I'm a seasoned engineering graduate with a deep passionate interest for AI and IT infrastructure. I'm the maintainer of afm (maclocal-api) and Vesta AI Explorer
5 inference backend in 1 single app. Access to all models and methods. For MacOS. Control Qwen Thinking and chose LLM or VLM.
https://t.co/AOSbxCh5PT
https://t.co/Z5NnsZPW08
#llm#apple#LocalAI#Qwen3
@icanvardar The trend is modular monolith now. Microservices introduce inter-service API latency, operational complexity, increased Cloud costs and wasted CPU cycles due to overhread burden of distributed systems.
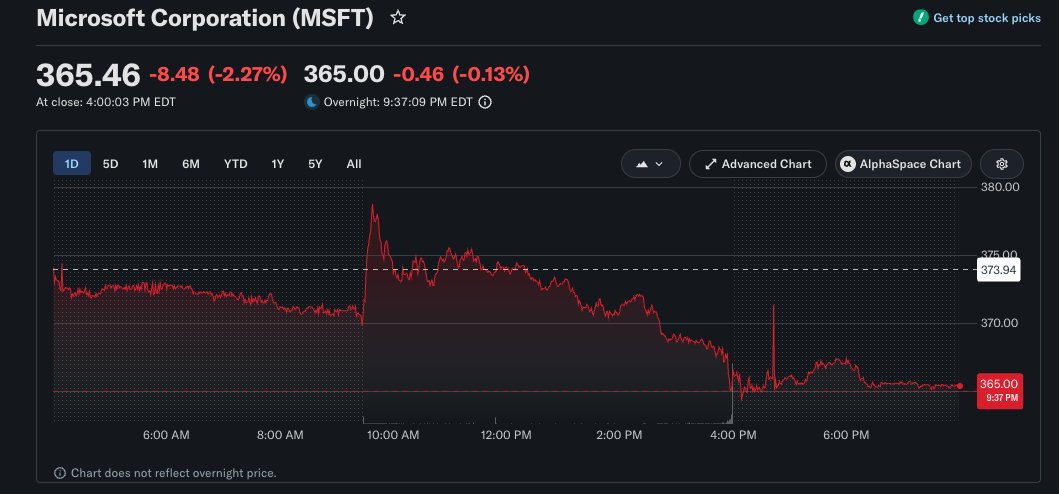
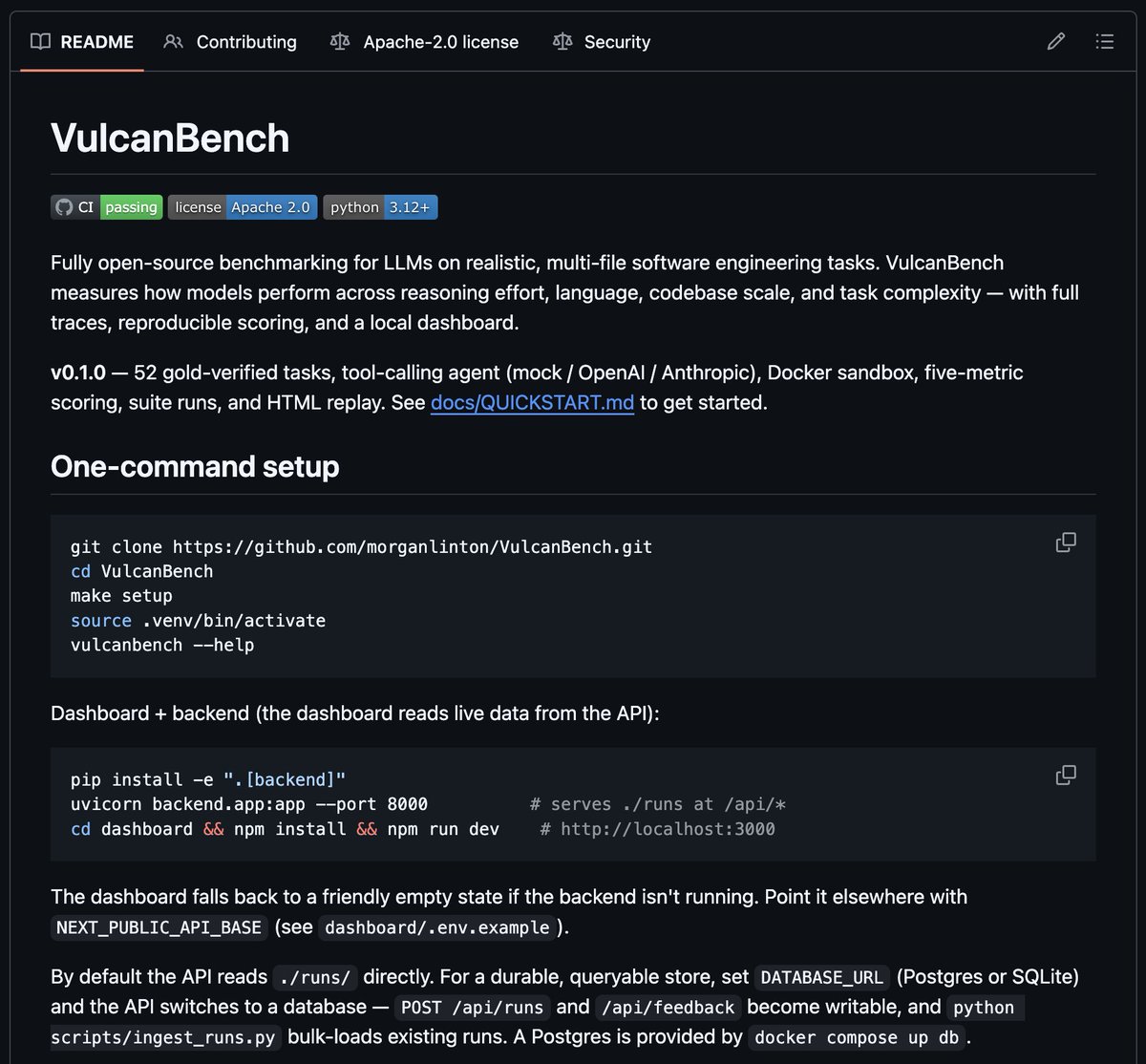
Okay, it's official, VulcanBench v0.1 is here.
Free and open source llm benchmarking tool, pre-loaded with 52 tests so you can really go deep.
The goal is simple: completely transparent benchmarking, every detail from the code that runs the tests, to the tests themselves, is available, for free, for everyone to see.
Please test, test, and test some more, and give feedback, or even better, submit PRs to make it better.
Live long and Benchmark 🖖
Be honest:
How many of you local AI enthusiasts actually look at model output quality vs pure tokens/sec?
I'll go first.
When benchmarking, I rarely look the at the output. But I decided to put more emphasis on this. In the end, that's what really matters!