🚀🚀Now combining #FreeU with #SDXL, #ControlNet, #LCM, #ScaleCrafter, #Dreambooth, and #Animatediff, you can enhance the generation quality for free!
-Project Page: https://t.co/z5duXpY4VF
-Code: https://t.co/BwVLQ1SMIZ
-Video: https://t.co/W5XKxoEE1H
FreeU: Free Lunch in Diffusion U-Net
paper page: https://t.co/fpRjbk0CED
we uncover the untapped potential of diffusion U-Net, which serves as a "free lunch" that substantially improves the generation quality on the fly. We initially investigate the key contributions of the U-Net architecture to the denoising process and identify that its main backbone primarily contributes to denoising, whereas its skip connections mainly introduce high-frequency features into the decoder module, causing the network to overlook the backbone semantics. Capitalizing on this discovery, we propose a simple yet effective method-termed "FreeU" - that enhances generation quality without additional training or finetuning. Our key insight is to strategically re-weight the contributions sourced from the U-Net's skip connections and backbone feature maps, to leverage the strengths of both components of the U-Net architecture. Promising results on image and video generation tasks demonstrate that our FreeU can be readily integrated to existing diffusion models, e.g., Stable Diffusion, DreamBooth, ModelScope, Rerender and ReVersion, to improve the generation quality with only a few lines of code.
One static model does not fit all😭
We just dropped our latest work: Functional Neural Memory. Instead of static models, we generate custom "parameters" for every single input.
✅Prompt your model anytime
✅Instant personalization
✅Better instruction following
✅Flexible & dynamic memory (w/o memory bank✌️)
(🧵1/6)
🚀The ultimate roadmap for Human-Centric AIGC is here!
Our new survey provides a structured and task-grounded lens on Diffusion Models for human-centric content generation. Whether you are a beginner or an expert, this is your one-stop-shop!
📄 Paper: https://t.co/T1CPP9MODS
🔥Ultra-Long Video World Model up to 5min🔥
✨ We introduce #LongVie2, an end-to-end autoregressive video world model that supports continuous video generation lasting up to 5min with:
🕹️ Strong Controllability
📷 Long-term Visual Fidelity
🔒 Temporal Consistency
- Project: https://t.co/Z5vxsvpXsy
- Code: https://t.co/wcSfQERhXA
- Paper: https://t.co/H9Ir5HQ6IY . Thanks to @_akhaliq !
AI video generators fall apart after 10 seconds.
LongVie 2 generates coherent videos for 5 MINUTES straight → with full controllability & zero quality degradation 🎬
3-stage training solves what Sora couldn’t:
•Multi-modal control
•Degradation-aware learning
•History-context alignment
World models just got real
#AIVideo #GenerativeAI
The "Controllable Video" problem might have just been solved. 🚀
LongVie 2 is a new end-to-end autoregressive framework that masters three things: controllability, long-term visual quality, and temporal consistency.
What makes it special: ✅ 5-Minute Continuous Video: Not just a loop, but coherent, evolving generation. ✅ Dense/Sparse Control: Precise world-level supervision for better steering. ✅ State-of-the-Art Benchmarks: Outperforms current models in visual fidelity and "long-range" coherence.
The era of "one-minute-plus" AI video that actually stays consistent is finally here. 🔗 https://t.co/QMNRHn0mUF
LongVie 2, an end-to-end autoregressive video world model with:
- Strong Controllability
- Long-term Visual Fidelity
- Temporal Consistency https://t.co/9Q9gJIkMDr
Heading to #NeurIPS2025? Join us for the #NextVid Workshop on Dec 6 in San Diego!
We’re exploring the frontier of Video Generation with an outstanding lineup of keynote speakers:
Check the thread for today's reveals! 👇
(1/7) We are delighted to introduce our latest work, PosterCopilot. Given a set of unordered elements, it automatically plans the layout, supports editing of any element, and ultimately produces a professional-grade poster.
After a year of team work, we're thrilled to introduce Depth Anything 3 (DA3)! 🚀
Aiming for human-like spatial perception, DA3 extends monocular depth estimation to any-view scenarios, including single images, multi-view images, and video.
In pursuit of minimal modeling, DA3 reveals two key insights:
💎 A plain transformer (e.g., vanilla DINO) is enough. No specialized architecture.
