It is the nature of products with ML baked in where you see such failures. Even if new grads don’t have business sense (which they do?) there are other systems in place that make sure no product goes out with this intention, it happens and they will fix it. NL search is hard
This is what happens when you hire new grads with zero business understanding to do ML products.
if cosine similarity >= 0.85 show result (doesn't do Entity vs misspellings vs brand name check) 😭
Spending billions to train the "best" base model? You might be optimizing the wrong thing! 🎯
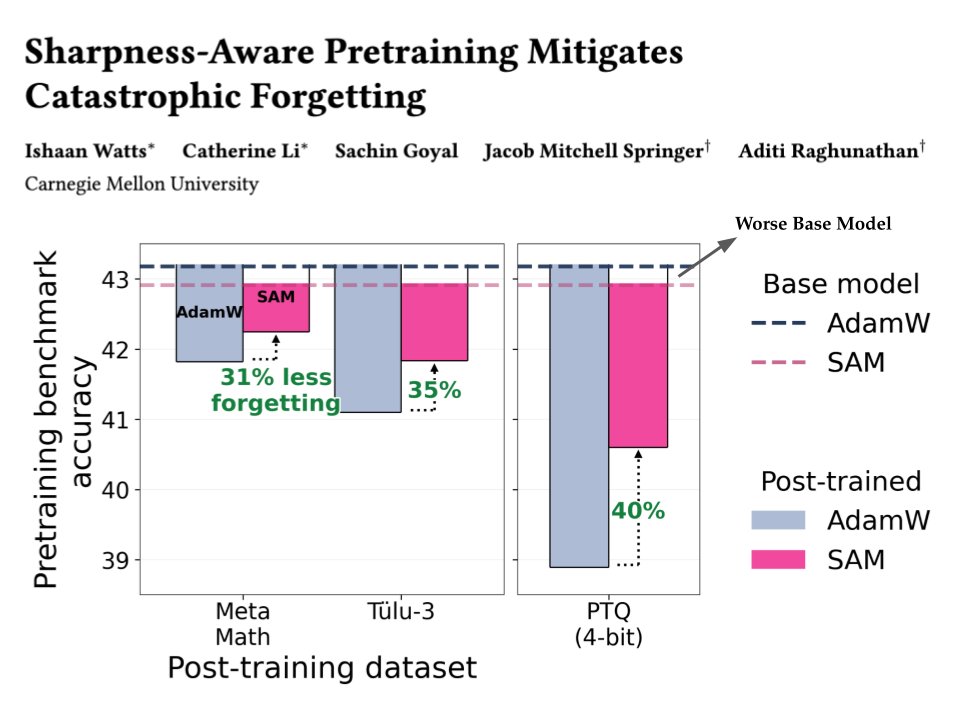
We show that controlling sharpness during mid-training leads to over 35% less forgetting after fine-tuning / quantization... even when the base model itself gets worse.
🧵 Takeaways for pretraining:
- Use SAM (Sharpness-Aware-Minimization) in the final steps (~10%)
- Try much higher learning rates (yes, even ~10× larger)
1/9
One of my really goated friends @SCSatCMU is looking for an ML Research/Engineer intern for the summer https://t.co/QMM1ISmq2s.
@Dogged_Raj
His offer got rescinded due to unfortunate circumstances. Hire him!
The MLSys’26 program is live!
Check out the accepted papers: https://t.co/PKTMF2pOt2
This year marks several exciting firsts:
• 28 industry track papers bridging MLSys research & real-world deployment
• Our inaugural competition track featuring AWS Trainium, Google Graph Scheduling, and NVIDIA FlashInfer AI Kernel contests
Early registration deadline: April 1 — don’t miss it! See you in Seattle this May🌲
Gemini and the Autocompletion model @cursor_ai both use some really funny data. I wish people could identify source of janky data, and there was some effort in removing that :)
If I had to compress my PhD into one idea, it is this
"The data a model sees early in training leaves an imprint on its representations that is very hard to undo later"
This thread runs through
- Rephrasing the Web
- Safety Pretraining
- TOFU
This is the Finetuner’s Fallacy🧵
Hi Everyone
I'm looking for interesting research scientist/engineer roles around LLM pretraining, studying behavior of agentic systems and just doing cool LLM research overall. If my work interests you and you're hiring feel free to DM/email/reply here!
If you believe the future of autonomy will be built on hardware like this, we should talk.
We’re building real-world AI systems and robots at JustJust AI — and we’re hiring.
Email me at [email protected]
Hiring in San Francisco/Gurgaon and Shenzhen
My team at @Uniphore is hiring summer research interns for 2026!
If you are a highly motivated graduate student in the US, interested in working on Language Agents (tool use, agent design, agent evaluation, agent optimization, etc.) or small models (efficient training, efficient serving, data synthesis techniques, RL), you should consider us!
We are a team with collective research exprience from Stanford, Google DeepMind, AWS AI, Apple, and more. We just published 3 papers at ICLR this year, check them out:
1. WARC-Bench (GUI agents): https://t.co/RuOumMvBTi
2. PolySkill (agent skill induction): https://t.co/RDL5ShoueJ
3. EvoPresent (presentation generation from academic papers): https://t.co/is2e0Guhzg
If you are interested, please send your resume and a brief note about your research interests to [email protected], and we will be in touch shortly!
Twitter, do your thing. My girlfriend, who is an MS robotics student @SCSatCMU, is looking for a summer internship! She is interested in working at the intersection of Robotics+ML, was an intern at @Google, and did her undergrad at @IITKanpur
We’re quietly assembling a small, elite team at @InceptLabsAI to work on long-horizon AI research that actually matters.
Roles: AI/ML researchers (strong preference for people already doing frontier-level work).
If you’ve built something real (papers, open-source, strong internal research, shipped systems), we’d love to talk.
Stealth mode • best-in-class resources • equity that reflects the risk/reward.
If this sounds like your next chapter, reach out → DMs open 🚀