The US–Iran ceasefire has been extended, but the situation remains fragile.
Tensions continue amid strong rhetoric from both sides, while concerns over the Hormuz Strait keep global energy and security markets alert.
Analysts also point to uncertainty around US negotiating approaches, which could shape future developments if tensions rise again.
Iran continues to face internal and external pressures, including governance and security challenges.
The wider regional dynamics also draw attention to Pakistan’s strategic position in the evolving situation.
Despite the ceasefire, the risk of escalation remains.
@Nidhi@StevenErlanger@suhasinih
#USIran #Geopolitics #IndiaAndTheWorld #Pakistan #GlobalPolitics #MiddleEast #OilPrices #StraitOfHormuz #WorldNews #InternationalRelations #WorldAffairs #Trump #DeKoder
Today in the SIR hearing of WB, Justice Bagchi raised many important concerns:
The right to vote is a very important emotional issue.
1. The issue of “Logical discrepancy which placed 60L voters in the doubtful category was raised for the first time in Bengal. 27L voters have been taken off the rolls on this account.
2. These 27,00,000 votes taken off the roles were not given any personal hearings, nor were reasons given for their removal.
3. If the margin of the winner is less than the number of voters removed in this manner, what will be the sanctity of the result?
Serving Brigadier, his wife & son are assaulted by anti social elements in the presence of Delhi police officers. FIR is not registered for 2 days & registered only after the issue was raised on social media.
This is the state of Amit Shah’s police as he goes around campaigning!
Europe and India are making history today.
We have concluded the mother of all deals.
We have created a free trade zone of two billion people, with both sides set to benefit.
This is only the beginning.
We will grow our strategic relationship to be even stronger.
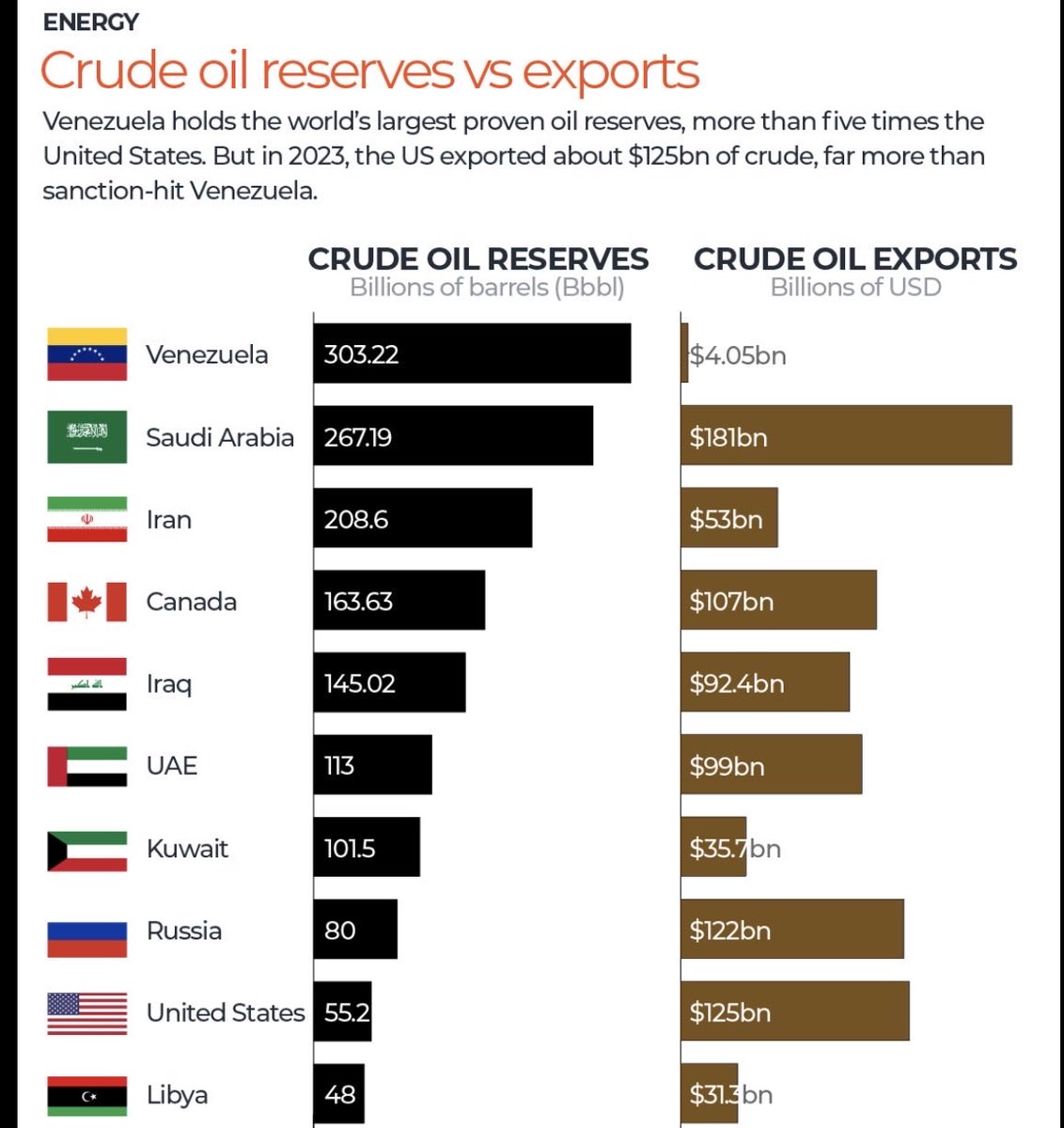
The US has launched an unprovoked and illegal attack on Venezuela.
This is a brazen attempt to secure control over Venezuelan natural resources.
It is an act of war that puts the lives of millions of people at risk — and should be condemned by anyone who believes in sovereignty and international law.
The next 72 hours are critical for the world.
If the United States succeeds in imposing control over Venezuela, and by extension over the world’s largest proven oil reserves, it will mark a major shift in global power.
Such a move would not be about restoring democracy or protecting human rights, but about reasserting strategic dominance over energy, trade routes, and regional alignments.
