Is awe truly ambivalent in the brain? 🌌🧠
Using our #Enobio, researchers found that ambivalent affect occupies a distinct neural space during awe-inducing VR, with frontoparietal dynamics predicting subjective intensity.
Full study: https://t.co/juXSXexul0
#EEG#Emotion
I had the same thought so I've been playing with it in nanochat. E.g. here's 8 agents (4 claude, 4 codex), with 1 GPU each running nanochat experiments (trying to delete logit softcap without regression). The TLDR is that it doesn't work and it's a mess... but it's still very pretty to look at :)
I tried a few setups: 8 independent solo researchers, 1 chief scientist giving work to 8 junior researchers, etc. Each research program is a git branch, each scientist forks it into a feature branch, git worktrees for isolation, simple files for comms, skip Docker/VMs for simplicity atm (I find that instructions are enough to prevent interference). Research org runs in tmux window grids of interactive sessions (like Teams) so that it's pretty to look at, see their individual work, and "take over" if needed, i.e. no -p.
But ok the reason it doesn't work so far is that the agents' ideas are just pretty bad out of the box, even at highest intelligence. They don't think carefully though experiment design, they run a bit non-sensical variations, they don't create strong baselines and ablate things properly, they don't carefully control for runtime or flops. (just as an example, an agent yesterday "discovered" that increasing the hidden size of the network improves the validation loss, which is a totally spurious result given that a bigger network will have a lower validation loss in the infinite data regime, but then it also trains for a lot longer, it's not clear why I had to come in to point that out). They are very good at implementing any given well-scoped and described idea but they don't creatively generate them.
But the goal is that you are now programming an organization (e.g. a "research org") and its individual agents, so the "source code" is the collection of prompts, skills, tools, etc. and processes that make it up. E.g. a daily standup in the morning is now part of the "org code". And optimizing nanochat pretraining is just one of the many tasks (almost like an eval). Then - given an arbitrary task, how quickly does your research org generate progress on it?
All consciousness theories on one page!
It's crazy we have 100s of theories of consciousness, this abundance seems unprecedented in the history of science.
We need theories to make surprising, discriminating predictions to sift this list down to few plausible candidates.
Very excited about the "First Proof" challenge. I believe novel frontier research is perhaps the most important way to evaluate capabilities of the next generation of AI models.
We have run our internal model with limited human supervision on the ten proposed problems. The problems require expertise in their respective domains and are not easy to verify; based on feedback from experts, we believe at least six solutions (2, 4, 5, 6, 9, 10) have a high chance of being correct, and some further ones look promising.
We will only publish the solution attempts after midnight (PT), per the authors' guidance - the sha256 hash of the PDF is d74f090af16fc8a19debf4c1fec11c0975be7d612bd5ae43c24ca939cd272b1a .
This was a side-sprint executed in a week mostly by querying one of the models we're currently training; as such, the methodology we employed leaves a lot to be desired. We didn't provide proof ideas or mathematical suggestions to the model during this evaluation; for some solutions, we asked the model to expand upon some proofs, per expert feedback. We also manually facilitated a back-and-forth between this model and ChatGPT for verification, formatting and style. For some problems, we present the best of a few attempts according to human judgement.
We are looking forward to more controlled evaluations in the next round!
https://t.co/jtLCOhJftv #1stProof
I appreciate @Anthropic's honesty in their latest system card, but the content of it does not give me confidence that the company will act responsibly with deployment of advanced AI models:
-They primarily relied on an internal survey to determine whether Opus 4.6 crossed their autonomous AI R&D-4 threshold (and would thus require stronger safeguards to release under their Responsible Scaling Policy). This wasn't even an external survey of an impartial 3rd party, but rather a survey of Anthropic employees.
-When 5/16 internal survey respondents initially gave an assessment that suggested stronger safeguards might be needed for model release, Anthropic followed up with those employees specifically and asked them to "clarify their views." They do not mention any similar follow-up for the other 11/16 respondents. There is no discussion in the system card of how this may create bias in the survey results.
-Their reason for relying on surveys is that their existing AI R&D evals are saturated. Some might argue that AI progress has been so fast that it's understandable they don't have more advanced quantitative evaluations yet, but we can and should hold AI labs to a high bar. Also, other labs do have advanced AI R&D evals that aren't saturated. For example, OpenAI has the OPQA benchmark which measures AI models' ability to solve real internal problems that OpenAI research teams encountered and that took the team more than a day to solve.
I don't think Opus 4.6 is actually at the level of a remote entry-level AI researcher, and I don't think it's dangerous to release. But the point of a Responsible Scaling Policy is to build institutional muscle and good habits before things do become serious. Internal surveys, especially as Anthropic has administered them, are not a responsible substitute for quantitative evaluations.
