Software Architect | Visual Storyteller Turning Complex Systems into Actionable Insights | System Design & Architecture | Cloud & Agentic AI | IBM Champion
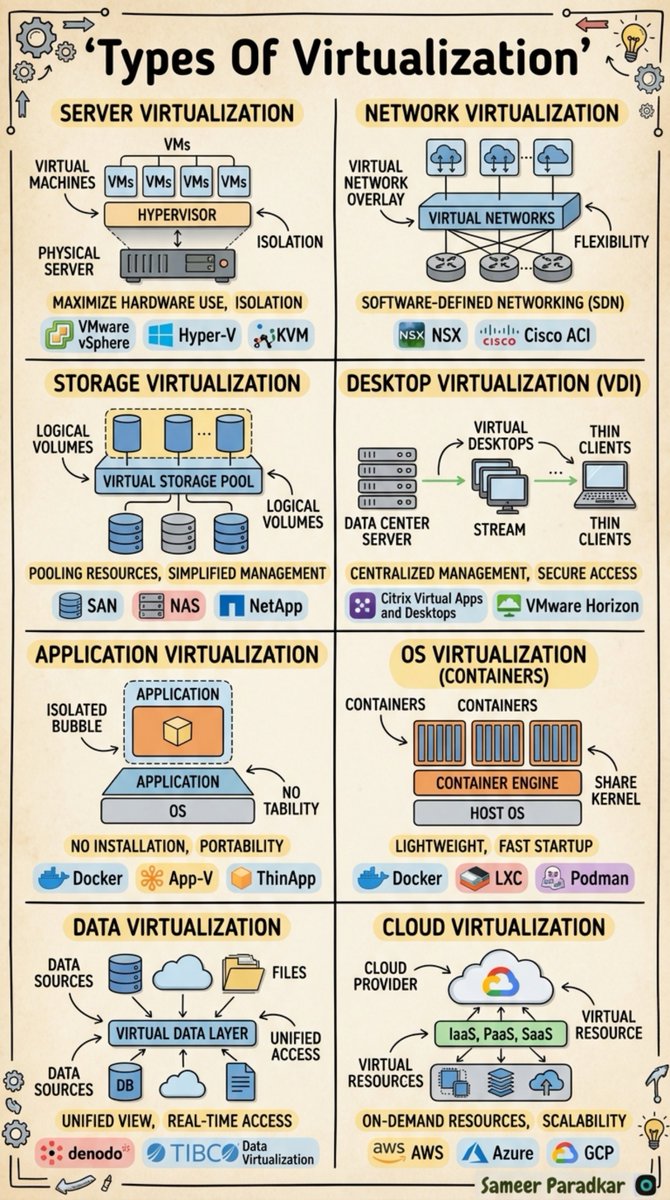
Most people think virtualisation is one thing. It's eight — and picking the wrong one costs you in complexity, performance, and security.
Server Virtualisation: full OS isolation via hypervisor. OS Virtualisation: containers sharing the kernel — same concept, fraction of the overhead, different security boundary. Confusing these two alone breaks architectures.
The six that get underused:
→ Storage → pool resources, simplify management
→ Network → software-defined, flexible as code
→ Desktop VDI → centralised, secure, no data on endpoints
→ Application → portable, no installation, isolated bubble
→ Data → unified access without moving the data
→ Cloud → IaaS, PaaS, SaaS on demand
Every type abstracts a specific resource boundary. Match the abstraction to the problem. Virtualise everything without intent and the complexity doesn't pay off.
For a deeper dive → https://t.co/JHAfUGjWoz
Most API security incidents aren't from bad implementation. They're from the wrong authentication method chosen for the wrong use case.
6 methods. Each solves a different problem:
→ API Key: identifying apps, not users — simplest choice
→ Basic Auth: dev/testing only — never production
→ JWT: stateless, scalable — SPAs, mobile, microservices
→ OAuth 2.0: delegated access — social login, third-party
→ Session/Cookie: stateful — traditional SSR web apps
→ mTLS: both sides verify — banking, healthcare, zero-trust
Security level: Basic (Low) → API Key/Session (Medium) → JWT/OAuth (High) → mTLS (Highest)
Right method. Right context. Before the first endpoint ships.
#APISecurity #SystemDesign #BackendEngineering #Authentication #JWT #OAuth
Most engineers know what servers they're running. Few know what problem each one actually solves.