In that case, Iran would likely move to the forefront of Washington’s strategic priorities.
Securing control over Venezuelan oil would reduce U.S. vulnerability to energy disruptions in the Gulf and provide a buffer against supply shocks in the event of a confrontation with Iran.
With a reliable alternative source of heavy crude under its influence, Washington would be better positioned to absorb or offset the destruction or shutdown of energy infrastructure in the Persian Gulf during a war.
This would lower the economic cost of escalation and make military pressure against Iran more politically and economically manageable.
At the same time, such control would strengthen the United States’ ability to shape global oil flows and pricing, reinforcing the central role of the dollar in energy markets and helping preserve the petrodollar system that underpins U.S. financial power.
Venezuela would thus become more than a regional issue.
It would become a strategic precedent, a demonstration that economic pressure, political engineering, and, if necessary, force can be used to restructure sovereign states and realign the global balance of power.
However, if the United States becomes entangled in Venezuela and faces sustained resistance, the outcome shifts dramatically.
A prolonged crisis would drain political capital, stretch military and economic resources, and weaken Washington’s capacity to project power elsewhere, including in the Middle East.
That would also complicate Israeli strategic planning, which is closely tied to U.S. regional leverage.
What happens in Venezuela will not stay in Latin America.
It will shape the future of energy control, the limits of American power, and the direction of geopolitical confrontation far beyond Caracas.
🔥🔥🔥 DO NOT BE DISTRACTED & STAY LOUD!!
🔥🔥🔥 DONALD TRUMP IS GOING DOWN!!
TRUMP & EPSTEIN ARE SEX TRAFFICKERS!!! I’m gonna post this every day so nobody forgets exactly who Pedophile Trump is and why the Epstein files have suddenly disappeared. 🔥🔥🔥🔥🔥🔥
The reason why Venezuela is under attack
U.S. Southern Command chief General Laura Richardson just said the truth out loud:
the U.S. focus in Latin America isn’t “democracy” — it’s controlling oil, lithium, gold, and rare earth minerals. Venezuela, with the largest oil reserves and key strategic resources, is the main target
To believe this is about drug smuggling, you have to ignore Trump’s pardon of the former Honduran president for drug smuggling.
To believe it’s about Maduro’s democratic legitimacy, you have to believe Trump cares even slightly about democratic legitimacy.