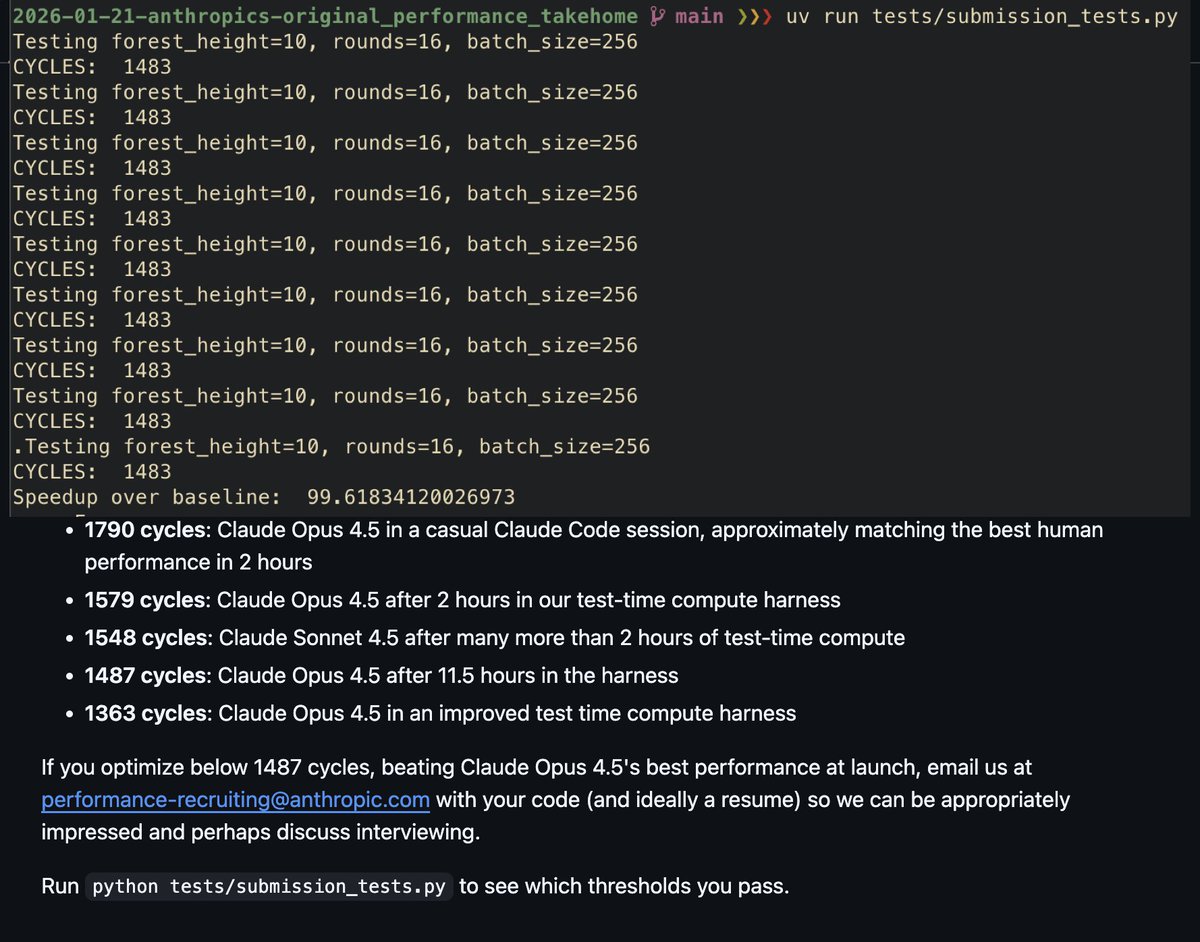
Anthropic has open sourced their (old) take home
A casual codex session after 2 hours beats "Claude Opus 4.5 in a casual Claude Code session" and "Claude Opus 4.5 after 11.5 hours in the harness"
: )
Logic is a foundation for many things. But what are the foundations of logic itself?
Back in 2000, @stephen_wolfram got a computer to prove that all we need is ((a•b)•c)•(a•((a•c)•a))==c
But can we humans understand why?
https://t.co/jdouYohzHj
#WorldLogicDay
Our Archivara Agent (now powered by GPT-5.2 Pro) has achieved a new record in spherical packing for $(n=11, N=432)$, a result now verified against the benchmark library maintained by Henry Cohn (MIT).
Moving beyond standard Riesz-energy minimization, our agent targeted the non-smooth $\ell_\infty$ objective: $\min_X \max_{i<j} \langle x_i, x_j \rangle$ on the manifold $S^{10}$. By identifying the "contact graph" of the packing, the agent applied a geodesic pair-pivot heuristic.
Instead of a global gradient update, the agent performed symmetric 2D rotations in the subspace $\mathrm{span}(x_i, x_j)$ of the worst-case pair, using a gap-based step size to equalize the top constraints. This successfully unlocked a high-dimensional local minimum that had stalled previous numerical searches, yielding a new best-known cosine of $t \approx 0.49422771$.
This demonstrates the power of AI-driven active-set methods in resolving "jammed" states in experimental mathematics.
