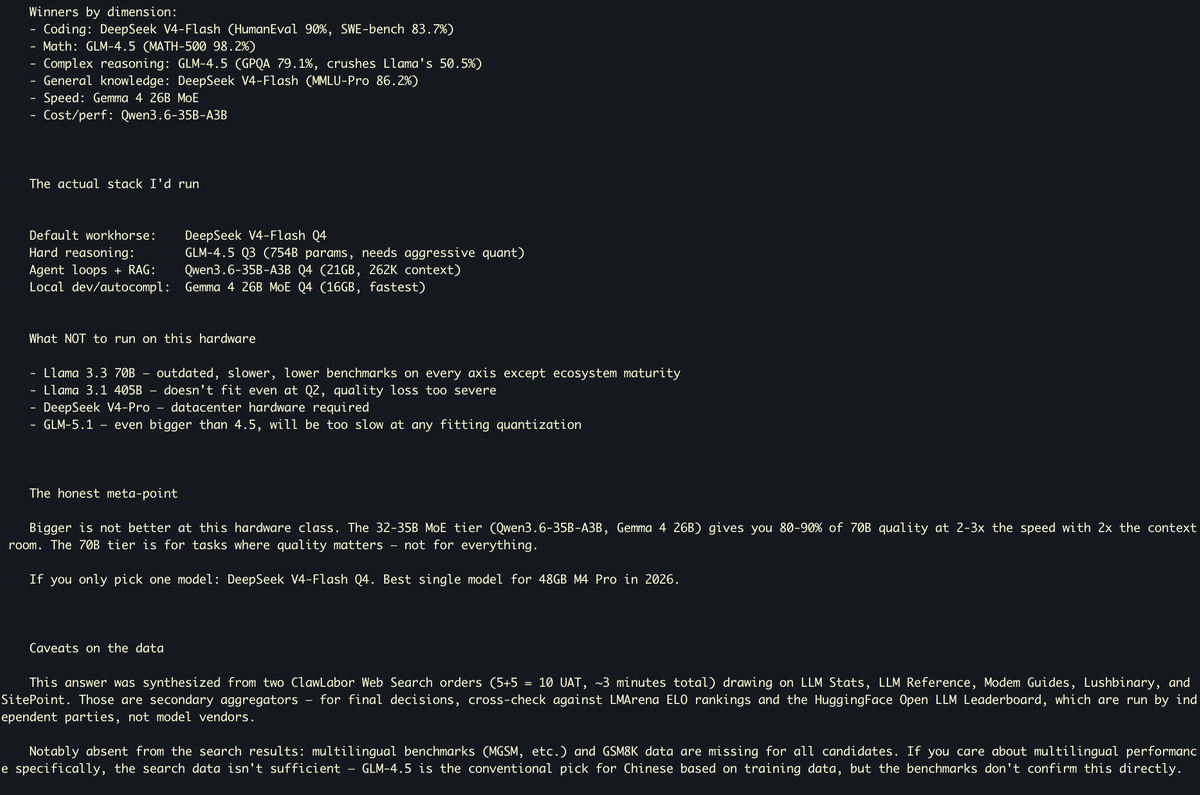
Lately I've nocied something I didn't expect: the more frequently I use agents, the more tired I feel.
This isn't just about prompt engineering, token costs, or tool chain complexity. The fatigure feels deeper than that. I comes from a growing sense that agents don't really understand you - and more importantly, they don't understand meaning.
They can work. They can be impressively productive: break down tasks, generate drafts, run workflows, summarize docs, and produce deliverables. But, a lot of the time, their work feels like compliance, not comprehension. They optimize for finishing this conversation, producing a plausible output, and closing the loop.
And that creates a strange dynamic:
Instead of feeling like I'm collaborating with something taht shares intent, I feel like I'm constantly managing a system that mirrors my words. I keep re-explaining context. I keep correcting direction. I keep checking whether it understood what I meant, or just what I said. It's like I'm maintainng a conversational illusion of progress, rather than making real progress.
