Security Stack Sheet #118
Word of the Week
“Ransomcloud”
Word of the Week special
“Why Is the Majority of Our MFA So Phishable?”
“Why Zero-Days Are Essential to Security”
#security#cybersecurity#cyberresilience#zeroday#ransomware https://t.co/5PuySIXA9g
Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier.
First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks.
- It’s a 35B active parameter MoE with a 256K context window. Independent human raters on Surge prefer it for overall quality in blind side-by-sides versus Sonnet 4.6, and it’s achieved 97% on AIME 2025, the key measure of its general-purpose reasoning abilities.
- It's at 53% on SWE Bench Pro, placing it right alongside Opus 4.6 on one of the toughest coding benchmarks.
- And since we co-designed our models with our own silicon, MAI-Thinking-1 is optimized on our MAIA 200 chip. Benchmarking head-to-head against the GB200, we see 30% better performance per dollar as well as a 1.4x performance-per-watt gain when running our MAI models on the MAIA 200 end-to-end.
Next is MAI-Image-2.5 and its Flash variant. Two super strong models now at #2 on the leaderboards, surpassing the score of Nano Banana 2 on image editing.
Last for now is MAI-Code-1-Flash, our new inference efficient coding model, especially tuned for VS Code and GitHub Copilot CLI.
- Code-1-Flash achieves 51% on SWE Bench Pro, despite having just 5B parameters, putting it closer to Haiku in size but cheaper in cost.
All of this is the foundation for Microsoft Frontier Tuning. It lets you customize our models to create custom, company-specific agents that only you control. You can make our model, your model. Your data. Your agents. Your moat.
Early adopters are already seeing a difference. When we tuned our models for McKinsey’s tasks, MAI delivered the highest win rate, outperforming GPT-5.5 on quality, while being 10x lower on cost.
Also really excited to be collaborating with the amazing team at Mayo Clinic to jointly train a new frontier AI model for healthcare.
Our announcements today mark another milestone on the road to humanist superintelligence. You can learn more and about our other new models in our latest blog: https://t.co/v65eop5Ixq
Nobel Prize winning economist Kenneth Arrow wrote about "learning by doing" decades ago. He knew that productivity and expertise improve through experience.
The messy, repetitive works is often where you learn the patterns that eventually become judgment. Knowledge can be taught, but judgement is built through lived experience.
The first draft you rewrite. The customer call you listen to. The bug you fix and fix again. The factory floor you walk.
Small decisions you make every day teach you judgement. And, judgement is the thing everyone wants from senior people in the workplace. If we automate away every entry-level task without replacing the learning loop, we are removing a part of the process that creates experts.
The goal should be to use AI to accelerate learning, remove friction, and give people better tools to build expertise faster.
https://t.co/MpFZzCk1An
Thanks @Fortune & @tbove4 for sharing this story. Link in the comments.
Ever wondered what the origin of the name 'Westminster' is? Our church was founded in 960AD and became known as the 'west minster' to distinguish it from @StPaulsLondon (the 'east minster').
This image shows what we looked like in Norman times.
#LondonHistoryDay
A Oxford PhD student got flagged for submitting AI-generated work.
His advisor called it the most sophisticated research process he had seen in 20 years.
The student had not used AI to write a single word.
Here is the workflow that got him reported.
He starts every essay with a diagnostic he calls brutal. He dumps his rough argument into Claude and asks one question: what are the three weakest logical jumps in this reasoning, and where would a hostile examiner attack first? The AI does not write his essay. It destroys his draft, and then he rebuilds from whatever survives.
Most students using AI are doing the opposite. They hand Claude a topic and ask it to write. He hands Claude his thinking and asks it to find every place where that thinking falls apart. The difference between those two approaches is the difference between outsourcing your brain and sharpening it.
The second step is the one that made his advisor go quiet. He uploads the five most important papers in his field alongside his draft and asks Claude what claims in his argument contradict or oversimplify what these authors actually found. Most PhD students cite papers they have skimmed once. He cites papers he has been forced to genuinely reckon with, because Claude keeps catching the places where he got them wrong.