9 servers. 9 specific failure modes eliminated:
→ Web Server → static content at scale
→ App Server → business logic and APIs
→ Database → persistent data, ACID guarantees
→ Cache → repeated reads, sub-ms latency
→ Proxy → traffic, security, rate limiting
→ Message Queue → async decoupling, no cascades → File/Storage → objects, media, backups
→ Auth Server → identity, tokens, SSO, RBAC
→ Search Server → full-text search databases can't do
The three added reactively instead of proactively — Message Queue, Auth, Search. By the time the pain is visible, the refactor is expensive.
Know what each one solves. Add it before you need it.
I've reviewed hundreds of system design sessions. The same 9 mistakes appear every time. The scariest part? Most engineers don't know they're making them.
The first mistake happens before the marker cap is off. Someone opens a whiteboard and starts drawing microservices. No requirements, no constraints, no scope. The architecture is already wrong.
NFRs — scalability, security, performance — get treated as optional extras. They're not features. They're the constraints that determine whether your system survives production. Skip them upfront, pay for them in incidents.
Over-engineering is the mistake senior engineers make most. A distributed system designed for 10 million users serving 10 thousand. Complexity isn't sophistication. It's debt you haven't paid yet.
"There are no trade-offs. This design is optimal." That answer fails every serious design review. Every choice has a cost. If you can't name it, you don't own the decision.
Single point of failure dressed up as simplicity. One database, one server, one region. One failure from everything going down simultaneously.
Vague hand-waving — "we'll just use Kafka," "we'll deploy to the cloud" — without justification isn't a design. Ambiguity on the whiteboard becomes the incident nobody can diagnose.
And the mistake you only regret at 2am: shipping without observability. No logging, no tracing, no alerting. A black box running in production you can't see inside when it starts failing. And it will.
These aren't made by bad engineers. They're made by good engineers moving too fast without a checklist.
The best system designers aren't the smartest in the room. They're the ones who slow down before the first box gets drawn.
Most engineers know 4 of these 16 concepts. They call it "system design knowledge."
Then they get paged at 2am wondering why their architecture collapsed.
Here's what's actually happening inside every large-scale system — and what's silently missing from yours.
Load balancing and caching are the ones everyone learns first. Distribute traffic. Cache the data. Basic. Necessary. And completely insufficient on their own.
Here's what nobody tells you:
The teams that get paged most aren't missing load balancers. They're missing Circuit Breakers.
One slow downstream service. Upstream keeps calling it. Thread pool exhausts. Everything degrades simultaneously. The cascade nobody saw coming — because the pattern that stops it was never added.
Then there's Consistent Hashing — the reason Cassandra and DynamoDB don't collapse when you add a node. Without it, a topology change remaps your entire cache keyspace. Every miss hits the database at once. One scaling event becomes an outage.
Most teams discover this during their first major traffic event. Not before.
Event-Driven Architecture sounds like a nice architectural principle. It isn't. It's the pattern that stops one service's failure from becoming every service's problem. Teams that skip it build systems where everything is simultaneously everyone else's dependency. It fails slowly, then all at once.
Service Discovery is the concept nobody thinks about until they have 50 services and a deployment breaks routing for three of them simultaneously.
And Observability — Logs, Metrics, Traces — is always the last thing added and the first thing needed when something goes wrong.
Here's the uncomfortable truth:
Every single one of these 16 concepts exists because a real system failed without it. Not a demo. Not a staging environment. Production. With users. With data. With consequences.
You can learn these concepts from a visual.
Or you can learn them from an incident.
The visual is faster.
For a deeper dive → https://t.co/JHAfUGjWoz
Most engineers can name these 12 algorithms. Almost none can explain why the wrong one in the wrong place took down a production system.
That gap is where incidents live.
Consistent Hashing isn't just a concept for interviews. It's the reason your Cassandra cluster doesn't redistribute every key when you add a node. Get it wrong and a single topology change becomes a full cache invalidation event. At scale, that's a database flood nobody budgeted for.
Leader Election via Raft isn't academic. It's running inside etcd right now, making scheduling decisions for every pod in your Kubernetes cluster. Without it — split-brain. Two leaders. Two sources of truth. One very bad day.
Rate limiting with Token Bucket vs Leaky Bucket is a trade-off conversation most teams never have. Token Bucket allows burst traffic. Leaky Bucket enforces steady flow. Choose wrong for your traffic pattern and you either throttle legitimate users or let a traffic spike through that your downstream can't handle.