Alternatively:
Prime Minister Narendra Modi tweets, "Presented a copy of the Gita in Russian to President Putin. The teachings of the Gita give inspiration to millions across the world"
Putin’s meeting with PM Modi lands at a decisive moment in global power play. With the US slapping steep tariffs on India, this visit fires off a bold reminder to Trump: India doesn’t crumble under pressure. We adapt, we expand, and our market momentum isn’t slowing for anyone. 🇮🇳💪🇷🇺
Dear parents
Buy these as a new year gifts for your children if they are in the age group 13-15. Later in their lives, they would be immensely grateful to you if they really cared to do this task throughout their school years. So, motivate them to do this wonderful collection.
Who Invented Transformer Neural Networks (the T in ChatGPT)? Timeline of Transformer evolution https://t.co/7EJPAnRKvI
★ 1991. Original tech report on what's now called the unnormalized linear Transformer (ULTRA)[FWP0][ULTRA]. KEY/VALUE was called FROM/TO. ULTRA uses outer product rules to associate its self-invented KEYs/VALUEs through fast weights [FAST][FWP], and applies the resulting context-dependent attention mappings to incoming queries. ULTRA's computational costs scale linearly in input size, that is, for 1,000 times more text we need 1,000 times more compute, which is acceptable. Like modern quadratic Transformers (see below), the 1991 ULTRA is highly parallelizable. It was a by-product of more general research on neural networks (NNs) that learn to program fast weight changes of other NNs [FWP,FWP0-9,FWPMETA1-10], back then called fast weight controllers [FWP0] or fast weight programmers (FWPs) [FWP]. ULTRA was presented as an alternative to recurrent NNs [FWP0]. The 1991 experiments were similar to today's: predict some effect, given a sequence of inputs [FWP0].
★ 1992. Journal publication on ULTRA [FWP1], based on the 1991 tech report. Note that the terminology was different back then.
★ 1993. Recurrent ULTRA extension [FWP2] introducing the terminology of learning "internal spotlights of attention."
★ 2014. End-to-end sequence-to-sequence models [S2Sa,b,c,d] became popular for Natural Language Processing. They were not based on the 1991 unnormalized linear Transformer [ULTRA] above, but on the Long Short-Term Memory (LSTM) recurrent NN from the same lab. In 2014, this approach was combined with an attention mechanism [ATT14] that isn't linearized like the 1991-93 attention [FWP0-2] but includes a nonlinear softmax operation. The first Large Language Models (LLMs) were based on such LSTM-attention systems. See additional work on attention from 2016-17 [ATT16a-17b].
★ 2017. Modern quadratic Transformer ("attention is all you need"), scaling quadratically in input size [TR1], that is, for 1,000 times more text we need 1,000,000 times more compute. Note that in 1991 [ULTRA], no journal would have accepted an NN that scales quadratically, but by 2017, compute was cheap enough to apply the quadratic Transformer (a kind of fast weight programmer [FWP]) to large amounts of data on massively parallel computers. The quadratic Transformer combines the 1991 additive outer product fast weight principle [FWP0-2] and softmax (see 2014 above): attention (query, KEY, VALUE) ~ softmax (query KEY) VALUE.
★ 2020. New paper [TR5] using the terminology "linear Transformer" for a more efficient Transformer variant that scales linearly, leveraging linearized attention [TR5a].
★ 2021. Paper [FWP6] pointing out that the unnormalised linear Transformer [TR5-6] is actually MATHEMATICALLY EQUIVALENT to the 1991 fast weight controller [FWP0][ULTRA] published when compute was a million times more expensive than in 2021. Overview of ULTRA and FWPs (2021) [FWP].
★ 2021-25. Work on extensions of ULTRAs and other FWPs (such as the DeltaNet [FWP6]) has become mainstream research, aiming to develop sequence models that are both efficient and powerful [TR6,TR6a][LT23-25][FWP23-25b].
Of course, plain outer products in NNs go back at least to Konorski's informal 1948 rule [HEB48] (later sometimes called the "Hebb rule" [HEB49]) and concrete formal implementations through Steinbuch's Learning Matrix around 1960 [ST61-63][AMH1-2][KOH72][LIT74][PAL80]. See also bidirectional associative memories (1988) [KOS88]. However, these authors described pre-wired rules to associate user-given patterns with each other. Unlike ULTRA and other Transformers since 1991 [ULTRA][TR1], their NNs did not learn to use such rules for associating self-invented KEY/VALUE patterns, by backpropagating errors [BP4] THROUGH the rules, to generate appropriate KEYs/VALUEs at the right times and create useful changes of fast weights. (Neither did early NNs with fast weights by Malsburg (1981) and others [FAST][FASTa,b][DLP].)
