🧵 NVIDIA Dynamo v0.9.0 is live and it's probably our biggest infrastructure upgrade yet.
Highlights this time include
✅ Sneak preview of FlashIndexer
✅ Expanded multi-modal support
✅ Removed NATS & ETCD
And bonus. . . @meituan (Chinese Doordash + LLM builders) recently dropped an OSS inference engine built on @sgl_project + Dynamo. 👇
@MattressFirm I had a bad experience at @BigTex. The sales manger (Michael) was very rude, that I cannot sit and try on the bed since I had kids. While I see so many other people are sitting on it with kids. The reason he said is anyway I am NOT going to buy it. I was seriously considering purple mattress. Is this how sales works these days, that sales person judge someone before even talking to the buyer?
We're rolling out new features and improvements that developers have been asking for:
1. Our new model GPT-4 Turbo supports 128K context and has fresher knowledge than GPT-4. Its input and output tokens are respectively 3× and 2× less expensive than GPT-4. It’s available now to all developers in preview.
2. Assistants API and new tools (Retrieval, Code Interpreter) will help developers build world-class AI assistants within their own apps.
3. The platform is becoming multimodal. GPT-4 Turbo with Vision, DALL·E 3, and text-to-speech are all now available to developers.
Oh… and we’re doubling GPT-4 rate limits. https://t.co/BMnsBAHorI
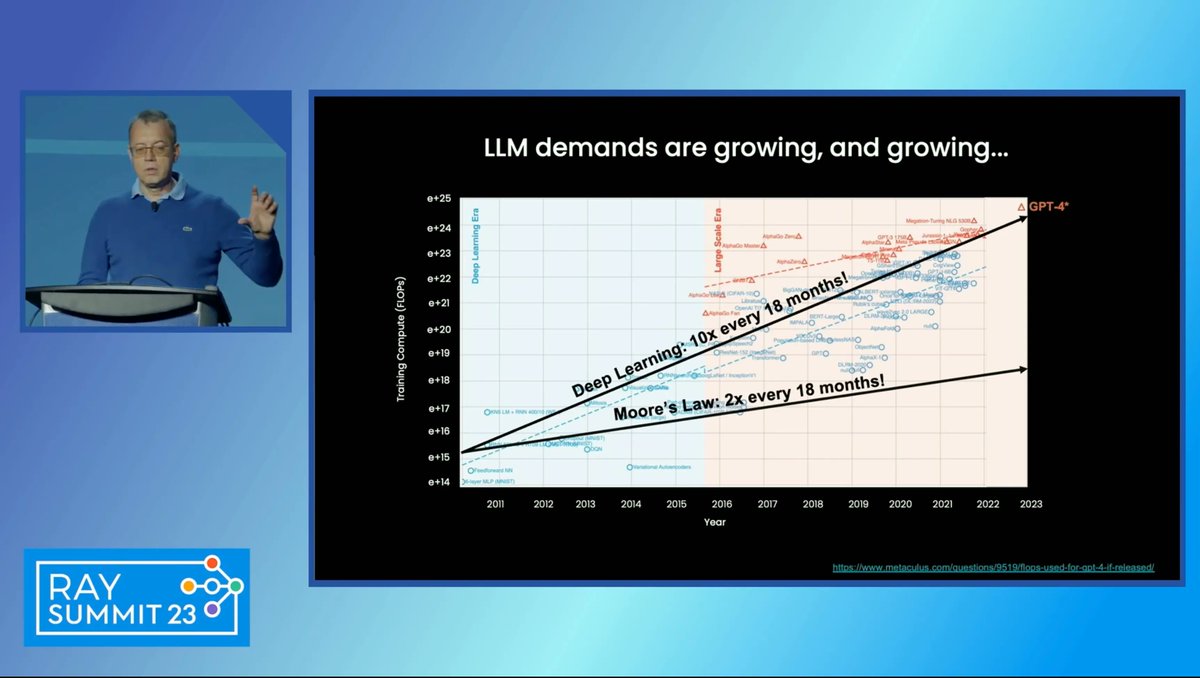
#LLM models are growing 10X compared to the Hardware improvements of only 2x in the last decade. This begs for more innovation in AI accelerators specific to AI workloads like #DGXGH200, and also distributing the AI workloads.
Good chat with Greg Brockman (openai) & Robert Nishihara (anyscale) discussing on how openai infra evolved overtime and how #ray helps them. https://t.co/1MaMbdD1fF https://t.co/1MaMbdD1fF
The way that Jensen Huang runs Nvidia is wild:
40 direct reports, no 1:1s
- Believes that the flattest org is the most empowering one, and that starts with the top layer
- Does not conduct 1:1s - everything happens in a group setting
- Does not give career advice - "None of my management team is coming to me for career advice - they already made it, they're doing great"
No status reports, instead he "stochastically samples the system"
- Doesn't use status updates because he believes they are too refined by the time they get to him. They are not ground truth anymore.