Exponential backoff without jitter doesn't stabilise systems under failure. It synchronises retry storms. Every client backs off the same amount. Every client retries at the same moment. The recovering service gets hammered simultaneously by every caller that was waiting. Partial failure becomes complete failure.
Quorum-based replication with R=2, W=2, N=3 is how you configure the consistency-availability dial on a distributed database. Most engineers who use Cassandra have never consciously set those values with intent. They're using defaults and calling it a consistency strategy.
Sliding Window is how real-time monitoring works at scale. Not batch aggregation. Not periodic snapshots. A continuously moving window over a stream of events, computing metrics as data flows through. The algorithm underneath every dashboard that feels instant.
Topological Sort is dependency resolution. Build systems use it. Workflow orchestrators use it. Kubernetes uses it for pod startup ordering. The engineer who understands why it's the right algorithm here will apply the same reasoning across every system they ever design.
Here's the uncomfortable truth:
Frameworks change. APIs get deprecated. Cloud services get renamed. The algorithms underneath don't. The engineer who understands these twelve will outdesign the one who memorised the latest framework — in every interview, every architecture review, every incident post-mortem, for the rest of their career.
Algorithmic knowledge doesn't expire.
Everything else does.
For a deeper dive → https://t.co/QRbUAnudax
Most production bugs weren't missed by your test suite. They were never covered by it.
That's a different problem. And it's more expensive.
Unit tests verify isolated logic. Fast, necessary, and dangerously insufficient on their own. The bug that takes down production almost never lives in a single function. It lives in the interaction between services — the place your unit tests structurally cannot see.
Integration testing catches the contract failures unit tests miss by design. Two services passing all their tests. Failing when they talk to each other. One changed an API response format. The other was never told. Pact exists because this failure mode is so predictable that someone built an entire framework around stopping it.
Performance testing is where the gap between staging and production becomes visible. Most teams skip it until a traffic event does it for them — and discovers, in production, that the thread pool exhausts at 300 concurrent users. That number was predictable. Nobody measured it.
Stress testing finds your breaking point. Most teams don't know what theirs is. They find out when CPU maxes out and OOM errors start cascading. Chaos Monkey and Gremlin exist because deliberately breaking systems in controlled conditions is infinitely cheaper than accidentally breaking them in front of users.
Security testing is deferred longest and regretted most. Vulnerability scans, injection detection, OWASP coverage — consistently treated as someone else's problem until the CVE surfaces and it becomes everyone's emergency.
UAT fails silently and often. The system passes every technical test. The business rejects it. Technically correct. Operationally wrong. The feature satisfied the ticket but not the requirement behind it.
Here's the uncomfortable truth nobody says directly:
Testing doesn't improve quality. It reveals quality.
A comprehensive test suite on poorly designed software is just an expensive way to document the problems you already have.
Build quality in. Use testing to confirm it.
For a deeper dive → https://t.co/QRbUAnudax
Most performance problems aren't solved by buying more infrastructure.
They're solved by stopping the system from doing work it never needed to do. That's the insight teams consistently miss — until the AWS bill forces the conversation nobody wanted to have.
Caching is the highest-leverage technique available. And the most frequently implemented wrong. No TTL discipline. No invalidation strategy. Cache added as an afterthought, not a design. A misconfigured cache doesn't just fail to help — it adds a debugging layer while delivering zero performance benefit.
Database optimisation is where the most expensive debt accumulates silently. Unindexed queries that work on 10,000 rows. Collapse on 10 million. No partitioning on tables that were always going to grow. These aren't surprises. They're the predictable outcome of never testing against realistic data volumes.
Async processing is the technique that removes the most latency from user-facing operations — and the one teams add after the first traffic incident instead of before it. Email, reports, file uploads, webhooks. None of these belong in a synchronous request cycle. Every team learns this the same way. In production. Under load. At the worst possible moment.
CDNs are treated as optional by teams building global products. They're not. The difference between a 50ms response and a 400ms one is often just geography. Your users in high-latency regions don't know why it's slow. They just leave.
Monitoring and profiling is the technique that exposes whether any of this is actually working. Without it, you're optimising blind. Implementing every technique in this visual without instrumentation is just expensive guesswork.