**********
SELECTED REFERENCES (remaining references in: Who Invented Transformer Neural Networks? Technical Note IDSIA-11-25, Nov 2025 - see link above)
[ATT] Juergen's AI Blog (2020, updated 2025): 30-year anniversary of end-to-end differentiable sequential neural attention. Plus goal-conditional reinforcement learning. There was both hard attention for foveas (1990) and soft attention in form of Transformers with linearized self-attention (1991-93) [ULTRA]. Today, both types are very popular.
[ATT14] D. Bahdanau, K. Cho, Y. Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. 2014-16. Preprint arXiv/1409.0473, 2014-16.
[FAST] C. v.d. Malsburg. Tech Report 81-2, Abteilung f. Neurobiologie, Max-Planck Institut f. Biophysik und Chemie, Goettingen, 1981. First paper on fast weights or dynamic links.
[FWP] 26 March 1991: Neural nets learn to program neural nets with fast weights—like Transformer variants. 2021: New stuff! AI Blog, 26 March 2021, updated 2025.
[FWP0] J. Schmidhuber. Learning to control fast-weight memories: An alternative to recurrent nets. Technical Report FKI-147-91, TU Munich, 26 March 1991. First paper on neural fast weight programmers (FWPs) that separate storage and control: a slow net learns by gradient descent to compute weight changes of a fast net. The outer product-based version (Eq. 5) is now known as the unnormalized linear Transformer or the "Transformer with linearized self-attention" [ULTRA][FWP].
[FWP1] J. Schmidhuber. Learning to control fast-weight memories: An alternative to recurrent nets. Neural Computation, 4(1):131-139, 1992. Based on [FWP0].
[FWP2] J. Schmidhuber. Reducing the ratio between learning complexity and number of time-varying variables in fully recurrent nets. In Proceedings of the International Conference on Artificial Neural Networks, Amsterdam, pages 460-463. Springer, 1993. A recurrent extension of the 1991 unnormalized linear Transformer [ULTRA], introducing the terminology of learning "internal spotlights of attention." First recurrent NN-based fast weight programmer using outer products to program weight matrix changes.
[FWP6] I. Schlag, K. Irie, J. Schmidhuber. Linear Transformers Are Secretly Fast Weight Programmers. ICML 2021. Preprint: arXiv:2102.11174. Shows that the unnormalised linear Transformer is actually MATHEMATICALLY EQUIVALENT to the 1991 system [FWP0][ULTRA] published when compute was a million times more expensive than in 2021.
[FWP7] K. Irie, I. Schlag, R. Csordas, J. Schmidhuber. Going Beyond Linear Transformers with Recurrent Fast Weight Programmers. NeurIPS 2021. Preprint: arXiv:2106.06295
[HEB48] J. Konorski (1948). Conditioned reflexes and neuron organization. Translation from the Polish manuscript under the author's supervision. Cambridge University Press, 1948. Konorski published the so-called "Hebb rule" before Hebb [HEB49].
[HEB49] D. O. Hebb. The Organization of Behavior. Wiley, New York, 1949. Konorski [HEB48] published the so-called "Hebb rule" before Hebb.
[KOS88] B. Kosko. Bidirectional associative memories. IEEE Transactions on Systems, Man, and Cybernetics, 18(1):49-60, 1988.
[LT20] A. Katharopoulos, A. Vyas, N. Pappas, F. Fleuret. Transformers are RNNs: Fast autoregressive Transformers with linear attention. In Proc. Int. Conf. on Machine Learning (ICML), July 2020.
[LT21] I. Bello. LambdaNetworks: Modeling Long-Range Interactions Without Attention. Preprint arXiv:2102.08602. A linear transformer variant.
[LT23] K. Irie, R. Csordas, J. Schmidhuber. Practical Computational Power of Linear Transformers and Their Recurrent and Self-Referential Extensions. EMNLP 2023.
[LT24] S. Yang, B. Wang, Y. Zhang, Y. Shen, Y. Kim. Parallelizing Linear Transformers with the Delta Rule over Sequence Length. NeurIPS 2024.