The final move is almost unfair. Before he submits anything, he pastes his conclusion and runs one more prompt. He asks what a philosopher of science would say is missing from this argument and what assumptions he is making that he has not defended. His essays come back from reviewers with phrases like unusually rigorous and demonstrates rare critical depth, and his committee has no idea that the depth came from a machine asking him harder questions than any human in his department was willing to ask.
The academic integrity hearing lasted three hours. The panel asked him to rebuild his methodology from scratch in the room. He opened his laptop and showed them exactly how the workflow ran, prompt by prompt. They did not just clear him. They gave him the highest grade in the department's history and asked him to present the process to faculty.
Here is what that story actually means. What took most PhD candidates six months of back-and-forth with advisors, he was compressing into a single session because he had figured out something almost nobody else has. AI does not make your thinking better by replacing it. It makes your thinking better by attacking it faster than any human critic ever would.
He was not using AI to write. He was using it to think harder than he could alone.
The tool is the same one everyone has. The workflow is the part nobody is teaching.
1/ We are sharing additional details regarding our investigation into unauthorized access to GitHub's internal repositories.
Yesterday we detected and contained a compromise of an employee device involving a poisoned VS Code extension. We removed the malicious extension version, isolated the endpoint, and began incident response immediately.
How do we make LLMs faster and lighter? Don’t force the GPU to adapt to sparsity. Reshape the sparsity to fit the GPU! ⚡️
Excited to share our new #ICML2026 paper in collaboration with @NVIDIA: "Sparser, Faster, Lighter Transformer Language Models". This work introduces new open-source GPU kernels and data formats for faster inference and training of sparse transformer language models:
Paper: https://t.co/3Avj8N8iYO
Blog: https://t.co/SqFkkKvkbd
Code: https://t.co/PHSzMq8pg0
While LLMs are undoubtedly powerful, they are increasingly expensive to train and deploy, with a large part of this cost coming from their feedforward layers. Yet, an interesting phenomenon occurs inside these layers: For any given token, only a small fraction of the hidden activations actually matter. The rest approximate zero, wasting computation. With ReLU and very mild L1 regularization, this sparsity can exceed 95% with little to no impact on downstream performance.
So, can we leverage this sparsity to make LLMs faster? The challenge is hardware. Modern GPUs are optimized for dense matrix multiplications. Traditional sparse formats introduce irregular memory access and overheads that cancel out their theoretical savings for GEMM operations.
Our contribution is twofold:
1/ We introduce TwELL (Tile-wise ELLPACK), a new sparse packing format designed to integrate directly in the same optimized tiled matmul kernels without disrupting execution.
2/ We develop custom CUDA kernels that fuse multiple sparse matmuls to maximize throughput and compress TwELL to a hybrid representation that minimizes activation sizes.
We used our kernels to train and benchmark sparse LLMs at billion-parameter scales, demonstrating >20% speedups and even higher savings in peak memory and energy.
This work will be presented at #ICML2026. Please check out our blog and technical paper for a deep dive!
The human brain🧠 is incredibly efficient because it only activates the specific neurons needed for a thought. Modern LLMs naturally try to do this too (> 95% of neurons in feedforward layers stay silent for any given word), but our hardware punishes them for it.
One of the most frustrating paradoxes in deep learning: making a model do less math often makes it run slower. Why? Because unstructured sparsity introduces irregular memory access, and GPUs are built for predictable, dense blocks of math.
We teamed up with @NVIDIA to try to fix this hardware mismatch. Instead of forcing the GPU to adapt to the sparsity, we built a "Hybrid" format that reshapes the sparsity to fit the GPU. Our sparsity format (TwELL) dynamically routes the 99% of highly sparse tokens through a fast path, and uses a dense backup matrix as a safety valve for the rare, heavy tokens.
Through TwELL and a new set of custom CUDA kernels for both LLM inference and training, we translated theoretical sparsity into actual wall-clock speedups: >20% faster training and inference on H100 GPUs, while also cutting energy consumption and memory requirements.