Here's the hard truth:
Performance isn't a feature. It's a property you design for from the first architectural decision. The teams that ship fast systems aren't running better hardware.
They refused to accept "we'll optimise later" as an answer.
Because "we'll optimise later" is how you inherit a rewrite.
For a deeper dive → https://t.co/JHAfUGjWoz
Every distributed system will fail. The only question is whether you designed for it.
Most teams don't. They discover their failure modes in production, under load, at the worst possible moment.
Circuit Breaker stops cascades. One dependency slows down, thread pools exhaust, everything fails simultaneously. One pattern, configured before the incident, contains it. It appears in post-mortems more than architecture diagrams. That's the problem.
Retry without jitter doesn't stabilise systems. It synchronises retry storms. Every caller retries at the same moment, floods the recovering service, turns partial failure into complete failure. The jitter isn't a detail — it's the entire algorithm.
Bulkhead means a payment service degrading never cascades into your recommendation service. Separate concerns fail separately. This is a design decision, not an operational one.
Graceful degradation keeps the system usable under stress. Reduced features. Low-fidelity mode. Core functionality alive. The user who gets a degraded experience is infinitely preferable to the user who gets an error page.
Load shedding requires explicitly deciding what to drop. That's uncomfortable. The alternative — accepting all work until resources exhaust and everything drops simultaneously — is worse.
The systems that survive at scale weren't built to avoid failure.
They were built to contain it.
For a deeper dive → https://t.co/JHAfUGjWoz
Most data platform projects fail before a single query runs. Not because of the technology — because nobody decided who owns the data.
A central data team becomes the bottleneck for every team in the company. Every pipeline change waits in one queue, every schema update needs one approval, every ML model blocked on one team's priorities. That's not a data problem. That's an org design problem a bigger Snowflake contract won't fix.
Data Mesh exists because centralised platforms stop scaling when organisations do. Domain ownership, data as product, federated governance, self-serve infrastructure — four decisions that move data ownership from a central bottleneck to the teams who actually understand it.
The platform decision most teams skip entirely: Databricks for unified analytics and ML, Snowflake for cloud warehousing, BigQuery for serverless petabyte scale, AWS Stack for AWS-native, Synapse for Azure enterprise. Wrong choice compounds every year you delay the migration conversation.
And the truth nobody says in the vendor demo: governance isn't a layer you add at the end. It's the foundation that determines whether your data is trustworthy enough to make decisions from — or just expensive to store.
A data platform without governance is a data swamp with better branding.
For a deeper dive → https://t.co/JHAfUGjWoz
Most data platform projects fail before a single query runs. Not because of the technology — because nobody decided who owns the data.
A central data team becomes the bottleneck for every team in the company. Every pipeline change waits in one queue, every schema update needs one approval, every ML model blocked on one team's priorities. That's not a data problem. That's an org design problem a bigger Snowflake contract won't fix.
Data Mesh exists because centralised platforms stop scaling when organisations do. Domain ownership, data as product, federated governance, self-serve infrastructure — four decisions that move data ownership from a central bottleneck to the teams who actually understand it.
The platform decision most teams skip entirely: Databricks for unified analytics and ML, Snowflake for cloud warehousing, BigQuery for serverless petabyte scale, AWS Stack for AWS-native, Synapse for Azure enterprise. Wrong choice compounds every year you delay the migration conversation.
And the truth nobody says in the vendor demo: governance isn't a layer you add at the end. It's the foundation that determines whether your data is trustworthy enough to make decisions from — or just expensive to store.
A data platform without governance is a data swamp with better branding.
For a deeper dive → https://t.co/JHAfUGjWoz
Every distributed system will fail. The only question is whether you designed for it.
Most teams don't. They discover their failure modes in production, under load, at the worst possible moment.
Circuit Breaker stops cascades. One dependency slows down, thread pools exhaust, everything fails simultaneously. One pattern, configured before the incident, contains it. It appears in post-mortems more than architecture diagrams. That's the problem.
Retry without jitter doesn't stabilise systems. It synchronises retry storms. Every caller retries at the same moment, floods the recovering service, turns partial failure into complete failure. The jitter isn't a detail — it's the entire algorithm.
Bulkhead means a payment service degrading never cascades into your recommendation service. Separate concerns fail separately. This is a design decision, not an operational one.
Graceful degradation keeps the system usable under stress. Reduced features. Low-fidelity mode. Core functionality alive. The user who gets a degraded experience is infinitely preferable to the user who gets an error page.
