SWE-Bench style grading has been the standard for years now - you ask the agent to solve an issue and then run its code on a pre-constructed unit test.
The problem is that passing a unit test is only one part of writing production-ready code. You also want to evaluate agents on a number of other axes, including scope, coding style, and unintended side effects.
The result is our new benchmark FrontierCode - which has ~80% fewer false positives and for which the best model (Opus 4.8) only scores 13%!
"Where others grade like a CI, FrontierCode grades like a tech lead."
Introducing FrontierCode: a coding eval that raises the bar for difficulty & quality. Each task took 40+ hrs of work by leading open-source maintainers.
Models write sloppy code that works but isn’t maintainable. Our eval is first to measure: would you actually merge this code?
In 1958 Ian Donald published what is now the foundational paper on medical ultrasound for obstetrics. He was so widely ridiculed by his colleagues at the time that they nicknamed him Mad Donald [1], and one said ultrasound would be useful only to "a gynecologist who was blind and had lost the use of both hands" [2]. Another noted that he'd invented a £10,000 device to undertake a task that could be accomplished with a £0.02 rubber glove. [3]
Last week, my wife and I welcomed our first child into the world. She had a rare pregnancy complication that until recently would have meant only a 28% intact survival rate for our newborn. But in 2013 US guidance was updated to add regular preventative screening for her condition at the 20-week ultrasound, and with early detection the survival rate is ~99%. (In the UK, preventative screening is still not recommended, for reasons like "it is not known how accurate screening tests are" [4].)
The entire history of radiology is people expressing skepticism about the work done by innovators. I for one am grateful for folks like @DavidSHolz building new classes of devices that can help us see things in new ways, and I'll be rooting for their success. Hand in hand with my wife and our healthy baby boy.
Congratulations to @axliu42 on receiving the ACM Doctoral Dissertation Award for his work on learning-theoretic foundations for understanding quantum systems.
Allen joined Cognition's research team this week while continuing as a professor at NYU. We’re honored and excited to work with him.
https://t.co/W1u9dAefnF
My take 24 hours after Fable 5:
Your organization will likely not scale with the exponential curve of AI.
I'l just come out to say: This should be a wakeup call for engineering teams.
Set up your cloud software factories. Now.
Models can now fix impossible bugs, UI-test the hardest flows, writing extremely good code, etc. I have't opened Datadog manually as far as I can remember.
AI should be the first-line defense for bugs and feedback. Humans should only look at PRs after an AI has already reviewed it. AI should generate screen recordings of any PR before a human eye even reaches it. The agent should just prompt itself most of the time.
Ex. (pictured) our ui feedback channel manages itself, creates tickets, assigns itself automatically
You might also be worried about cost. Anthropic, OpenAI, and other labs will likely continue to put out bigger and more expensive models. But, we will also continue to get more capable small models. Not everything will need the smartest models. It's about having the organizational harness in place to continue taking advantage of this rising tide.
Moreover, if you use Devin, we've already optimized our harness a bit, and Fable is actually only ~40% more expensive in practice (vs the 2x people assume). I'm honestly pleasantly surprised - it might be higher ROI than you think.
Anyway, if you take anything away, engineers shouldn't be manually picking up tickets, humans shouldn't be digging into logs themselves, rethink what you do with your time that shouldn't just be an AI. We need to rethink what humans spend their time going.
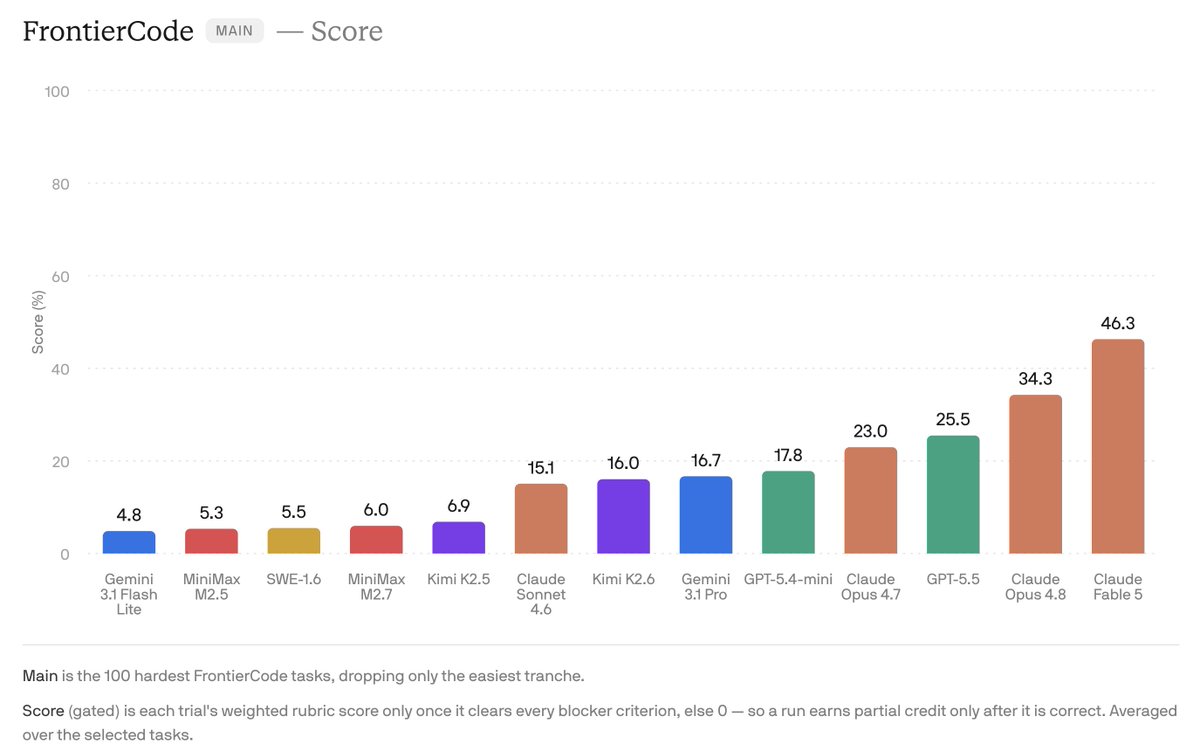
A new top scorer just one day after our benchmark released! Especially strong on the hardest tasks: 13.4% -> 29.3% on FrontierCode Diamond compared to Opus 4.8.
