That awkward moment when you’re at a Spark talk and the main takeaway is that Scalding is much better at doing this, just read the Scalding source code and implement it. 😅
@rwhitcomb They won’t. But we should just add a serialization test. Using JobTest with runHadoop will find serialization errors, but people don’t always do that.
@vitalygordon The in memory mode has no dependencies but scala concurrent. You choose to run a job in scalding memory mode OR cascading (Hadoop or memory) OR spark. You can’t (currently) change the mode as the job proceeds.
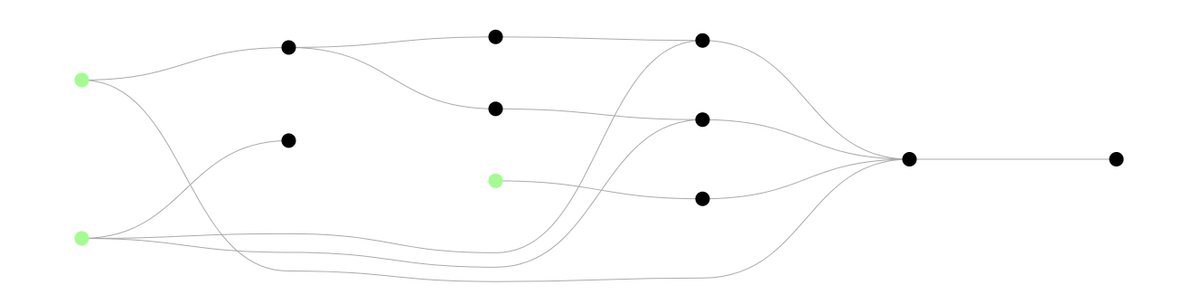
Scalding 0.18 is nearly here, the biggest release in years. This features a new optimizer backend which allows much more powerful job simplifications. It also enables a scala-only in-memory backend. The long awaited Spark backend will be in alpha: https://t.co/LamBPQdQiN
The one and only @posco will speak at @sfscala on March 29. We need a big venue! Also, great FP+ML questions are always in order. We also hope to hear about @bazelbuild for #Scala. Perhaps folks might be able to ask questions on @scalding of Algebird too!
https://t.co/sa1QpDfwgk