[LT25] S. Yang, J. Kautz, A. Hatamizadeh. Gated Delta Networks: Improving Mamba2 with Delta Rule. ICLR 2025. "Mamba2" is essentially the 1991 ULTRA with a scalar time-decay factor on the fast weight matrix.
[LT25b] R. Grazzi, J. Siems, A. Zela, J. K.H. Franke, F. Hutter, M. Pontil. Unlocking State-Tracking in Linear RNNs Through Negative Eigenvalues. ICLR 2025. Shows that the delta-rule extension [FWP6][LT23] is more expressive than the quadratic Transformer and other naive linear Transformers (e.g., it can do parity and modular arithmetics).
[LT25c] J. Siems, T. Carstensen, A. Zela, F. Hutter, M. Pontil, R. Grazzi. DeltaProduct: Improving State-Tracking in Linear RNNs via Householder Products ICLR 2025 Workshop FM-Wild. Extending the DeltaNet [FWP6][LT23] through additional "micro-steps."
[S2Sa] M.L. Forcada and R.P. Ñeco. Recursive hetero-associative memories for translation. International Work-Conference on Artificial Neural Networks, 1997.
[S2Sb] T. Mikolov and G. Zweig, G. December. Context dependent recurrent neural network language model. IEEE Spoken Language Technology Workshop (SLT), 2012.
[S2Sc] A. Graves. Sequence transduction with recurrent neural networks. Representation Learning Workshop, Int. Conf. on Machine Learning (ICML), 2012
[S2Sd] I. Sutskever, O. Vinyals, Quoc V. Le. Sequence to sequence learning with neural networks. In: Advances in Neural Information Processing Systems (NIPS), 2014, 3104-3112.
[ST61] K. Steinbuch. Die Lernmatrix. Kybernetik, 1(1):36-45, 1961.
[TR1] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin (2017). Attention is all you need. NIPS 2017, pp. 5998-6008.
[TR2] J. Devlin, M. W. Chang, K. Lee, K. Toutanova (2018). Bert: Pre-training of deep bidirectional Transformers for language understanding. Preprint arXiv:1810.04805.
[TR3] K. Tran, A. Bisazza, C. Monz. The Importance of Being Recurrent for Modeling Hierarchical Structure. EMNLP 2018, p 4731-4736. ArXiv preprint 1803.03585.
[TR4] M. Hahn. Theoretical Limitations of Self-Attention in Neural Sequence Models. Transactions of the Association for Computational Linguistics, Volume 8, p.156-171, 2020.
[TR5] A. Katharopoulos, A. Vyas, N. Pappas, F. Fleuret. Transformers are RNNs: Fast autoregressive Transformers with linear attention. In Proc. Int. Conf. on Machine Learning (ICML), July 2020.
[TR5a] Z. Shen, M. Zhang, H. Zhao, S. Yi, H. Li. Efficient Attention: Attention with Linear Complexities. WACV 2021.
[TR6] K. Choromanski, V. Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P. Hawkins, J. Davis, A. Mohiuddin, L. Kaiser, et al. Rethinking attention with Performers. In Int. Conf. on Learning Representations (ICLR), 2021.
[TR6a] H. Peng, N. Pappas, D. Yogatama, R. Schwartz, N. A. Smith, L. Kong. Random Feature Attention. ICLR 2021.
[TR7] S. Bhattamishra, K. Ahuja, N. Goyal. On the Ability and Limitations of Transformers to Recognize Formal Languages. EMNLP 2020.
[ULTRA] References on the 1991 unnormalized linear Transformer (ULTRA): original tech report (March 1991) [FWP0]. Journal publication (1992) [FWP1]. Recurrent ULTRA extension (1993) introducing the terminology of learning "internal spotlights of attention” [FWP2]. Modern "quadratic" Transformer (2017: "attention is all you need") scaling quadratically in input size [TR1]. 2020 paper [TR5] using the terminology "linear Transformer" for a more efficient Transformer variant that scales linearly, leveraging linearized attention [TR5a]. 2021 paper [FWP6] pointing out that ULTRA dates back to 1991 [FWP0] when compute was a million times more expensive. Overview of ULTRA and other Fast Weight Programmers (2021) [FWP]. See the T in ChatGPT.