✨ A single depth-ray representation is enough. No complex 3D tasks.
Three series of models have been released: the main DA3 series, a monocular metric estimation series, and a monocular depth estimation series.
The core team members, aside from me: @HaotongLin, Sili Chen, Jun Hao Liew, @donydchen.
👇(1/n)
#DepthAnything3
🏆 Congrats to #NTUsg Prof Ng Geok Ing on the 🇸🇬 President’s Technology Award 2025. A pioneer in Gallium Nitride (#GaN) – found in fast chargers, EVs, satellites & defence – he built 🇸🇬’s global standing in this field and led the creation of the national GaN centre. 👏 We also congratulate Young Scientist Award recipient Assoc Prof Liu Ziwei, who was recognised for advancing #AI in 3D & 4D vision, as well as digital twins, with impact on healthcare, education and other sectors. #PSTA @NTU_EEE@NTU_ccds
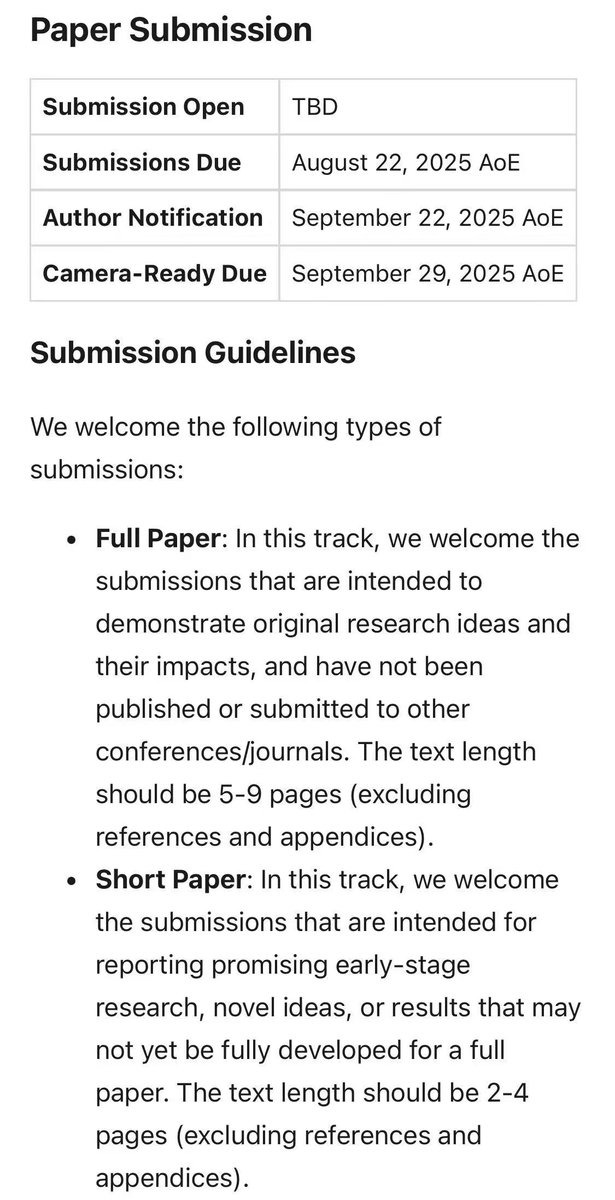
🎯【Call for Papers: NeurIPS 2025 Workshop NextVid: What Makes a Good Video: Next Practices in Video Generation and Evaluation】
⏰ Key dates:
* Submission deadline: Aug 22, 2025 (AOE)
📌 Details:
* Website: https://t.co/fNemjz03VK
🔥1-min Interactive Video Generation with Multimodal Control🔥
Towards *long-context world model*, #LongVie is an end-to-end autoregressive framework for controllable ultra-long video generation
- Page: https://t.co/kKNHhjEmrl
- Paper: https://t.co/M5wGkpi0Ve . Thanks @_akhaliq
NVIDIA researchers introduce LongVie, a new framework for multimodal-guided controllable ultra-long video generation.
It tackles key issues like temporal inconsistency and visual degradation.
LongVie uses unified noise, global control normalization, and multimodal guidance to ensure consistency & quality in videos up to one minute.
Explore the research: https://t.co/e8AU52lbt7
See demo: https://t.co/b6ybl11z3v