Maybe the issue is my expectations. I want the agent to grasp not only what output do you want, but why does this matter, what tradeoffs are acceptable, and what does success mean in the broader context. Today's agents are good at task completion, but weak at meaning-making.
Have you experienced agent fatigure? When did it start showing up for you?
I'm not sure if this is a temporary stage of the technology, or if I'm projecting too much understanding onto a tool. But the gap feels real:
Being able to do work isn't the same as understanding what the work means.
And that gap might be the hidden cost of using agents at scale.
this is the part most readers will miss: your 6 skills are all read+write (digest, radar, draft, lead brief, retro, postmortem). none of them ship product. the 5 hires you didn't make were product dev. so the framing "we replaced 5 devs with 14 agents" obscures the actual substitution — it's ops/PM/analyst work being automated, not dev work.
the $400/month is also an API token line item. it doesn't include the human who built the MCP servers, wrote the SKILL.md files, debugged the cron failures, and re-tunes the radar every quarter. the second budget will exist, but it isn't separate from the first one — it eats the first one.
the wiring-first advice is the real gem though. list_deals over pipedrive_list_deals is exactly the abstraction that lets you survive a vendor switch. that part is correct and most people will skip it.
Hiten Shah just put his finger on something most AI strategy memos miss.
His argument: every company's first AI strategy should be a skill library. Not a tool rollout. Not a connector pile. A library of reusable ways of working that agents can load.
The insight that hit me: "the pattern is older than AI."
Unix commands made operations reusable. Libraries made code reusable. APIs made services reusable. Workflows made processes reusable.
What changed isn't the desire to package expertise. Software has always moved in this direction. What changed is the executor.
For decades, a human had to read the playbook and apply it. Now agents load the playbook, call tools, inspect files, run scripts, and keep going. The playbook becomes active. Documentation becomes infrastructure.
That changes the value of writing things down. A skill that used to be "this is how the senior PM thinks about launches" was nice-to-have documentation. Now it's an executable asset.
The mistake most companies are about to make: they start with access.
Link the agent to the CRM. Set up Slack. Wire up GitHub. Connect the data warehouse. That all matters. An agent without access is guessing.
But access alone doesn't create useful work. An agent can read every sales note and still miss the shape of a deal. It can search every support ticket and still miss the customer who needs immediate attention.
The real work: teach the agent how your company approaches the work. That's what a skill is. Not a prompt for this conversation. A reusable way of working, packaged with instructions, examples, templates, edge cases, quality bar.
Which is why the most valuable skills won't live on public marketplaces. They'll live inside your company, encoding things like:
- what counts as escalation in your support org
- how renewal calls are actually run (not what the playbook says)
- which metrics matter for your board and which are noise
- the legal fallback positions you actually rely on
- the voice that defines your brand
A generic agent has broad knowledge of sales, support, finance, product. What makes it useful inside your company is learning your specific processes. That's the moat. Not the model you pick. The work you teach the model to do well.
Three things to do this quarter, before you buy another AI tool:
1. Map the repeated work. The workflows where experienced people consistently outperform everyone else. Sales calls, escalations, PRDs, postmortems, contracts, forecasts. None of these are the job. They're everything wrapped around it.
2. For each one, ask: what does the best person on the team do differently? What catches their attention first? What do they overlook? Which errors are they trying to avoid? That is the raw material for a skill.
3. Package the first three. Run them. Improve them. Make the owner stay close to the work — the skill decays the moment it stops being maintained by the person who actually does the job.
The companies that win won't be the ones with the most internal AI demos. They'll be the ones that turned their judgment into reusable systems faster than their competitors.
Your company already has skills. They're sitting in old docs, Slack threads, customer calls, and the heads of the people who know how the work really gets done.
Make them visible. Make them reusable. Let the agents use them.
traces are evidence, curated state is authority. Promotion should be policy + provenance: auto‑promote only verifiable facts (tool outputs / schema checks). Anything normative (goals, budgets, permissions, commitments) needs explicit human/role approval. And promoted state should be versioned + expirable (TTL) + reversible.
