Thrilled to announce the Wearable AI Workshop at ECCV 2026 🎉 If you work on Proactive AI, Multimodal Assistants, or Long-form Streaming Video understanding, definitely consider participating.
🔗 Call for Papers: https://t.co/M56RBboLHw
🔗 Granc Challenge: Dataset & Toolkit on HF https://t.co/pOqN4EjPCp
What's at stake:
- Access to a rich, multi-modal egocentric dataset for research
- A venue to present your work at ECCV 2026
- $21K in challenge prizes across three tracks
Tag a colleague or student who'd be interested 👇
📅 Wearable AI Workshop - ECCV 2026 · 📍 Malmö, Sweden
We're organizing a visual Q&A benchmark challenge at KDD, focusing on the Multimodal RAG task. Join the CRAG-MM Challenge! More details here:
https://t.co/vS2Jp9gRLb
We're hiring exceptional AI Research Scientists to join our team at Meta Reality Labs, where you'll work on cutting-edge projects in Vision LLMs.
Please reach out to me directly via email with your resume! (Check minimum qualifications)
https://t.co/n6e6qQfUcp
We are hiring PhD AI Research Interns to work on various projects around Multimodal LLM for Summer 2024 (Reality Labs). Please reach out to me directly via email with your resume!
@KuterDinel Hi @KuterDinel, great point, I do agree it'll be more robust that way, but it'll be computationally much more costly to pre-train it e2e from scratch, and re-do instruction tuning & RLHF for the LLM (hence "scalable and efficient" in our title).
Excited to share our recent work, AnyMAL -- a unified Multimodal LLM built on LLaMA-2 that can reason over various inputs, e.g. images, audio, motion sensors.
Check out our paper for more information on the model training, evaluation, safety and more!
➡️ https://t.co/HmyVynWXPH
Meta introduces AnyMAL
- a unified model that reasons over diverse input modality signals (i.e. text, image, video, audio, IMU motion sensor), and generates textual responses
- best model achieves strong zero-shot performance in both automatic and human evaluation on diverse tasks and modalities, setting new SOTA with +7.0% relative accuracy improvement on VQAv2, +8.4% CIDEr on zeroshot COCO image captioning, and +14.5% CIDEr on AudioCaps, when compared with the models available in the literature.
