👉I've moved to https://t.co/kgHFY0os5x
(Sorry for the noise. This silly bird site won't let me just edit my original announcement with an updated link, so here we are.)
@GanescuTheodor @mlejva@HashiCorp At the end of the day optimal scheduling is 2 raft commits and 1 additional network rpc for placement. <200ms for "job run -> running" seems doable by tuning batching. <100ms is probably possible.
@GanescuTheodor @mlejva@HashiCorp And finally: I don't really check Twitter these days (but luckily coworkers do!) Feel free to hmu elsewhere too:
https://t.co/kgHFY0os5x
https://t.co/bo4V2SjcGF
👉I've moved to https://t.co/kgHFY0os5x
(Sorry for the noise. This silly bird site won't let me just edit my original announcement with an updated link, so here we are.)
Oh and https://t.co/OTxX25q4n7 is a fantastic resource for learning about Mastodon.
The short version is that it's Twitter but hosted like email: you can connect with anybody even though there are lots of distinct hosts.
@jreynoldsdev@resmo79@HashiCorp@traefik One common approach is to have a set of nodes that receive traffic from the Internet. Configure node_class=ingress or some other metadata on the Nomad node.
Then run traefik as a system job with a constraint on those nodes.
Very manual, but HA and scalable.
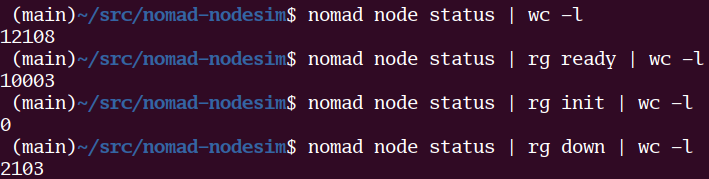
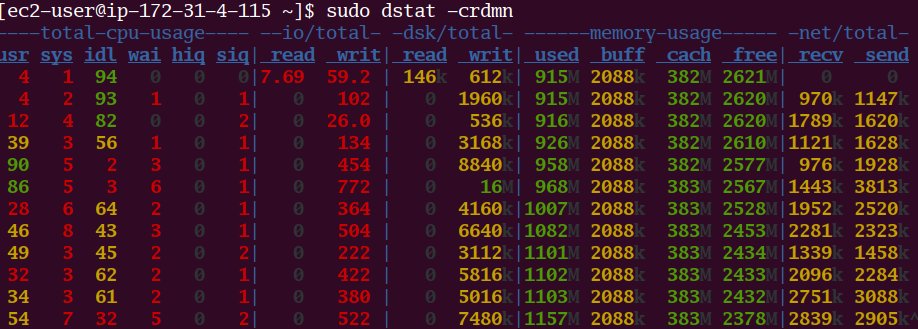
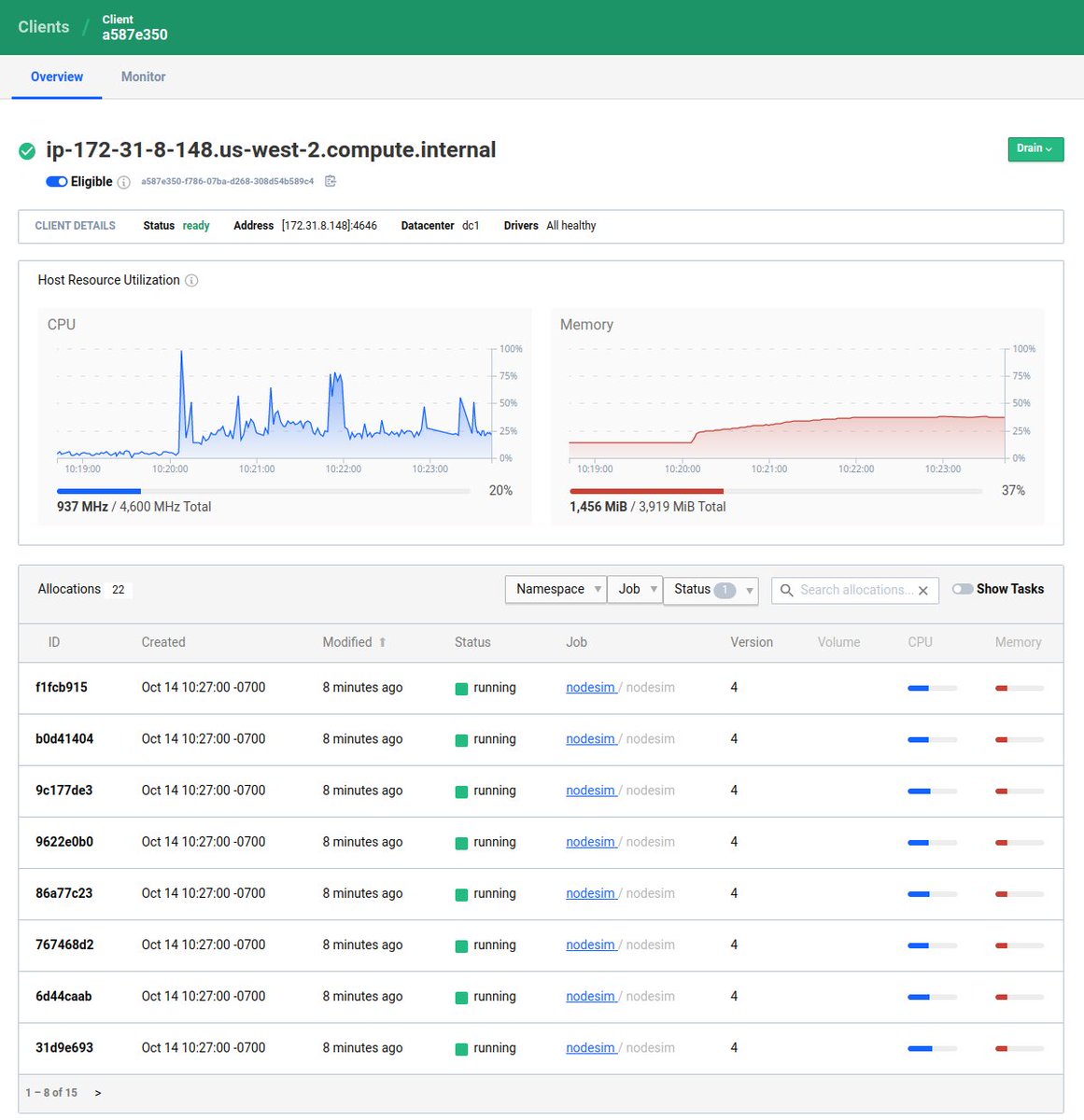
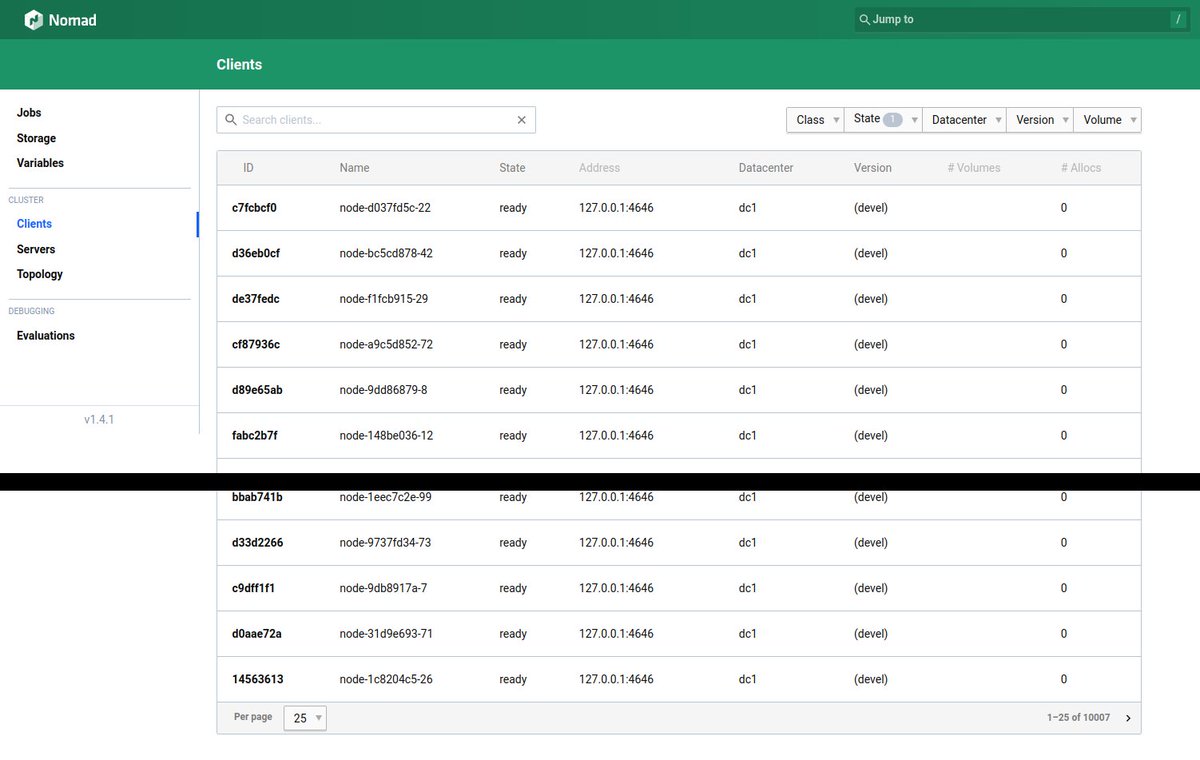
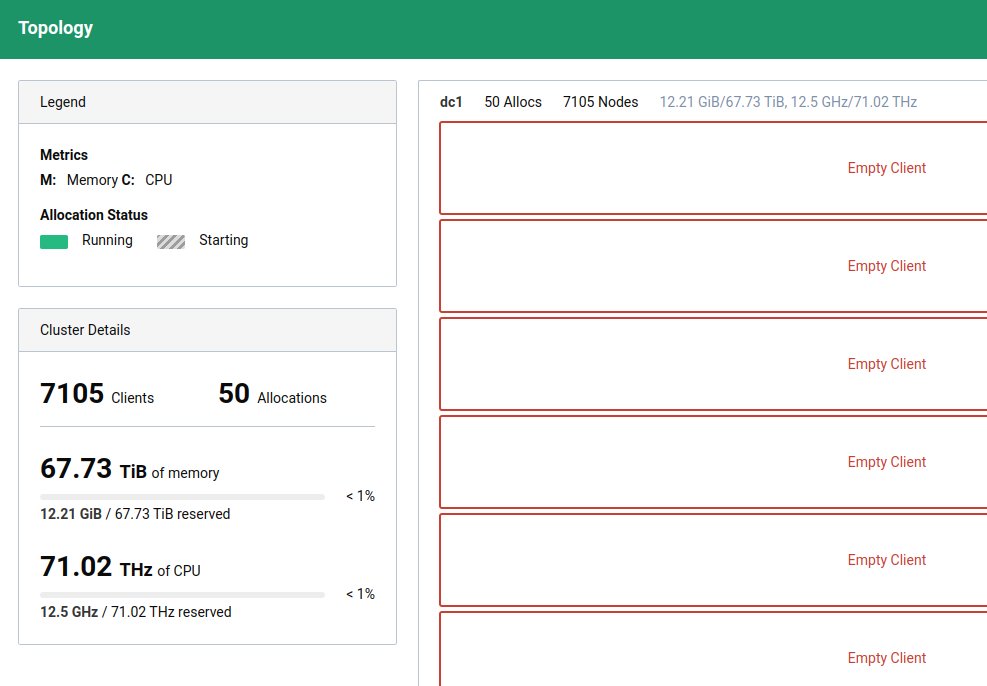
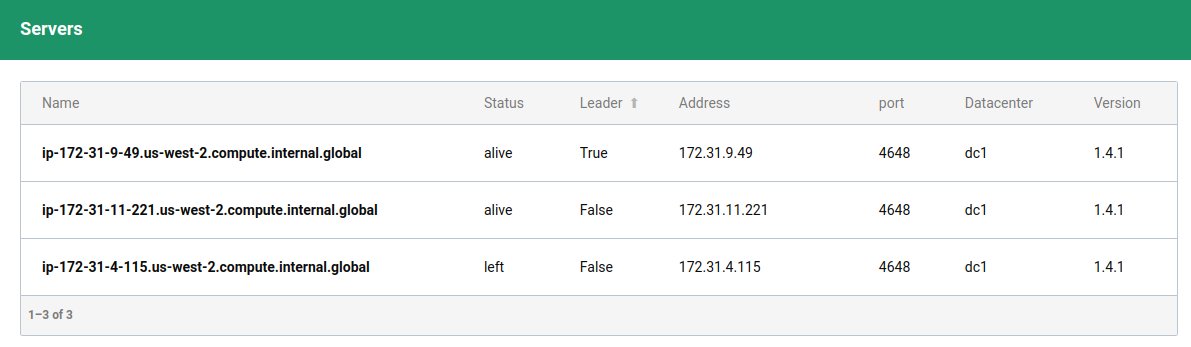
Watching @HashiCorp Nomad manage 10k servers is... pretty boring actually?
The 3 Nomad servers were t2.mediums as were 7 of the client nodes. The other 10k clients are the real Nomad client node code but packed 100 per container across 100 containers on the 7 real nodes.
@jreynoldsdev@resmo79@HashiCorp Nomad lacks builtin ingress. @traefik is probably the best option today as it supports Nomad and Consul for service discovery and routing information. https://t.co/jqRbhfbZxs