Paper: https://t.co/rqIY9SYBDe
Blog: https://t.co/oRjNbpJKha
Code: https://t.co/FAFaJwpxAJ
⚡️
In 1905, Einstein theorised that time doesn’t pass at the same rate for everyone—it depends on speed and gravity. A moving clock (relative to you) ticks more slowly than your own, and a clock deeper in a strong gravitational field also runs slower than one farther away. So two people who move differently or sit in different gravitational environments will age by slightly different amounts, even if they later meet again and compare watches.
The Riemann Hypothesis is the biggest unsolved math problem in history… and it secretly runs half of computer science.
Your encryption, AI randomness, prime-based algorithms - they all quietly depend on it.
Let me explain it so even non-math CS folks get the “whoa” moment. 🧵
Claude Code fully dissected!
Researchers from UCL reverse-engineered the leaked Claude source. What they found changes how you should think about agent design.
Only 1.6% of the codebase is AI decision logic.
The other 98.4% is operational infrastructure. Permission gates, tool routing, context compaction, recovery logic, session persistence. The model reasons. The harness does everything else.
This is the opposite of what most agent frameworks do today.
LangGraph routes model outputs through explicit state machines. Devin bolts heavy planners onto operational scaffolding. Claude Code gives the model maximum decision latitude inside a rich deterministic harness, and invests all its engineering effort in that harness.
The core loop is a simple while-true. Call model, run tools, repeat.
But the systems around that loop are where the real design lives:
A permission system with 7 modes and an ML classifier. Users approve 93% of prompts anyway, so the architecture compensates with automated layers instead of adding more warnings.
A 5-layer context compaction pipeline. Each layer runs only when cheaper ones fail. Budget reduction, snip, microcompact, context collapse, auto-compact.
Four extension mechanisms ordered by context cost. Hooks (zero), skills (low), plugins (medium), MCP (high). Each answers a different integration problem.
Subagents return only summary text to the parent. Their full transcripts live in sidechain files. Agent teams still cost roughly 7x the tokens of a standard session.
Resume does not restore session-scoped permissions. Trust is re-established every session. That friction is the point.
The bet behind all of this is simple. As frontier models converge on raw coding ability, the quality of the harness becomes the differentiator, not the model.
Paper: Dive into Claude Code (arXiv:2604.14228)
In the next tweet, I've shared an article I wrote on Agent Harness and what every big company is building. Do check.
Institutional onchain markets face a structural privacy gap.
Trusted Execution Environments (TEEs) are emerging as core infrastructure for institutional onchain markets by resolving the tension between transparency and confidentiality. By enabling private execution with verifiable onchain outputs, TEEs support settlement privacy, confidential RWAs, and real-time compliance.
Early deployments by @OasisProtocol and @PhalaNetwork show how TEEs can act as privacy coprocessors for regulated DeFi.
🚨: There have been thousands of generations of humans, and you are alive to witness the first photo of a Sunset on another World.😮
This is a real photo of the sunset on Mars.
Anthropic dropped a 33-page guide on Claude Skills...And this changes how serious teams build AI workflows
A Claude Skill is basically a reusable workflow in a folder. One https://t.co/CTRveEHjoi file teaches Claude exactly how you want tasks done consistently every time
The real insight isn’t Skills....It’s how to design them properly:
• Build micro-skills, not monoliths
• Keep instructions short and decisive
• Move heavy context into references and assets
• Always refine generated Skills manually
• Connect Skills to tools via MCP and hooks
That’s when AI stops being a chatbot… and starts becoming a system
Link - https://t.co/oUVuXLnSyf
https://t.co/pBRFjyTJgE
🚨 Someone just built a tool that turns any GitHub repo into an interactive knowledge graph and open sourced it for free.
It's called GitNexus. Think of it as a visual X-ray of your codebase but with an AI agent you can actually talk to.
Here's what it does inside your browser:
→ Parses your entire GitHub repo or ZIP file in seconds
→ Builds a live interactive knowledge graph with D3.js
→ Maps every function, class, import, and call relationship
→ Runs a 4-pass AST pipeline: structure → parsing → imports → call graph
→ Stores everything in an embedded KuzuDB graph database
→ Lets you query your codebase in plain English with an AI agent
Here's the wildest part:
It uses Web Workers to parallelize parsing across threads so a massive monorepo doesn't freeze your tab.