Load shedding requires explicitly deciding what to drop. That's uncomfortable. The alternative — accepting all work until resources exhaust and everything drops simultaneously — is worse.
The systems that survive at scale weren't built to avoid failure.
They were built to contain it.
For a deeper dive → https://t.co/JHAfUGjWoz
Most performance problems aren't solved by buying more infrastructure.
They're solved by stopping the system from doing work it never needed to do. That's the insight teams consistently miss — until the AWS bill forces the conversation nobody wanted to have.
Caching is the highest-leverage technique available. And the most frequently implemented wrong. No TTL discipline. No invalidation strategy. Cache added as an afterthought, not a design. A misconfigured cache doesn't just fail to help — it adds a debugging layer while delivering zero performance benefit.
Database optimisation is where the most expensive debt accumulates silently. Unindexed queries that work on 10,000 rows. Collapse on 10 million. No partitioning on tables that were always going to grow. These aren't surprises. They're the predictable outcome of never testing against realistic data volumes.
Async processing is the technique that removes the most latency from user-facing operations — and the one teams add after the first traffic incident instead of before it. Email, reports, file uploads, webhooks. None of these belong in a synchronous request cycle. Every team learns this the same way. In production. Under load. At the worst possible moment.
CDNs are treated as optional by teams building global products. They're not. The difference between a 50ms response and a 400ms one is often just geography. Your users in high-latency regions don't know why it's slow. They just leave.
Monitoring and profiling is the technique that exposes whether any of this is actually working. Without it, you're optimising blind. Implementing every technique in this visual without instrumentation is just expensive guesswork.
Here's the hard truth:
Performance isn't a feature. It's a property you design for from the first architectural decision. The teams that ship fast systems aren't running better hardware.
They refused to accept "we'll optimise later" as an answer.
Because "we'll optimise later" is how you inherit a rewrite.
For a deeper dive → https://t.co/JHAfUGjWoz
Most production bugs weren't missed by your test suite. They were never covered by it.
That's a different problem. And it's more expensive.
Unit tests verify isolated logic. Fast, necessary, and dangerously insufficient on their own. The bug that takes down production almost never lives in a single function. It lives in the interaction between services — the place your unit tests structurally cannot see.
Integration testing catches the contract failures unit tests miss by design. Two services passing all their tests. Failing when they talk to each other. One changed an API response format. The other was never told. Pact exists because this failure mode is so predictable that someone built an entire framework around stopping it.
Performance testing is where the gap between staging and production becomes visible. Most teams skip it until a traffic event does it for them — and discovers, in production, that the thread pool exhausts at 300 concurrent users. That number was predictable. Nobody measured it.
Stress testing finds your breaking point. Most teams don't know what theirs is. They find out when CPU maxes out and OOM errors start cascading. Chaos Monkey and Gremlin exist because deliberately breaking systems in controlled conditions is infinitely cheaper than accidentally breaking them in front of users.
Security testing is deferred longest and regretted most. Vulnerability scans, injection detection, OWASP coverage — consistently treated as someone else's problem until the CVE surfaces and it becomes everyone's emergency.
UAT fails silently and often. The system passes every technical test. The business rejects it. Technically correct. Operationally wrong. The feature satisfied the ticket but not the requirement behind it.
Here's the uncomfortable truth nobody says directly:
Testing doesn't improve quality. It reveals quality.
A comprehensive test suite on poorly designed software is just an expensive way to document the problems you already have.
Build quality in. Use testing to confirm it.
For a deeper dive → https://t.co/QRbUAnudax
Most engineers can name these 12 algorithms. Almost none can explain why the wrong one in the wrong place took down a production system.
That gap is where incidents live.
Consistent Hashing isn't just a concept for interviews. It's the reason your Cassandra cluster doesn't redistribute every key when you add a node. Get it wrong and a single topology change becomes a full cache invalidation event. At scale, that's a database flood nobody budgeted for.
Leader Election via Raft isn't academic. It's running inside etcd right now, making scheduling decisions for every pod in your Kubernetes cluster. Without it — split-brain. Two leaders. Two sources of truth. One very bad day.
Rate limiting with Token Bucket vs Leaky Bucket is a trade-off conversation most teams never have. Token Bucket allows burst traffic. Leaky Bucket enforces steady flow. Choose wrong for your traffic pattern and you either throttle legitimate users or let a traffic spike through that your downstream can't handle.