Claude Fable 5 is now available in Devin.
Fable 5 earns the #1 spot on FrontierCode, our benchmark for real-world engineering tasks that grades mergeability and quality:
SWE-Bench style grading has been the standard for years now - you ask the agent to solve an issue and then run its code on a pre-constructed unit test.
The problem is that passing a unit test is only one part of writing production-ready code. You also want to evaluate agents on a number of other axes, including scope, coding style, and unintended side effects.
The result is our new benchmark FrontierCode - which has ~80% fewer false positives and for which the best model (Opus 4.8) only scores 13%!
"Where others grade like a CI, FrontierCode grades like a tech lead."
Introducing FrontierCode: a coding eval that raises the bar for difficulty & quality. Each task took 40+ hrs of work by leading open-source maintainers.
Models write sloppy code that works but isn’t maintainable. Our eval is first to measure: would you actually merge this code?
Agree - the thing is that for agent work folks often don't know how to measure the productivity they're getting even within an order of magnitude! So there will be a point of diminishing returns on measurement eventually but we're not yet too close to the 2-5% micromanaging territory.
Measuring someone's productivity by their token usage is a horrible idea. Giving everyone the same fixed token budget isn't much better. So what's the right way to roll out AI across your org?
We built a system to measure how many productive engineering hours every Devin task is worth, validated against a dataset of real engineers’ times estimates. The goal is to answer the fundamental question that companies are grappling with: how much real value are you getting from each of your agent sessions?
On top of that, we're giving an AI productivity guarantee! Now if Devin delivers less engineering value than you're paying for, we fund your usage until it does.
The whole industry needs to move from measuring activity to measuring output. We hope to see more AI companies taking this approach.
AI should earn its keep. Introducing the AI Productivity Guarantee.
If Devin delivers less engineering value than you’re paying for, Cognition will fund your usage until it does, up to $10 million.
It’s time for the AI industry to stop maximizing tokens and start maximizing productive output.
Looks like @DevinAI the best research agent out there?
Nikhil from Devin is moving the frontier forward by reducing our the number of qubits our circuit requires.
At @harvey, the engineering team integrated Spectre — their internal background agent — into Devin Desktop.
Now Spectre's organizational context can live on every engineer's laptop and flow across their favorite agents.
Excited to partner with @Carahsoft! An important step for more of the public sector to have access to the same tools and technology that the private sector is adopting en masse today.
We have partnered with @Cognition to bring their AI coding platform, Devin, to the Public Sector. Together, we’re helping organizations modernize software development and accelerate secure AI adoption. Learn more: https://t.co/f2AQbyDnqh
Standalone IDEs have about 6 months left to live. An interface for manually editing and refactoring doesn’t need to exist if you're not manually editing and refactoring anymore.
So what's the right interface for a dev to be working in for 8h / day? Some parts are obvious: you want to be able to spin up agents (either local or cloud agents) and to have a clean interface to keep up with all of your parallel running agents. Then you want to be able to get into the weeds whenever needed for last-mile fixes and review.
But as software engineering continues to evolve we will see more and more of the lifecycle get reinvented. How do you build a single surface that allows you to plan, spec, prototype, debug, review, QA?
Bringing Devin and Windsurf together has been our vision ever since the acquisition. Devin Desktop is our first shot at what this looks like. Excited to make this a reality today!
Introducing Devin Desktop: the next generation of Windsurf
Manage fleets of local and cloud agents from one surface
Support for any ACP-compatible agent
With a full IDE for when you need to jump into the code
Word on the street is that everyone is going to be switching back to Opus when the new model drops.
This is exactly why I use an independent agent lab like Devin for my main software factory.
They're going to deal with that headache for me.
There's no way you can move fast and reliably if you're constantly switching between Claude Code, Codex and insert-other-shiny-object-here.




















![russelljkaplan's tweet photo. In 1958 Ian Donald published what is now the foundational paper on medical ultrasound for obstetrics. He was so widely ridiculed by his colleagues at the time that they nicknamed him Mad Donald [1], and one said ultrasound would be useful only to "a gynecologist who was blind and had lost the use of both hands" [2]. Another noted that he'd invented a £10,000 device to undertake a task that could be accomplished with a £0.02 rubber glove. [3]
Last week, my wife and I welcomed our first child into the world. She had a rare pregnancy complication that until recently would have meant only a 28% intact survival rate for our newborn. But in 2013 US guidance was updated to add regular preventative screening for her condition at the 20-week ultrasound, and with early detection the survival rate is ~99%. (In the UK, preventative screening is still not recommended, for reasons like "it is not known how accurate screening tests are" [4].)
The entire history of radiology is people expressing skepticism about the work done by innovators. I for one am grateful for folks like @DavidSHolz building new classes of devices that can help us see things in new ways, and I'll be rooting for their success. Hand in hand with my wife and our healthy baby boy.](https://pbs.twimg.com/media/HLR5AeHbgAAEwRZ.jpg)