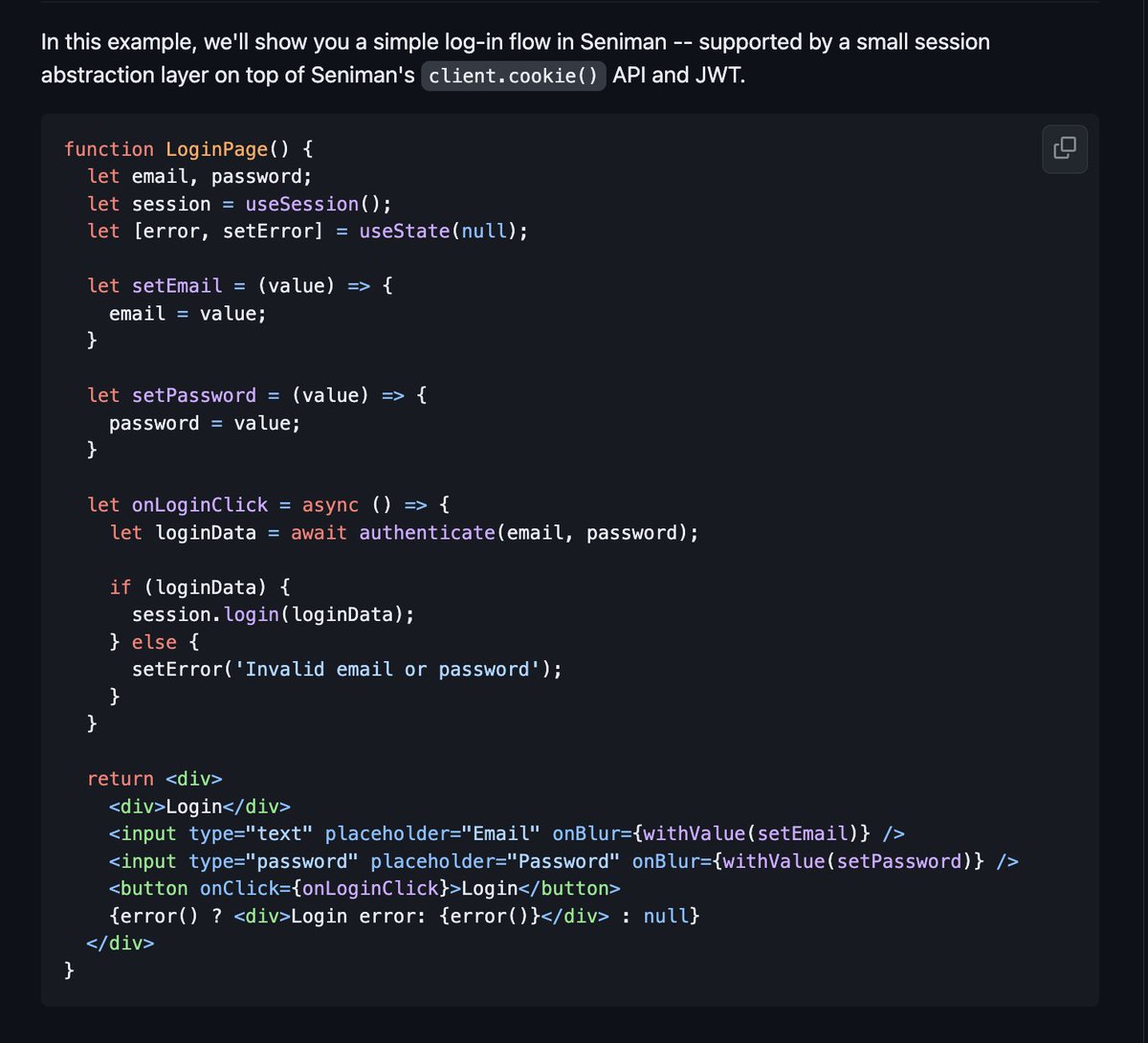
We're excited to early-release Seniman, a fast server-driven JSX UI framework for Node.JS
https://t.co/wD2FBxGDcR
More below, but TL;DR: run your JSX components on the server, streaming your UI through binary WebSocket, and have a completely interactive app with a 3KB JS bundle!
Seniman + Ollama + mixtral8x7b @ q3 quantization running on RTX3090 at 40 tokens/s
Near-GPT4 (but faster) model running on the same card I use to play games with.. not even a year after GPT4's launched.. insane
most of you have more following than we do and genuine usage experience will help us more immensely than any individual contribution right now
we've seen snippets of what others are building with Seniman, and we get a lot of installs the same day those tweets are shared!
🚀 🫡
recently we’ve been getting inquiries on contributing to Seniman
we believe the most helpful thing to do right now is to build small apps on Seniman and share your experience building, good or bad
that’ll get us both guidance to better devex *and* more exposure to more folks
if you want just one global DC region API-backing your @senimanjs UI running on Cloudflare, the answer might be DigitalOcean NYC3
free egress. great NA latency, good EU latency
SEA gets worst end of the stick @ 250ms. worse than Sydney
made a script to simulate UX; feels fast
Just built a Trello clone with @senimanjs in <400 LOC
All rendering incl. task reordering while dragging are driven by the server in realtime via websocket
All with 3KB of JS + ~8KB of websocket messages for initial UI. All data access are delayed by 10ms to simulate DB calls
@JLarky Yes the argument of htmx is that the client state isn’t a big deal. You only need something good enough based on the needs. If you also need client state then yeah it gets more complex. So htmx position is saying client shouldn’t manage state while traditional frontend does
just pushed a complete refactor of the scheduler at v0.0.153-alpha.3
a cleaner & smaller arch; opens up a path where we could later reimplement the whole scheduler in C with the same behavior and run it in WASM
let us know if the new scheduler behaves incorrectly in your app
@zenia2020 Done.
You can run `npx clone-seniman-app`
Hits the Github API to fetch list of example apps at https://t.co/E7m08UJTJf
Choose the example app to clone, hit enter to clone
@zenia2020 Done.
You can run `npx clone-seniman-app`
Hits the Github API to fetch list of example apps at https://t.co/E7m08UJTJf
Choose the example app to clone, hit enter to clone
This means 3KB is all the JS you need to bootstrap your app. Elements will stream in from the server through WebSocket as soon as they are ready, and attach to the DOM. The browser executes very little in the meantime and stays responsive.
for the same GPT4 conversation
@senimanjs downloads 3KB of JS & 5KB of websocket for UI set up. then ~10KB per message with 3 code blocks
OpenAI's UI downloads 1.6MB of JS, then downloads 450KB (!) per message of same size
45x larger per message, 200x larger initial set up