Meta Reality Lab is organizing "Ambient AI Workshop" -- focusing on multimodal understanding with wearable sensors, combining NLP + Vision + Sensor Signals.
For more details & call for paper (now due Mar 26):
https://t.co/yxINJn0r7n
We look forward to your participation!
We are hiring PhD Research Interns to work on various Multimodal & NLP related projects (Reality Labs) for 2023. See JDs here -- apply directly or reach out to me directly via email!
- https://t.co/8P649TIftC
- https://t.co/CCVvLy47yz
We are hiring research interns to work on various multimodal & NLP related projects (Reality Labs). See JDs here -- or reach out to me directly via email!
https://t.co/Le9D2c2cNh
https://t.co/gYUqR49QmH
4 papers accepted at #EMNLP2021🎉 #NLProc
- ToD Dataset for Immersive Multimodal Conversation; @SatwikKottur et al
- Continual Learning in ToD System; @AndreaMadotto et al
- Zero-Shot DST via CrossTask Transfer; @zlinao_lin et al
- Annotation for Nuanced Conversation; Chen et al
(3/3) ACCENTOR datasets:
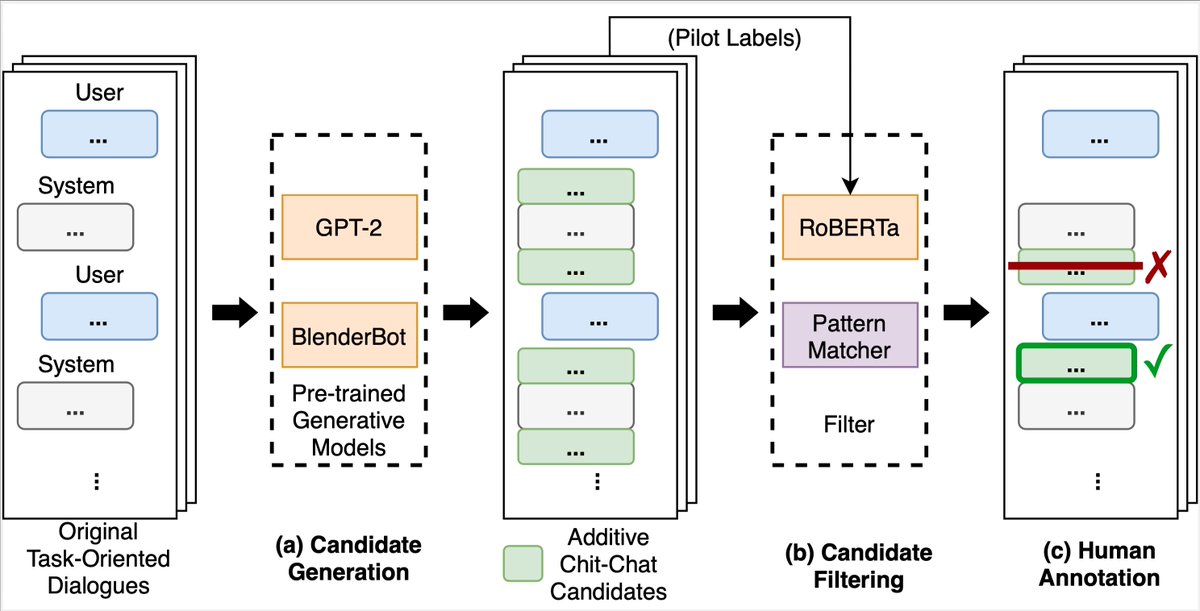
We propose a Human ↔ AI collaborative data collection approach for generating diverse chitchat responses to augment ToD dialogs with minimal annotation effort. Results: chit-chat additions to 23K+ dialogs from two popular ToD datasets (SGD & MultiWoZ2.1)
Introducing our work at #NAACL2021 w/ Sun et al. -- bridging the gap between task-oriented dialog systems and open-domain dialog systems (chit-chat) #NLPRoc#ConvAI
📰Paper, 📂Dataset, 💻Code (for a suite of chit-chat & task code-switching models): https://t.co/almWVHDp8M (1/3)
We are releasing ACCENTOR, a new data set that combines contextual chit-chat and traditional task-oriented dialogs. Automatic & human evaluations show our models can code-switch seamlessly, making virtual assistant conversations more natural & interactive. https://t.co/HjOzZkpLfC
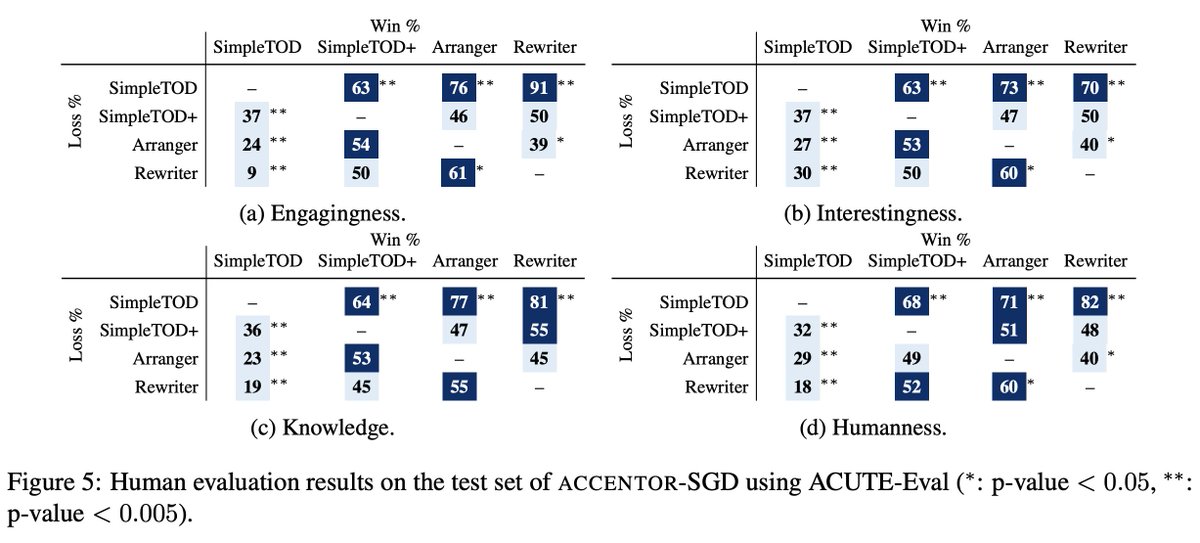
(2/3) Results?
- (Interaction eval) People like them! Our models are consistently preferred by human judges across the four axes (engagingness, etc.), compared to the baseline assistant models.
- (Task eval) Our models still maintain competitive task performances.