The Graph RAG agent traverses real graph relationships using Cypher queries not embeddings, not vector search. Actual graph logic.
Ask it things like "What functions call this module?" or "Find all classes that inherit from X" and it traces the answer through the graph.
This is the kind of code intelligence tool enterprise teams pay thousands per month for.
It runs entirely in your browser. Zero server. Zero cost.
Works with TypeScript, JavaScript, and Python.
100% Open Source. MIT License.
The exponential continues.
Nov 2025: Opus 4.5 had a 5hr 20 time horizon.
Feb 2026: Opus 4.6 has a 14hr 30 time horizon.
Over three months, that's more than a *doubling* in the duration of coding tasks, measured by how long it takes human professionals, that AI can complete with 50% accuracy.
Note that at this duration, the estimate is very noisy - see the thread from @METR_Evals for more on this. Now that agents can do most of the tasks on their benchmark, it's harder to be confident. But it looks like this is sitting above-trend.
Read our full explainer on what this measure means: https://t.co/y3sGardnTk
Peter Steinberger is joining OpenAI to drive the next generation of personal agents. He is a genius with a lot of amazing ideas about the future of very smart agents interacting with each other to do very useful things for people. We expect this will quickly become core to our product offerings.
OpenClaw will live in a foundation as an open source project that OpenAI will continue to support. The future is going to be extremely multi-agent and it's important to us to support open source as part of that.
NVIDIA just dropped PersonaPlex-7B 🤯
A full-duplex voice model that listens and talks at the same time.
No pauses. No turn-taking. Real conversation.
100% open source. Free.
Voice AI just leveled up.
https://t.co/YfzFQfBzMS
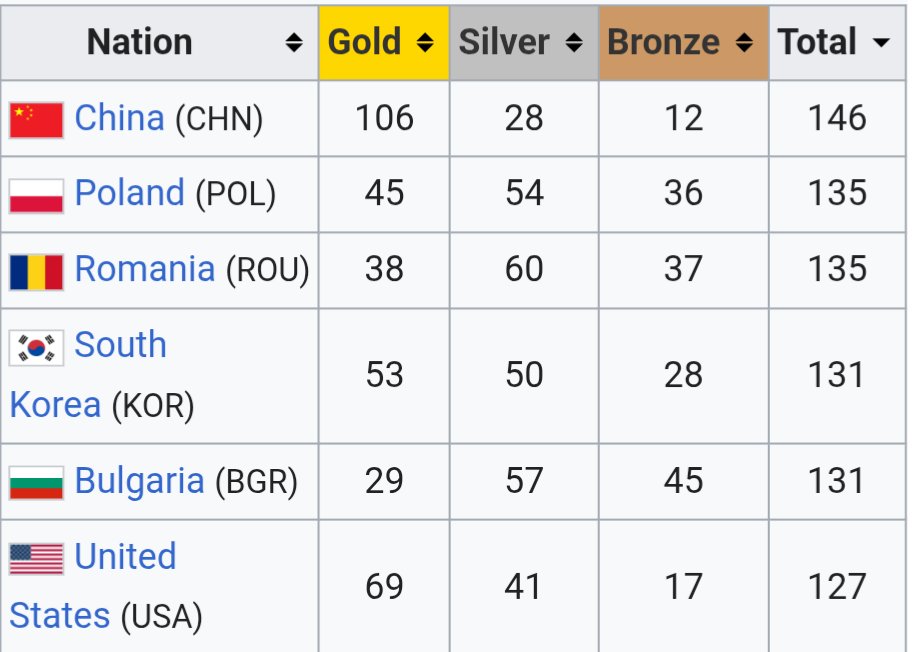
CEE nations Poland 🇵🇱, Romania 🇷🇴, and Bulgaria 🇧🇬 are top 5 globally in Informatics Olympiad total medals won.
Expect more AI superpower companies like @elevenlabs or @OpenAI coming out of the region in the coming years.
Incidentally CEE is where I invest via @smokvc 💪🏻