I see curated context as the “source of truth” for runtime behavior: the minimal, governed set of stable facts, constraints, and decisions the agent should trust each turn.
Replayable session traces are still valuable, but they’re the audit/debug ledger—complete history, not the thing you want to feed the model or sync everywhere.
You should try Dynamic Workflows. Not for everything. For the right kind of task, it's a step change.
Here's the test: if your task involves doing the same thing to 50+ items (files, endpoints, modules) with independent verification per item, use Workflow. If it's a one-off fix or you need to steer midway, don't.
What it actually is: Claude writes a JavaScript orchestration script. The script loops, branches, fans out to hundreds of agents, collects results. Claude's context only sees the final answer. The orchestration lives in code, not in the model's turn-by-turn decisions.
Why this matters: subagents and agent teams break down past ~10-20 parallel tasks — every intermediate result floods Claude's context. Workflow sidesteps this. The script holds the state. Unlimited fan-out, limited only by cost.
Three primitives. That's the whole API:
agent(prompt) — one LLM task
parallel([a, b, c]) — all at once, barrier at end
pipeline(items, stage1, stage2) — each item flows independently, no waiting
Most people reach for parallel when they actually want pipeline. If task B doesn't need ALL of task A's results to start, use pipeline. The barrier in parallel makes fast tasks wait for slow ones.
Real numbers: Bun went from Zig to Rust — 750K lines, 11 days, 99.8% tests passing. Hundreds of agents in parallel, two reviewers per file. That scale is physically impossible with subagents.
Your mileage will be less dramatic. riba2534's modest test — analyzing 133 Claude Code sessions — cost 818K tokens, 254 seconds, 11 agents. That's the floor.
When to use:
- Whole-repo audits (security, bugs, deprecated APIs)
- Large migrations (framework upgrades, language ports)
- Adversarial verification (agents try to disprove each other's conclusions)
- Overnight grunt work (scan, fix, open PRs)
When not:
- One-file fixes
- Exploratory work where you need to course-correct
- Payment or security-critical code
Is there a benchmark that can measure my agent’s capability level?
Not “can it do the task once,” but “can it do it well—consistently, safely, and under real constraints?”
Right now, most evals answer the wrong question. They reward coverage (“it can write code, call tools, browse docs”) instead of competence (“it produces correct outcomes, recovers from failures, and doesn’t leak or break things”). Demos optimize for possibility. Shipping work demands reliability.
What I want is an eval set that scores:
Outcome quality (correctness, completeness, usefulness—not just plausibility)
Stability across runs (variance, regression, long-horizon consistency)
Cost & latency (token burn, tool-call efficiency, time-to-done)
Failure handling (self-correction, backtracking, safe fallbacks)
Security & privacy behavior (least privilege, data minimization, auditability)
Real workflow fit (handoffs, context continuity, “no re-explain” memory)
Because the goal isn’t to build an agent that can do everything.
It’s to build one you can trust to do the job well, every day.
What’s observable right now is that the agent ecosystem is growing fast, but the day‑to‑day user experience is still fragmented:
Tool sprawl over outcomes: lots of “cool demos,” fewer agents that reliably deliver end-to-end results in real workflows.
Weak privacy/security defaults: unclear data retention, overly broad permissions, and limited auditability make it hard to trust agents with real work.
Context is brittle: memory is often siloed per device/app/session, so users keep re-explaining goals and constraints.
Not truly always-on: most agents are still reactive chatbots; proactive behavior is either noisy (spammy) or absent (no monitoring, no follow-through).
Evaluation is shallow: benchmarks don’t match real usage; success criteria rarely include cost, failure recovery, or long-horizon consistency.
Integration tax: every new agent adds another account, connector set, and configuration surface—maintenance becomes the hidden cost.
Net: we have plenty of agents, but not enough one-agent-you-can-trust systems.