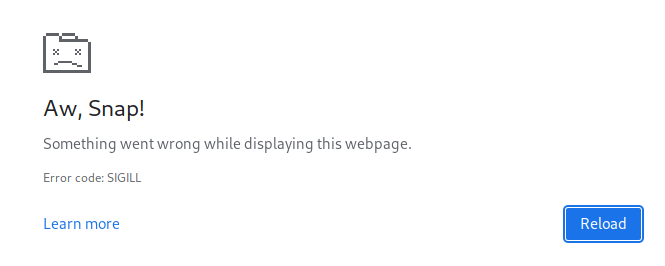
Word of warning if you try this at home: @googlechrome does *not* like trying to draw 10k boxes. 7k was fine, but somewhere between 7k-10k client nodes the topoviz page broke Chrome in the Nomad UI.
The point of the exercise was to test things like Nomad's heartbeat scaling and failover. Sure enough after I kill -9'd the leader server, another was elected leader, and no client nodes were lost!
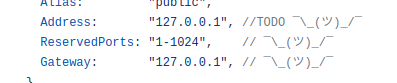
@lhaig Clients are easy to virtualize because they don't listen on any ports: they only make outgoing connections to Servers. (The HTTP API is in the Agent code which my simulation just skips entirely.)
Still, "agentless" Servers where you track their ports manually should be possible!
@lhaig Oooh, I'd love to see the results of that. I can't think of where the limits on federation might be, but I definitely only think of it in terms of "10s of regions" ... no clue where 100s or 1,000s of regions would cause issues. 🤔