New Frontier Red Team blog: Phase 2 of Project Fetch, where we test how well Claude can program a robodog.
Opus 4.7, on its own, was ~20x faster than last year's best human team aided by Opus 4.1. (The robodog, alas, still failed to fetch a beach ball.)
https://t.co/CgbBtRf85e
Or, even Silicon Valley companies that have raised literally $0 outside capital are throwing off so much cash they can solve major medical crises on the side.
We've collaborating with hundreds of physicians across 60 countries, 49 languages, and 26 specialties to make ChatGPT great at health-related questions for everyone:
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: https://t.co/bwn0sximKZ
Three years ago we started working on a stealth project that we weren’t sure we’d ever talk about publicly... until today.
Breakthrough: Introducing LFM-Zero: the first foundation model trained on 0 tokens.
No pretraining. No finetuning. No data. Instead, we initialize from an implicit probabilistic prior over the underlying data-generating process, allowing the model to converge without ever observing data.
LFM-Zero matches or surpasses models trained on 10T+ tokens across reasoning, coding, and multimodal tasks. Turns out that pretraining was just regularization that was holding us back.
> Read our Tech Report here: https://t.co/aIWbx77IEf
Today, we’re launching @Uber Autonomous Solutions—a comprehensive suite of services to help our AV partners commercialize, scale faster, and operate at the standard riders expect.
Last week, I shared the launch of @Uber AV Labs! Here’s a behind-the-scenes look at some of the work the team is doing.
Learn more about AV Labs, explore open roles, and apply directly here:
https://t.co/zf0yVodewp
To support the work of the healthcare and life sciences industries, we're adding over a dozen new connectors and Agent Skills to Claude.
We're hosting a livestream at 11:30am PT today to discuss how to use these tools most effectively.
Learn more: https://t.co/SsKZFaZlnQ
"Memory in the Age of AI Agents" argues that agent memory has become fragmented and earlier papers miss newer directions like tool/skill distillation from experience and memory-augmented test-time scaling. It proposes a unified taxonomy around Forms, Functions and Dynamics
Is there an AI bubble? With the massive number of dollars going into AI infrastructure such as OpenAI’s $1.4 trillion plan and Nvidia briefly reaching a $5 trillion market cap, many have asked if speculation and hype have driven the values of AI investments above sustainable values. However, AI isn’t monolithic, and different areas look bubbly to different degrees.
- AI application layer: There is underinvestment. The potential is still much greater than most realize.
- AI infrastructure for inference: This still needs significant investment.
- AI infrastructure for model training: I’m still cautiously optimistic about this sector, but there could also be a bubble.
Caveat: I am absolutely not giving investment advice!
AI application layer. There are many applications yet to be built over the coming decade using new AI technology. Almost by definition, applications that are built on top of AI infrastructure/technology (such as LLM APIs) have to be more valuable than the infrastructure, since we need them to be able to pay the infrastructure and technology providers.
I am seeing many green shoots across many businesses that are applying agentic workflows, and am confident this will grow. I have also spoken with many Venture Capital investors who hesitate to invest in AI applications because they feel they don’t know how to pick winners, whereas the recipe for deploying $1B to build AI infrastructure is better understood. Some have also bought into the hype that almost all AI applications will be wiped out merely by frontier LLM companies improving their foundation models. Overall, I believe there is significant underinvestment in AI applications. This area remains a huge focus for my venture studio, AI Fund.
AI infrastructure for inference. Despite AI’s low penetration today, infrastructure providers are already struggling to fulfill demand for processing power to generate tokens. Several of my teams are worried about whether we can get enough inference capacity, and both cost and inference throughput are limiting our ability to use even more. It is a good problem to have that businesses are supply-constrained rather than demand-constrained. The latter is a much more common problem, when not enough people want your product. But insufficient supply is nonetheless a problem, which is why I am glad our industry is investing significantly in scaling up inference capacity.
As one concrete example of high demand for token generation, highly agentic coders are progressing rapidly. I’ve long been a fan of Claude Code; OpenAI Codex also improved dramatically with the release of GPT-5; and Gemini 3 has made Google CLI very competitive. As these tools improve, their adoption will grow. At the same time, overall market penetration is still low, and many developers are still using older generations of coding tools (and some aren’t even using any agentic coding tools). As market penetration grows — I’m confident it will, given how useful these tools are — aggregate demand for token generation will grow.
I predicted early last year that we’d need more inference capacity, partly because of agentic workflows. Since then, the need has become more acute. As a society, we need more capacity for AI inference.
Having said that, I’m not saying it’s impossible to lose money investing in this sector. If we end up overbuilding — and I don’t currently know if we will — then providers may end up having to sell capacity at a loss or at low returns. I hope investors in this space do well financially. The good news, however, is that even if we overbuild, this capacity will get used, and it will be good for application builders!
