We finally got some time to I finally got some time properly reflect on everything @SnowflakeDB announced last week at Summit 2023.
Learn about every announcement and our thoughts on each in our latest post👇
https://t.co/unKXEGP4bk
Back in March we had the opportunity to speak at @DataCouncilAI in Austin. We had a blast sharing everything we've learned about @SnowflakeDB cost and performance optimization.
Slides & recording now available 👇
https://t.co/33hm57TVW2
Another great post from @select_dev about CTEs.
Summary:
- continue using CTEs 🤘
- specify column names (don't "import" with select *)
- for special queries, experiment with repeating logic instead of reusing CTEs
- learn how to read query plan
https://t.co/vSGXwhLt6v
We're two weeks out from the next Analytics Engineering meetup in London at the @thoughtmachine office.
🙏Big thank you to our friends over @SpectaclesCI and @select_dev for letting us support such a great event!
The countdown to grab your seat is on! 👉 https://t.co/LzGBI7t8lQ
🗣️UK friends: The next Analytics Engineering meetup is approaching fast!
🤝We’ve joined forces with @SpectaclesCI and @select_dev in co-hosting this event at @thoughtmachine in London, March 23 at 6pm GMT.
Save your seat 👉https://t.co/dSyHDHWYMZ
@SnowflakeDB query tags are indeed awesome. We recently covered them in depth for those wondering why and how they should use them: https://t.co/c6CpcaZSSq
⚠️ Unfortunately, this function isn't guaranteed to be deterministic. As a result, it won't be able to leverage Snowflake's result cache, so be careful when using in performance or cost sensitive applications where the query is executed frequently.
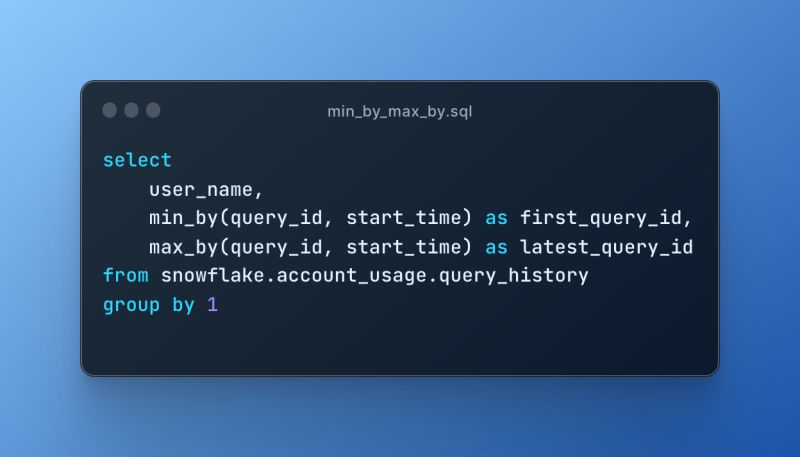
In @SnowflakeDB 's latest release, they've given us a nice new set of aggregate functions: min_by and max_by.
In this example I look across each user's query history, and find the ID of the first and last queries they executed.
More generally, you can use these to find the row containing the min/max value for a particular column, then return the value of another column in that row.
Range joins are notoriously slow in many databases. @SnowflakeDB is no exception. We're using a binned range join technique across a number of models in our @getdbt project and have seen incredible results. A 300x speedup for this query.