Two papers from our group were accepted at #NAACL2021 🎉
* Adding chit-chat to enhance task-oriented dialogues: https://t.co/almWVHDp8M w/ Kai Sun
* A new SOTA for zeroshot cross-domain DST: manuscript📑 to be released soon! @zlinao_lin
Kudos to our amazing interns! 😀
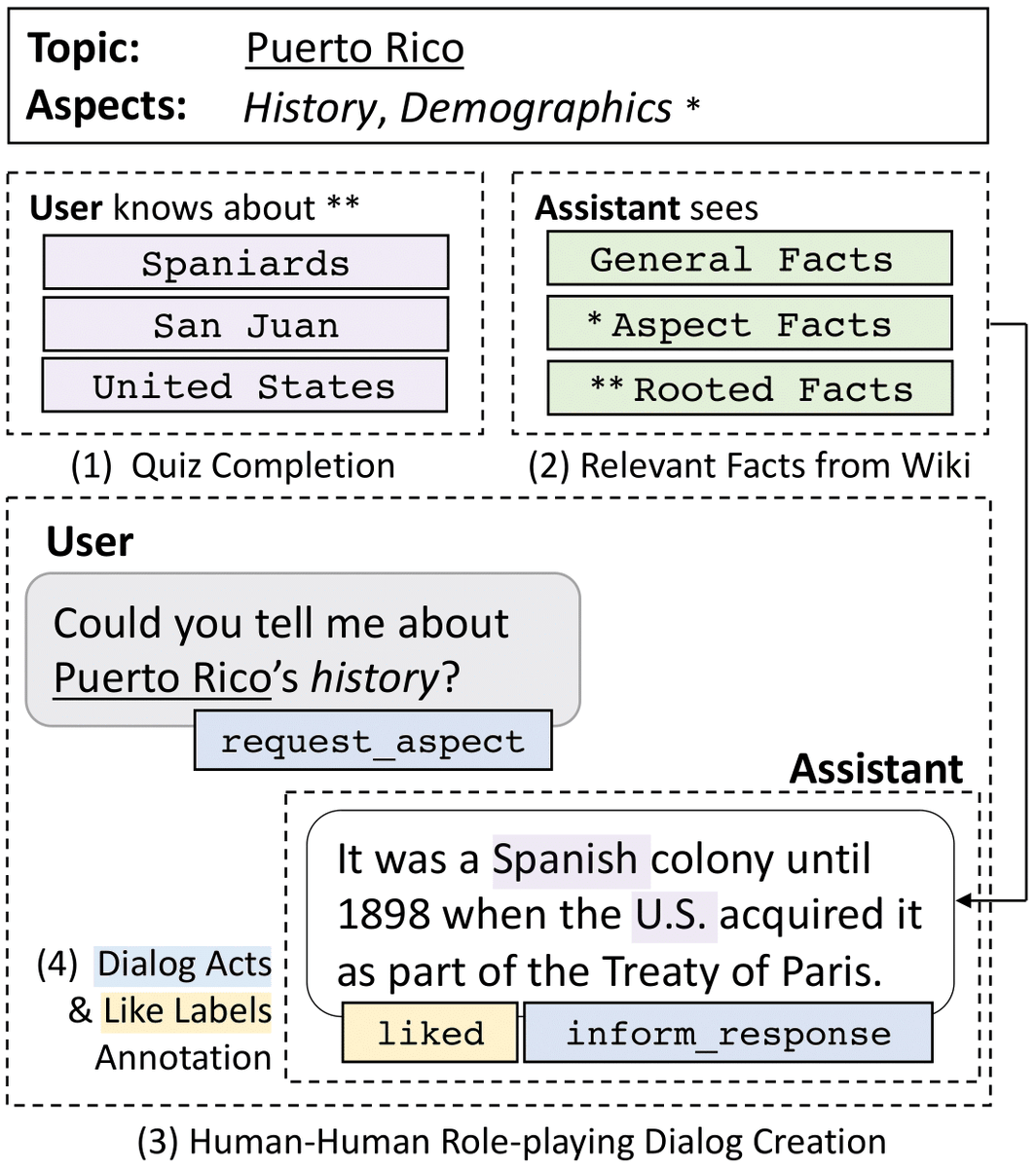
Hey <wake-word>, tell me about Punta Cana🇩🇴. Our #emnlp2020 paper introduces a conversational information-seeking dataset on geographic entities.
📜Paper + 📁Dataset + 💻Code: https://t.co/Zh7ebt3mqq
Gather 5H: Nov 18 18UTC
w/Paul Crook, @shane_moon, Stephen Wang 1/4
We are running a challenge track at DSTC9 around multimodal conversational AI! To participate:
- paper: https://t.co/CzmbbfHuSF
- code & challenge website: https://t.co/5V6QY4AYqM
We’ve released SIMMC, a data set on situated and interactive multimodal conversations, to help conversational AI researchers ground conversations in a co-observed and evolving multimodal context.
A challenge track at DSTC9 around SIMMC is currently live.
https://t.co/09QKGQ6pXF
We’ve released SIMMC, a data set on situated and interactive multimodal conversations, to help conversational AI researchers ground conversations in a co-observed and evolving multimodal context.
A challenge track at DSTC9 around SIMMC is currently live.
https://t.co/09QKGQ6pXF