Exponential backoff without jitter doesn't stabilise systems under failure. It synchronises retry storms. Every client backs off the same amount. Every client retries at the same moment. The recovering service gets hammered simultaneously by every caller that was waiting. Partial failure becomes complete failure.
Quorum-based replication with R=2, W=2, N=3 is how you configure the consistency-availability dial on a distributed database. Most engineers who use Cassandra have never consciously set those values with intent. They're using defaults and calling it a consistency strategy.
Sliding Window is how real-time monitoring works at scale. Not batch aggregation. Not periodic snapshots. A continuously moving window over a stream of events, computing metrics as data flows through. The algorithm underneath every dashboard that feels instant.
Topological Sort is dependency resolution. Build systems use it. Workflow orchestrators use it. Kubernetes uses it for pod startup ordering. The engineer who understands why it's the right algorithm here will apply the same reasoning across every system they ever design.
Here's the uncomfortable truth:
Frameworks change. APIs get deprecated. Cloud services get renamed. The algorithms underneath don't. The engineer who understands these twelve will outdesign the one who memorised the latest framework — in every interview, every architecture review, every incident post-mortem, for the rest of their career.
Algorithmic knowledge doesn't expire.
Everything else does.
For a deeper dive → https://t.co/QRbUAnudax
Most engineers know 4 of these 16 concepts. They call it "system design knowledge."
Then they get paged at 2am wondering why their architecture collapsed.
Here's what's actually happening inside every large-scale system — and what's silently missing from yours.
Load balancing and caching are the ones everyone learns first. Distribute traffic. Cache the data. Basic. Necessary. And completely insufficient on their own.
Here's what nobody tells you:
The teams that get paged most aren't missing load balancers. They're missing Circuit Breakers.
One slow downstream service. Upstream keeps calling it. Thread pool exhausts. Everything degrades simultaneously. The cascade nobody saw coming — because the pattern that stops it was never added.
Then there's Consistent Hashing — the reason Cassandra and DynamoDB don't collapse when you add a node. Without it, a topology change remaps your entire cache keyspace. Every miss hits the database at once. One scaling event becomes an outage.
Most teams discover this during their first major traffic event. Not before.
Event-Driven Architecture sounds like a nice architectural principle. It isn't. It's the pattern that stops one service's failure from becoming every service's problem. Teams that skip it build systems where everything is simultaneously everyone else's dependency. It fails slowly, then all at once.
Service Discovery is the concept nobody thinks about until they have 50 services and a deployment breaks routing for three of them simultaneously.
And Observability — Logs, Metrics, Traces — is always the last thing added and the first thing needed when something goes wrong.
Here's the uncomfortable truth:
Every single one of these 16 concepts exists because a real system failed without it. Not a demo. Not a staging environment. Production. With users. With data. With consequences.
You can learn these concepts from a visual.
Or you can learn them from an incident.
The visual is faster.
For a deeper dive → https://t.co/JHAfUGjWoz
I've reviewed hundreds of system design sessions. The same 9 mistakes appear every time. The scariest part? Most engineers don't know they're making them.
The first mistake happens before the marker cap is off. Someone opens a whiteboard and starts drawing microservices. No requirements, no constraints, no scope. The architecture is already wrong.
NFRs — scalability, security, performance — get treated as optional extras. They're not features. They're the constraints that determine whether your system survives production. Skip them upfront, pay for them in incidents.
Over-engineering is the mistake senior engineers make most. A distributed system designed for 10 million users serving 10 thousand. Complexity isn't sophistication. It's debt you haven't paid yet.
"There are no trade-offs. This design is optimal." That answer fails every serious design review. Every choice has a cost. If you can't name it, you don't own the decision.
Single point of failure dressed up as simplicity. One database, one server, one region. One failure from everything going down simultaneously.
Vague hand-waving — "we'll just use Kafka," "we'll deploy to the cloud" — without justification isn't a design. Ambiguity on the whiteboard becomes the incident nobody can diagnose.
And the mistake you only regret at 2am: shipping without observability. No logging, no tracing, no alerting. A black box running in production you can't see inside when it starts failing. And it will.
These aren't made by bad engineers. They're made by good engineers moving too fast without a checklist.
The best system designers aren't the smartest in the room. They're the ones who slow down before the first box gets drawn.