The Secret Behind New Age AI: Dreams
https://t.co/q57OIAZtOQ
September 29, 2025
The Electric Dream: How Brain-Inspired Self-Organization is Forging the Next Generation of AI






































![SchmidhuberAI's tweet photo. Who Invented Transformer Neural Networks (the T in ChatGPT)? Timeline of Transformer evolution https://t.co/7EJPAnRKvI
★ 1991. Original tech report on what's now called the unnormalized linear Transformer (ULTRA)[FWP0][ULTRA]. KEY/VALUE was called FROM/TO. ULTRA uses outer product rules to associate its self-invented KEYs/VALUEs through fast weights [FAST][FWP], and applies the resulting context-dependent attention mappings to incoming queries. ULTRA's computational costs scale linearly in input size, that is, for 1,000 times more text we need 1,000 times more compute, which is acceptable. Like modern quadratic Transformers (see below), the 1991 ULTRA is highly parallelizable. It was a by-product of more general research on neural networks (NNs) that learn to program fast weight changes of other NNs [FWP,FWP0-9,FWPMETA1-10], back then called fast weight controllers [FWP0] or fast weight programmers (FWPs) [FWP]. ULTRA was presented as an alternative to recurrent NNs [FWP0]. The 1991 experiments were similar to today's: predict some effect, given a sequence of inputs [FWP0].
★ 1992. Journal publication on ULTRA [FWP1], based on the 1991 tech report. Note that the terminology was different back then.
★ 1993. Recurrent ULTRA extension [FWP2] introducing the terminology of learning "internal spotlights of attention."
★ 2014. End-to-end sequence-to-sequence models [S2Sa,b,c,d] became popular for Natural Language Processing. They were not based on the 1991 unnormalized linear Transformer [ULTRA] above, but on the Long Short-Term Memory (LSTM) recurrent NN from the same lab. In 2014, this approach was combined with an attention mechanism [ATT14] that isn't linearized like the 1991-93 attention [FWP0-2] but includes a nonlinear softmax operation. The first Large Language Models (LLMs) were based on such LSTM-attention systems. See additional work on attention from 2016-17 [ATT16a-17b].
★ 2017. Modern quadratic Transformer ("attention is all you need"), scaling quadratically in input size [TR1], that is, for 1,000 times more text we need 1,000,000 times more compute. Note that in 1991 [ULTRA], no journal would have accepted an NN that scales quadratically, but by 2017, compute was cheap enough to apply the quadratic Transformer (a kind of fast weight programmer [FWP]) to large amounts of data on massively parallel computers. The quadratic Transformer combines the 1991 additive outer product fast weight principle [FWP0-2] and softmax (see 2014 above): attention (query, KEY, VALUE) ~ softmax (query KEY) VALUE.
★ 2020. New paper [TR5] using the terminology "linear Transformer" for a more efficient Transformer variant that scales linearly, leveraging linearized attention [TR5a].
★ 2021. Paper [FWP6] pointing out that the unnormalised linear Transformer [TR5-6] is actually MATHEMATICALLY EQUIVALENT to the 1991 fast weight controller [FWP0][ULTRA] published when compute was a million times more expensive than in 2021. Overview of ULTRA and FWPs (2021) [FWP].
★ 2021-25. Work on extensions of ULTRAs and other FWPs (such as the DeltaNet [FWP6]) has become mainstream research, aiming to develop sequence models that are both efficient and powerful [TR6,TR6a][LT23-25][FWP23-25b].
Of course, plain outer products in NNs go back at least to Konorski's informal 1948 rule [HEB48] (later sometimes called the "Hebb rule" [HEB49]) and concrete formal implementations through Steinbuch's Learning Matrix around 1960 [ST61-63][AMH1-2][KOH72][LIT74][PAL80]. See also bidirectional associative memories (1988) [KOS88]. However, these authors described pre-wired rules to associate user-given patterns with each other. Unlike ULTRA and other Transformers since 1991 [ULTRA][TR1], their NNs did not learn to use such rules for associating self-invented KEY/VALUE patterns, by backpropagating errors [BP4] THROUGH the rules, to generate appropriate KEYs/VALUEs at the right times and create useful changes of fast weights. (Neither did early NNs with fast weights by Malsburg (1981) and others [FAST][FASTa,b][DLP].)
