Thrilled to share our new paper just dropped in Energy Conversion and Management!
https://t.co/aG5X1Q9v7F
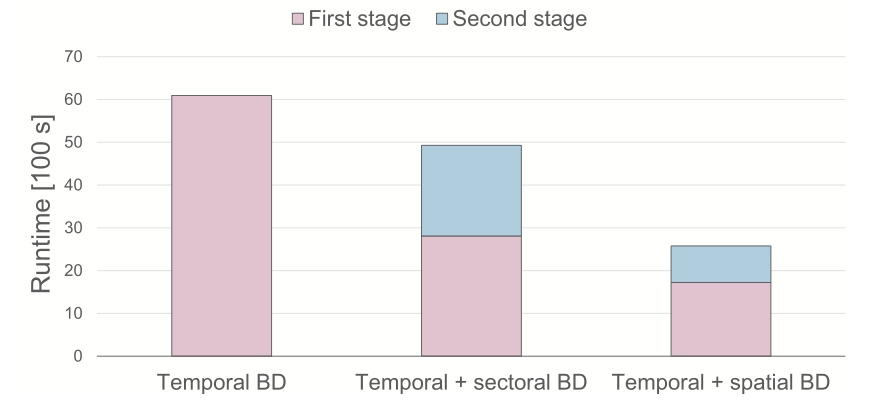
We developed sectoral and spatial Benders decomposition methods that solve large-scale multi-sector energy planning models (electricity, transport, heating…) 15–70% faster when tested on case studies of the continental US. The approach is generic and we hope to publish an implementation in the MacroEnergy.jl code soon.
Big congrats to @FedParolin, who did the heavy lifting, and the rest of the team.
Another great paper by @FedParolin, showing how to decompose large energy system models spatially and by sector, and the significant speed-up this gives large and high-resolution models. This work will allow more models to be scaled up on large computer clusters
#EnergyTwitter #EnergySystems
This is ongoing work, supported by @mitenergy, and we are currently developing several linear approximations to improve runtimes even further. We'll apply these faster models to larger grid case studies.
Are current capacity expansion models missing crucial details for thermal storage? @taemin_heo and I are investigating how storage state-of-charge impacts charge/discharge capacities—and why non-linearities matter for #ZeroCarbon grid planning models: https://t.co/cFxQjs9lRK
Clearly, incorporating these non-linearities increases model runtimes so we've explored the runtime-accuracy trade-off of several approximate models. It's up to each user to decide the best balance for their work but we hope this paper will help inform these decisions.
For anyone modelling long-duration storage in capacity expansion models, Federico Parolin - a visiting PhD student @mitenergy, has just published a new formulation which reduces runtimes by at least 30% in our tests and avoids common constraint violations
The Sustainable Engineering Initiative @nyutandon has multiple postdoc openings on the topic of decarbonizing chemical manufacturing, spanning computational and experimental topics. Miguel Modestino and I are looking to hire researchers across three projects -a thread:
@SamHamels @HighsOpt @JuMPjl@gurobi On the Julia note - if you just want to model a system, not add new features, you can use the current run files without needing to know Julia. You only need to alter the CSV inputs.
That's the big simplification that's come from making DOLPHYN a Julia package.
DOLPHYN, our multi-sector capacity expansion model, is now a Julia package: https://t.co/bIax2tz1x6
This lets you use it directly through Julia and we will continue to make it easier to use.
DOLPHYN currently models H2 and electricity - using GenX as the electricity model
@duncancampbell Not a bad question at all. A lot of it is momentum once the project started in Julia, but we've also been very happy with the runtime and memory performance, and we preferred how JuMP.jl handled model <--> solver control compared to alternatives at the time
@SamHamels @HighsOpt @JuMPjl@gurobi This was something I was looking at this weekend with the new ChatGPT/create tools. As a first step we're going to try have it set up sequences of runs in response to questions, e.g. "How much does the round-trip efficiency of Li-ion matter here"
@whatisnuclear Thermionic conversion always seems a great option to me. There's a great pair of textbooks on the details and pairing with nuclear systems.
https://t.co/18h8WTMLY8
DOLPHYN optimizes energy system models using @HighsOpt by default.
Thanks to @JuMPjl, DOLPHYN can also run with many other solvers. We do most of our testing with HiGHS and @gurobi
This is the product of hard work by the DOLPHYN team, led by @dhariksm, @Guannan_He and myself.
We will soon new sector models for CO2 storage and transport, and biofuels.
Please get in touch if you have questions or would like to add more sectors for your own work.