Transformers can be made sparse across their depth. When trained isoFLOP, we can match or exceed the performance of vanilla models, while saving inference FLOPs
https://t.co/jWl1wuHEko
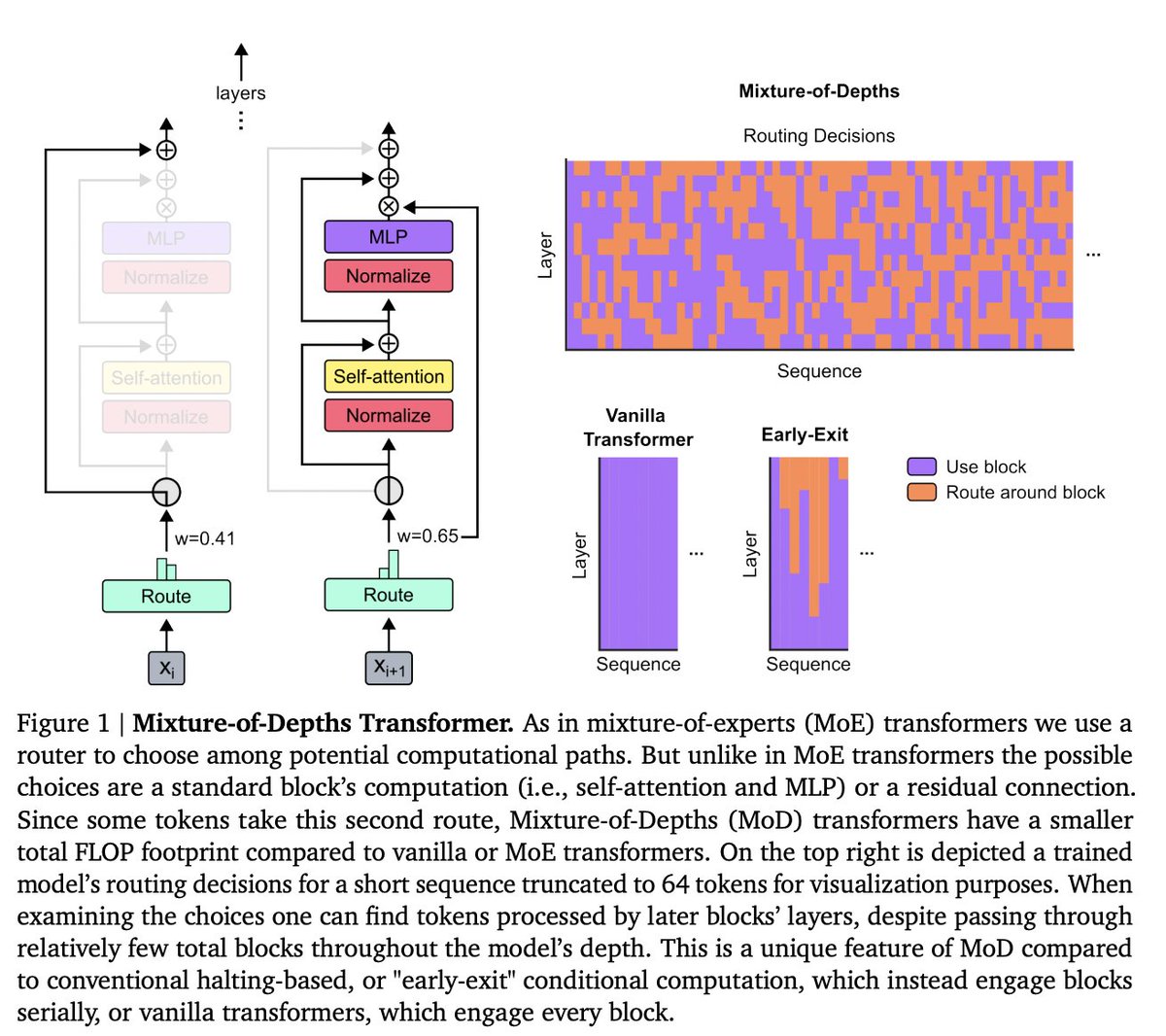
reading the "mixture of depths" paper, which comes up with a novel way to conditionally apply compute depth-wise in a decoder
basically they use standard MoE-style expert-choice routing but they use it to choose which tokens get to go through every block in the decoder
Gemini and I also got a chance to watch the @OpenAI live announcement of gpt4o, using Project Astra! Congrats to the OpenAI team, super impressive work!
@ivanleomk The FLOPs in the feedforward are not the same (MoD uses fewer), but you need to make the total training FLOPs (FLOPs-per-ffw * training steps) the same to see the effect. So, MoD trains for more steps
@ivanleomk The top-k isn't causal because whether a token is part of the top-k depends on the router weights of tokens that are after it in the sequence. During sampling you don't have these router weights since you need to produce tokens in a causal sequence
@ivanleomk Training is not faster (it takes the same amount of FLOPs, and ~wall clock). Rather, the resultant model is ~50% faster to step during sampling (post-training) because it requires ~50% of the FLOPs in the feedforward
Transformers can be made sparse across their depth. When trained isoFLOP, we can match or exceed the performance of vanilla models, while saving inference FLOPs
https://t.co/jWl1wuHEko
@iamgrigorev Apologies for not being explicit: when I say match training FLOPs, I mean *exactly* matching. So you need to calculate the FLOPs per ffw of each model and tune the training steps accordingly
@iamgrigorev Thanks for the update! FYI if you don't make up for the lost FLOPs in some way (e.g. train isoFLOP) then performance will be worse. As you can see in the paper, wall clock/FLOPs are the same during training, not total tokens. The wins then come with inference speed
@iamgrigorev@felix_red_panda@haeggee I agree, figuring out the best routing pattern per layer is an interesting thing to explore. No doubt there's something better than choosing some constant throughout the depth
I have implemented Mixture-of-Depths and it shows significant memory reduction during training and 10% speed increase. I will verify if it achieves the same quality with 12.5% active tokens.
https://t.co/wbOByZZz4o
thanks @haeggee for initial code
@felix_red_panda@iamgrigorev@haeggee All the layers will always be active, the speed increases come from having to process a fraction of the sequence instead of the full thing. That fraction is constant as you change batch size
@EsotericCofe and if you haven't yet, don't forget to set the training FLOP budgets appropriately (rather than training step budgets) so that the LR schedules are correct and you don't undertrain the model
@EsotericCofe Nice work! If you plot by flops instead of steps you'll get a better perspective on whether the implementation is working well (ideally the MoD transformer will have a better loss than vanilla throughout training, plotted by flops)