**********
SELECTED REFERENCES (remaining references in: Who Invented Transformer Neural Networks? Technical Note IDSIA-11-25, Nov 2025 - see link above)
[ATT] Juergen's AI Blog (2020, updated 2025): 30-year anniversary of end-to-end differentiable sequential neural attention. Plus goal-conditional reinforcement learning. There was both hard attention for foveas (1990) and soft attention in form of Transformers with linearized self-attention (1991-93) [ULTRA]. Today, both types are very popular.
[ATT14] D. Bahdanau, K. Cho, Y. Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. 2014-16. Preprint arXiv/1409.0473, 2014-16.
[FAST] C. v.d. Malsburg. Tech Report 81-2, Abteilung f. Neurobiologie, Max-Planck Institut f. Biophysik und Chemie, Goettingen, 1981. First paper on fast weights or dynamic links.
[FWP] 26 March 1991: Neural nets learn to program neural nets with fast weights—like Transformer variants. 2021: New stuff! AI Blog, 26 March 2021, updated 2025.
[FWP0] J. Schmidhuber. Learning to control fast-weight memories: An alternative to recurrent nets. Technical Report FKI-147-91, TU Munich, 26 March 1991. First paper on neural fast weight programmers (FWPs) that separate storage and control: a slow net learns by gradient descent to compute weight changes of a fast net. The outer product-based version (Eq. 5) is now known as the unnormalized linear Transformer or the "Transformer with linearized self-attention" [ULTRA][FWP].
[FWP1] J. Schmidhuber. Learning to control fast-weight memories: An alternative to recurrent nets. Neural Computation, 4(1):131-139, 1992. Based on [FWP0].
[FWP2] J. Schmidhuber. Reducing the ratio between learning complexity and number of time-varying variables in fully recurrent nets. In Proceedings of the International Conference on Artificial Neural Networks, Amsterdam, pages 460-463. Springer, 1993. A recurrent extension of the 1991 unnormalized linear Transformer [ULTRA], introducing the terminology of learning "internal spotlights of attention." First recurrent NN-based fast weight programmer using outer products to program weight matrix changes.
[FWP6] I. Schlag, K. Irie, J. Schmidhuber. Linear Transformers Are Secretly Fast Weight Programmers. ICML 2021. Preprint: arXiv:2102.11174. Shows that the unnormalised linear Transformer is actually MATHEMATICALLY EQUIVALENT to the 1991 system [FWP0][ULTRA] published when compute was a million times more expensive than in 2021.
[FWP7] K. Irie, I. Schlag, R. Csordas, J. Schmidhuber. Going Beyond Linear Transformers with Recurrent Fast Weight Programmers. NeurIPS 2021. Preprint: arXiv:2106.06295
[HEB48] J. Konorski (1948). Conditioned reflexes and neuron organization. Translation from the Polish manuscript under the author's supervision. Cambridge University Press, 1948. Konorski published the so-called "Hebb rule" before Hebb [HEB49].
[HEB49] D. O. Hebb. The Organization of Behavior. Wiley, New York, 1949. Konorski [HEB48] published the so-called "Hebb rule" before Hebb.
[KOS88] B. Kosko. Bidirectional associative memories. IEEE Transactions on Systems, Man, and Cybernetics, 18(1):49-60, 1988.
[LT20] A. Katharopoulos, A. Vyas, N. Pappas, F. Fleuret. Transformers are RNNs: Fast autoregressive Transformers with linear attention. In Proc. Int. Conf. on Machine Learning (ICML), July 2020.
[LT21] I. Bello. LambdaNetworks: Modeling Long-Range Interactions Without Attention. Preprint arXiv:2102.08602. A linear transformer variant.
[LT23] K. Irie, R. Csordas, J. Schmidhuber. Practical Computational Power of Linear Transformers and Their Recurrent and Self-Referential Extensions. EMNLP 2023.
[LT24] S. Yang, B. Wang, Y. Zhang, Y. Shen, Y. Kim. Parallelizing Linear Transformers with the Delta Rule over Sequence Length. NeurIPS 2024.
