.
Usually a mix of short term memory and long term memory will be the best approach but it can be more difficult to orchestrate.
4. Output validation
We touched about this with HITL but validation is also closely tied to the context window problem.
One additional approach worth mentioning: LLM-as-a-judge where a separate system/agent/model will evaluate the output for accuracy grounded in the raw data. Additionally, as Tim mentioned in the blog, this will likely improve with the next iteration of models.
5. Monitoring and visibility
There is one last piece to discuss which is probably the most important point to add. If you run an agent architecture and only validate the final output, you are missing the reasoning steps, the intermediate decisions, and the potential evasion or exploitation of your system.
This is important for accuracy, for security, for automation reliability and for the quality of the final output. You need visibility into what the agent actually did and not only what it concluded.
Awesome blog overall! These limitations exist and there is already some solutions and the same was true two years ago.
The main difference now is that models are significantly more reliable than they were 2 years ago and it will likely continue to improve.
I hope that this shows that malware analysis with AI is far from copy pasting a sample into Claude and hoping for the best.
Tim demonstrated one step further with structured workflows, Agents, Skills and MCP. Now you can think about the next steps! 🙂
Congratulations to @KoifSec for winning our first ever RMM Rodeo by finding 14 new remote monitoring and management tools that weren't yet listed on https://t.co/5pG2plS3sO and running them in the DEATH Lab to generate logs and detection queries! He won a custom silver buckle
During my #BHUSA talk I've released many ETW research tools, of which the most notable is BamboozlEDR. This tool allows you to inject events into ETW, allowing you to generate fake alerts and blind EDRs.
https://t.co/Gnz0ssUXYN
Slides available here:
https://t.co/2zhhBe83Df
I’m an Incident Responder on the AWS Customer Incident Response Team (CIRT). And I get asked a lot of questions, like:
“Where do I even start with incident response in the cloud?”
Here’s a beginner-friendly thread on AWS IR tips — with a few lessons I learned 🧵👇
Telemetry powers detection, threat hunting, and more—but are you collecting the right data? Not all telemetry is created equal. Understanding primary vs. secondary telemetry sources is critical for collecting the right data for these functions. Read more in my blog: https://t.co/pa0pograHq
🚨 New THOR Collective Dispatch post 🚨
In Part 5 of @jotunvillur and my @DEATHCon2025 Thrunting Workshop series, we use advanced data analysis to find threats in HTTP datasets.
Full post here: https://t.co/qahgbRJaX9
#infosec#threathunting#thrunting#THORCollective#splunk
I frequently get asked is "what skills do I need need to excel as an analyst", so I figure this is a good opportunity to shed some light on what analysis is, and why certifications alone won't make you a good analyst.
https://t.co/EZf9MDdROX
Please Santa please, gimme some #YARA 🎅🎄
This blog post on our use of #YARA rules is also an opportunity for us to announce the release of hundreds of our #YARA rules on GitHub, which are now directly integrated into VirusTotal for detection.
https://t.co/bc0q9YGElQ