AI infrastructure for model training. I am happy to see the investments going into training bigger models. But, of the three buckets of investments, this seems the riskiest. If open-source/open-weight models continue to grow in market share, then some companies that are pouring billions into training models might not see an attractive financial return on their investment.
Additionally, algorithmic and hardware improvements are making it cheaper each year to train models of a given level of capability, so the “technology moat” for training frontier models is weak. (That said, ChatGPT has become a strong consumer brand, and so it enjoys a strong brand moat, while Gemini, assisted by Google's massive distribution advantage, is also making a strong showing.)
I remain bullish about AI investments broadly. But what is the downside scenario — that is, is there a bubble that will pop? One scenario that worries me: If part of the AI stack (perhaps in training infra) suffers from overinvestment and collapses, it could lead to negative market sentiment around AI more broadly and an irrational outflow of interest away from investing in AI, despite the field overall having strong fundamentals. I don’t think this will happen, but if it does, it would be unfortunate since there’s still a lot of work in AI that I consider highly deserving of much more investment.
Warren Buffett popularized Benjamin Graham’s quote, “In the short run, the market is a voting machine, but in the long run, it is a weighing machine.” He meant that in the short term, stock prices are driven by investor sentiment and speculation; but in the long term, they are driven by fundamental, intrinsic value. I find it hard to forecast sentiment and speculation, but am very confident about the long-term health of AI’s fundamentals. So my plan is just to keep building!
[Original text: https://t.co/psPlIFRJsi ]
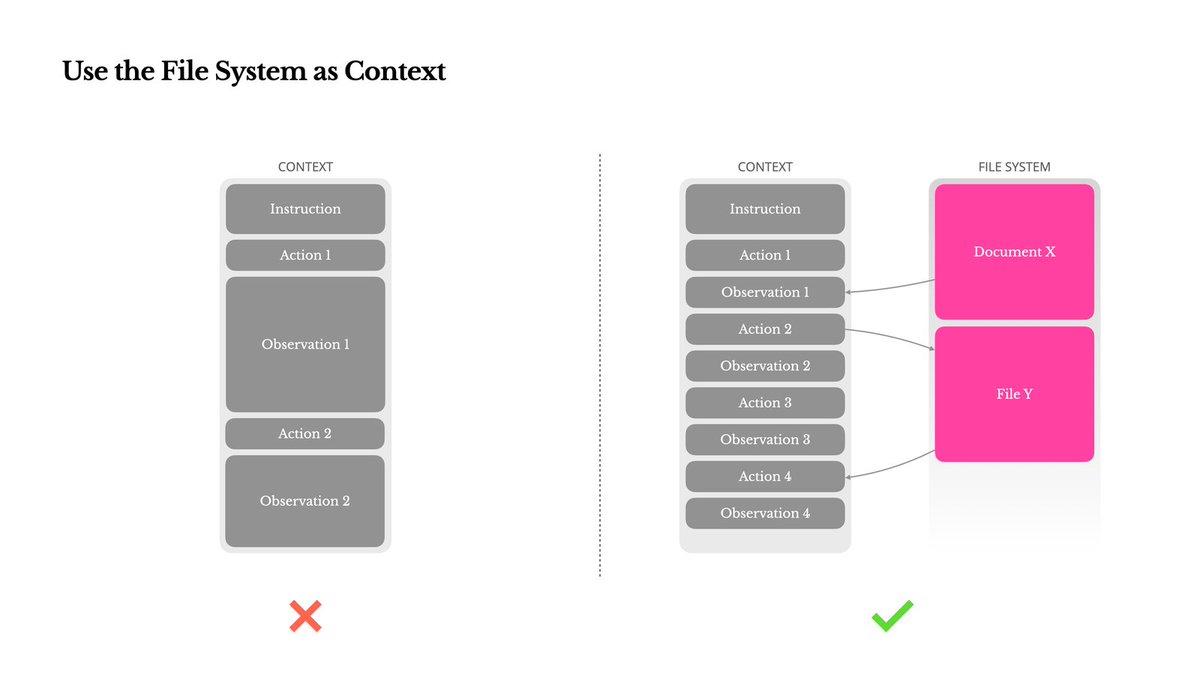
📁How agents can use filesystems for context engineering
The hardest part of building reliable agents is "context engineering"
Filesystems are a useful abstraction for letting the agent manage it's own state - aka do it's own context engineering. It's a key part of Deep Agents and Manus and Claude Code
Blog: https://t.co/DemfyTwj4V
(image from @ManusAI team)
It is with more sadness than mere words can convey that we have to report that our beloved Ozzy Osbourne has passed away this morning. He was with his family and surrounded by love.
We ask everyone to respect our family privacy at this time.
Sharon, Jack, Kelly, Aimee and Louis