[LT25] S. Yang, J. Kautz, A. Hatamizadeh. Gated Delta Networks: Improving Mamba2 with Delta Rule. ICLR 2025. "Mamba2" is essentially the 1991 ULTRA with a scalar time-decay factor on the fast weight matrix.
[LT25b] R. Grazzi, J. Siems, A. Zela, J. K.H. Franke, F. Hutter, M. Pontil. Unlocking State-Tracking in Linear RNNs Through Negative Eigenvalues. ICLR 2025. Shows that the delta-rule extension [FWP6][LT23] is more expressive than the quadratic Transformer and other naive linear Transformers (e.g., it can do parity and modular arithmetics).
[LT25c] J. Siems, T. Carstensen, A. Zela, F. Hutter, M. Pontil, R. Grazzi. DeltaProduct: Improving State-Tracking in Linear RNNs via Householder Products ICLR 2025 Workshop FM-Wild. Extending the DeltaNet [FWP6][LT23] through additional "micro-steps."
[S2Sa] M.L. Forcada and R.P. Ñeco. Recursive hetero-associative memories for translation. International Work-Conference on Artificial Neural Networks, 1997.
[S2Sb] T. Mikolov and G. Zweig, G. December. Context dependent recurrent neural network language model. IEEE Spoken Language Technology Workshop (SLT), 2012.
[S2Sc] A. Graves. Sequence transduction with recurrent neural networks. Representation Learning Workshop, Int. Conf. on Machine Learning (ICML), 2012
[S2Sd] I. Sutskever, O. Vinyals, Quoc V. Le. Sequence to sequence learning with neural networks. In: Advances in Neural Information Processing Systems (NIPS), 2014, 3104-3112.
[ST61] K. Steinbuch. Die Lernmatrix. Kybernetik, 1(1):36-45, 1961.
[TR1] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin (2017). Attention is all you need. NIPS 2017, pp. 5998-6008.
[TR2] J. Devlin, M. W. Chang, K. Lee, K. Toutanova (2018). Bert: Pre-training of deep bidirectional Transformers for language understanding. Preprint arXiv:1810.04805.
[TR3] K. Tran, A. Bisazza, C. Monz. The Importance of Being Recurrent for Modeling Hierarchical Structure. EMNLP 2018, p 4731-4736. ArXiv preprint 1803.03585.
[TR4] M. Hahn. Theoretical Limitations of Self-Attention in Neural Sequence Models. Transactions of the Association for Computational Linguistics, Volume 8, p.156-171, 2020.
[TR5] A. Katharopoulos, A. Vyas, N. Pappas, F. Fleuret. Transformers are RNNs: Fast autoregressive Transformers with linear attention. In Proc. Int. Conf. on Machine Learning (ICML), July 2020.
[TR5a] Z. Shen, M. Zhang, H. Zhao, S. Yi, H. Li. Efficient Attention: Attention with Linear Complexities. WACV 2021.
[TR6] K. Choromanski, V. Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P. Hawkins, J. Davis, A. Mohiuddin, L. Kaiser, et al. Rethinking attention with Performers. In Int. Conf. on Learning Representations (ICLR), 2021.
[TR6a] H. Peng, N. Pappas, D. Yogatama, R. Schwartz, N. A. Smith, L. Kong. Random Feature Attention. ICLR 2021.
[TR7] S. Bhattamishra, K. Ahuja, N. Goyal. On the Ability and Limitations of Transformers to Recognize Formal Languages. EMNLP 2020.
[ULTRA] References on the 1991 unnormalized linear Transformer (ULTRA): original tech report (March 1991) [FWP0]. Journal publication (1992) [FWP1]. Recurrent ULTRA extension (1993) introducing the terminology of learning "internal spotlights of attention” [FWP2]. Modern "quadratic" Transformer (2017: "attention is all you need") scaling quadratically in input size [TR1]. 2020 paper [TR5] using the terminology "linear Transformer" for a more efficient Transformer variant that scales linearly, leveraging linearized attention [TR5a]. 2021 paper [FWP6] pointing out that ULTRA dates back to 1991 [FWP0] when compute was a million times more expensive. Overview of ULTRA and other Fast Weight Programmers (2021) [FWP]. See the T in ChatGPT.](https://pbs.twimg.com/media/G5UxgukWEAEKp2B.jpg)




















