To address the concerns our customers have today about how their content is being used by crawlers and data scrapers, we are launching the Content Signals Policy. https://t.co/reSgzu74Cv #BirthdayWeek
Excited to partner with @Cloudflare on the launch of the Cloudflare Content Signals Policy to help publishers to assert their rights and clearly define how AI companies may use their content!
Reddit, Yahoo, Medium, Quora, People, O'Reilly, wikiHow, Ziff Davis, and others adopt the Really Simple Licensing (RSL) Standard to set terms for AI scraping (@emroth08 / The Verge)
https://t.co/oV5Lky4eoe
https://t.co/uy3DfoiTiF
A new system called Real Simple Licensing would allow AI companies to license training data at a massive scale — if they're willing to pay for it. https://t.co/ywtHnABxYs
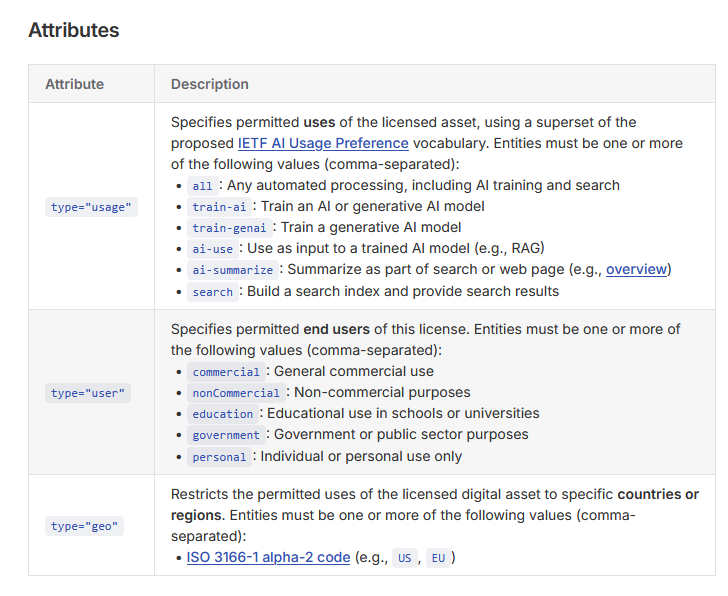
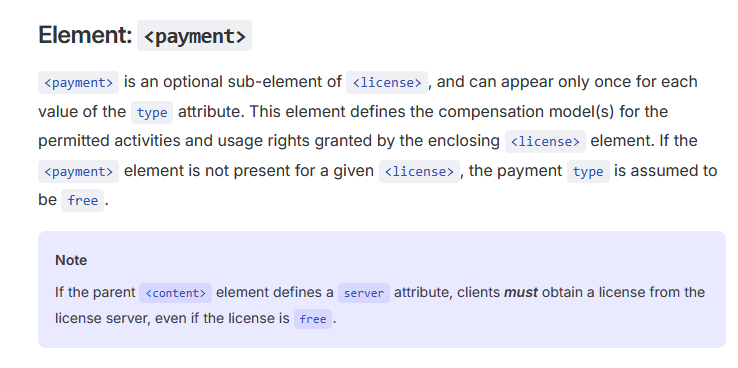
Element: <payment> -> Reddit, Yahoo, Medium, Quora, People, O'Reilly, wikiHow, Ziff Davis, and others adopt the Really Simple Licensing (RSL) standard that sets terms for AI scraping
"The RSL Standard builds upon the robots.txt protocol, which has long allowed publishers to provide instructions to web crawlers about what parts of their site they can and can’t access. But instead of just saying yes or no to specific bots, websites can now add licensing and royalty terms to their robots.txt file. They can also embed the terms in online books, videos, and training datasets that they may want compensation for." https://t.co/v2v34bYIGs
Reddit, Yahoo, Medium, Quora, People, O'Reilly, wikiHow, Ziff Davis, and others adopt the Really Simple Licensing (RSL) Standard to set terms for AI scraping (@emroth08 / The Verge)
https://t.co/vVaa50CUnt
https://t.co/8toa12ImsI
📫 Subscribe: https://t.co/OyWeKSRpIM