- Instead, anyone in the company can email him their "top five things" with whatever is top of mind, and he will read it
- Estimates he reads 100 of these everyone morning
Everyone has all the context, all the time
- No meetings with just VPs or just Directors - anyone can join and contribute
- "If you have a strategic direction, why tell just one person?"
- "If there is something I don't like, I just say it publicly"
- "I do a lot of reasoning out loud"
No formal planning cycles
- No 5 year plan, no 1 year plan
- Always re-evaluating based on changing business and market conditions (helpful when AI is developing at the pace that it is)
This org is optimized for (1) attracting amazing people, (2) keeping the team as small as it can be, and (3) allowing information to travel as quickly as possible
Narrowly missed to fly from Terminal-2 due to technical difficulties. Nevertheless interesting to see #nvidia chips & toolsets are helping this new terminal. https://t.co/GCKq5h8pHS
Nvidia announced that it’ll support a new Hugging Face service, called Training Cluster as a Service, to simplify the creation of new and custom generative AI models for the enterprise. https://t.co/MJTurB9nXu #aiinfra#nvidia
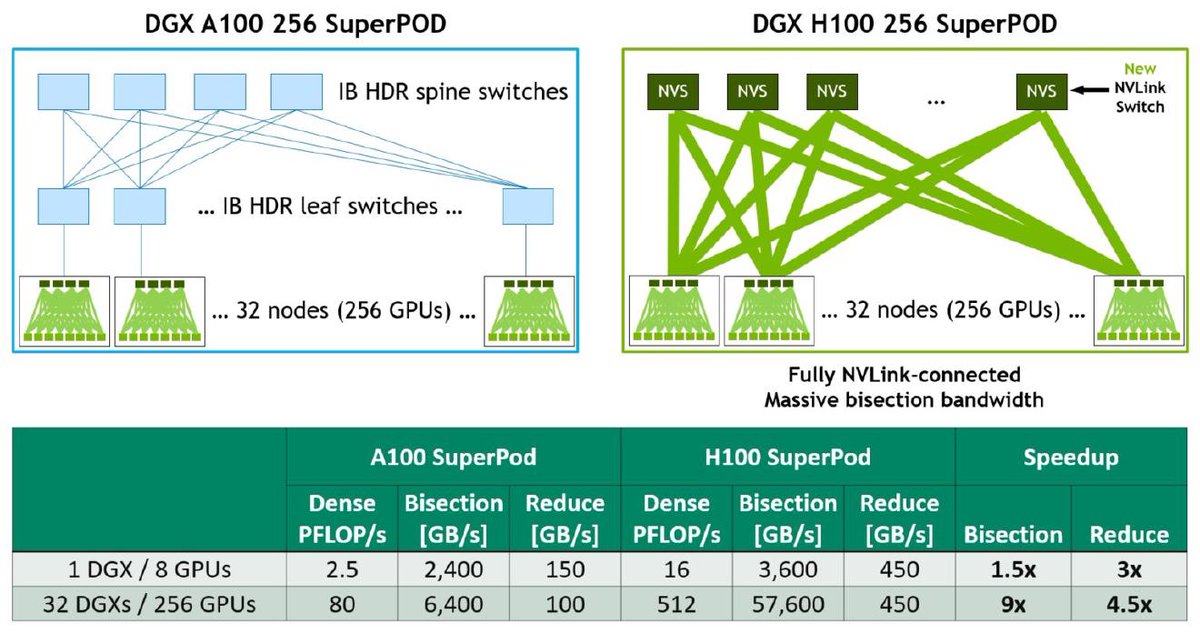
The GH200 will have the same GPU as the H100, currently Nvidia’s most powerful and popular AI offering, but triple the memory capacity. The company said systems running on GH200 will start in the second quarter of 2024. https://t.co/osWhihAu1P #ai#nvidia
We do not know in what direction the models will grow. All we know is that the process of growth and exploration will be nourished by ever more data and more compute. And that will require a new wave of data centers, ready to meet the challenge. https://t.co/idInAdFIh3 #aiinfra
The unusual use of Nvidia H100, the sought-after chip that powers AI computing as collateral, highlights the value of such hardware in the capital-intensive AI arms race. https://t.co/NvkRcWKxJW #nvidia
As these models get larger, it could even mean multiple data centers working in tandem. “The latency requirements are more smaller than we might think,” he said. “So I don't think that it's out of the question to be able to couple multiple data centers.” https://t.co/0T064iXgiC