Image: 6d (3D/RGB projection)
Weekend win: The proof I submitted for Erdos Problem #397 was accepted by Terence Tao.
The proof was generated by GPT 5.2 Pro and formalized with Harmonic.
Many open problems are sitting there, waiting for someone to prompt ChatGPT to solve them:
I’m worried that “doom” speculation will make doom more likely. Specifically, AIs conform to our expectations of them, as communicated by their training data. This “self-fulfilling misalignment data” may be poisoning training already. 🧵
For the first time, an AI model (GPT-5) autonomously solved an open math problem submitted to our benchmarking project IMProofBench, with a complete, correct proof, without human hints or intervention.
A small but novel contribution to enumerative geometry. Some background:
GPT-5.2 solves our COLT 2022 open problem: “Running Time Complexity of Accelerated L1-Regularized PageRank” using a standard accelerated gradient algorithm and a complementarity margin assumption.
Link to the open problem: https://t.co/A3ZbJshudE
All proofs were generated by GPT-5.2 Pro. The key bounds on the algorithm’s total work (in the COLT’22 open-problem setting) have been auto-formalized using a combination of GPT-5.2 Pro, @HarmonicMath's Aristotle, and Gemini 3 Pro (High) on Antigravity.
Link to the proof: https://t.co/hgJ0iBcWJe
Link to the Lean code: https://t.co/DeMFDlwSC9
Link to the informalization of the Lean code: https://t.co/V5BwYoIycN
Link to my GPT-5.2 prompts: https://t.co/xwh5c6S81B
In addition to the formalization of the main result, I checked the proof myself twice. I hope I didn’t miss anything, but if I did, please let me know and I will try to fix it.
Story behind the paper and relevant work
In 2016, I worked on the convergence rate of the Iterative Soft-Thresholding Algorithm (ISTA) for l1-regularized PageRank.
Link to the corresponding paper: https://t.co/pDMN9QKkGh
Surprisingly, the running time of the algorithm depends only on the number of non-zero nodes at optimality. It was only natural to ask the same question for accelerated methods, such as FISTA. However, we quickly realized that FISTA activates more nodes than the number of non-zeros at optimality, even though it eventually converges to the same active set. In practice, we would still observe that FISTA is fast.
Link to empirical work: https://t.co/VQFJugQk0m
I tried for about three months to bound the total work of FISTA and other accelerated algorithms, and from time to time I would come back to the problem while I was a postdoctoral fellow. Eventually, I gave up. I gave it another try around 2021, and I failed again. I asked my excellent former student, Shenghao Yang, and he also failed, unfortunately. I asked a couple of prominent researchers if they think the problem is solvable, they quickly mentioned that it seemed hard. We ended up publishing it as an open problem at COLT 2022.
In 2023, David Martínez-Rubio et al. provided the first successful solution. Their solution is “orthogonal” to what was proved by GPT-5.2.
Link to their paper: https://t.co/YPUrfGhG2T I loved their work btw, I also met David in person at ICML 2024, one of the few ML conferences I ever attended.
Their proposed accelerated algorithm is not necessarily faster than ISTA; however, it does offer a new trade-off between the teleportation parameter of PageRank and the total work per iteration. More importantly, the proposed method isn’t necessarily practical, since it involves solving an expensive subproblem. To be fair, in the COLT 2022 problem, we didn’t impose the additional hard constraint of using standard accelerated methods. The problem was posed as a theoretical problem. The solution proved by GPT-5.2 establishes acceleration for the standard FISTA algorithm, which performs only one gradient computation per iteration. It also offers a clean parameterization of the total work with respect to a complementarity margin, which, for certain graph structures, shows a clear speed-up compared to ISTA.
In 2024, Zhou et al. (https://t.co/Agq5ANfhuS) gave it another go. However, in my view, their work has important drawbacks. In particular, their guarantees for accelerated localized methods (e.g., localized Chebyshev / Heavy-Ball) assume a condition on the geometric mean of certain active-ratio factors (described as Θ(\sqrt{α})) in order to obtain an accelerated bound.
Two distinctions matter for our setting:
First, their accelerated runtime bounds are parameterized by evolving-set quantities and a residual-ratio assumption, which can be evaluated during a run but is not typically interpretable or verifiable a priori from graph structure alone. The solution by GPT-5.2 instead provides an explicit transient-phase bound in terms of a standard optimization-structure condition, and converts this directly into a total work bound.
Second, they explicitly note that FISTA-style acceleration violates the monotonicity property needed to bound the per-iteration accessed volume, and emphasize that guaranteeing intermediate sparsity in accelerated frameworks is challenging. The margin-based analysis by GPT-5.2 directly targets this gap: even without any monotonicity of intermediate supports, GPT-5.2 bounded how much spurious activation can occur before the iterates enter a neighborhood of the unique minimizer, thereby yielding a concrete locality certificate for the accelerated proximal-gradient trajectory.
Since 2024, every time OpenAI or Google released a new major model, I would give it a go. This time, with GPT-5.2, it seems to have worked.