Why guess with your rankings? 🤔
With ShapedQL, you can explicitly weight Keyword vs. Semantic search using simple SQL.
10% BM25 + 90% Vector? Done in one line. ⚡️
Watch the demo 👇
It's not just for ranking models. Signals power search relevance, agent context enrichment, faceted filtering, and any workload that needs fresh features at query time.
Docs: https://t.co/7QcJYbBvGh
We just shipped the Signal Engine.
Define a feature once. Get training, serving, and streaming for free.
25+ signal primitives
<5ms serving
Point-in-Time correctness by default
Change a feature, see evaluation results in hours
Blog post: https://t.co/aftLcSMY7I
Signal primitives ship today: aggregations, ratios, cross features, vector similarity, geo distance, text similarity, cyclic time encoding, sequences for SASRec/BERT4Rec, and more.
$100 free credits. No credit card.
→ https://t.co/Wjntw33tHf
If you're building agents and retrieval quality is killing you, try it. We'd love your feedback.
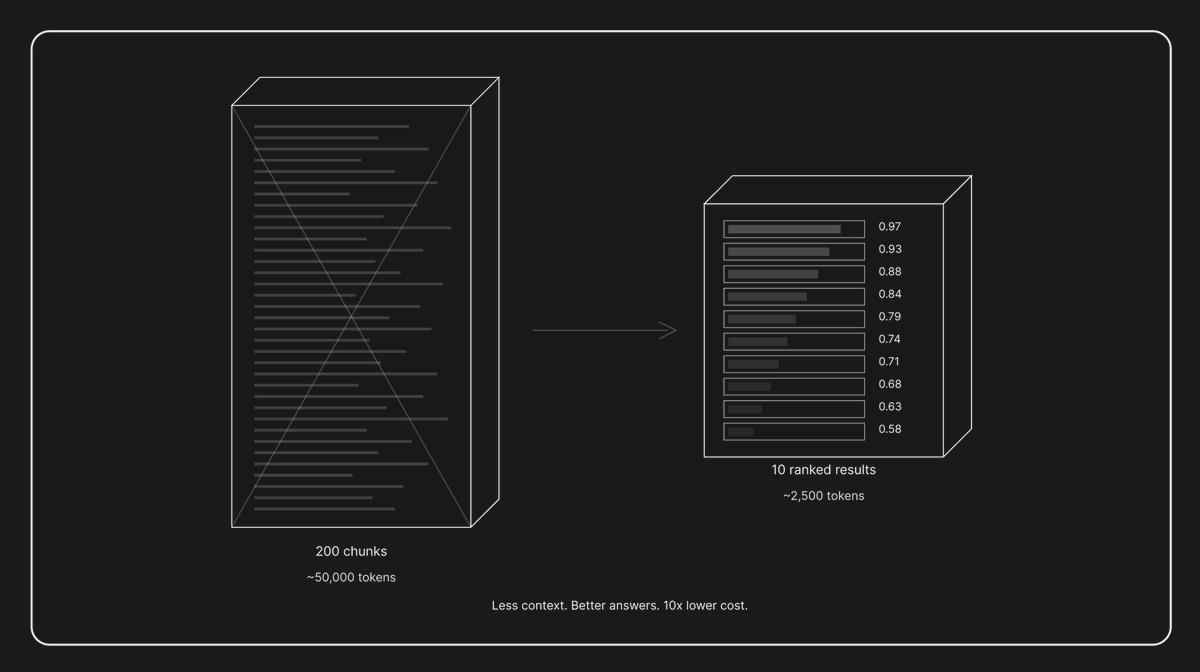
Your AI agent spends 50,000 tokens per query.
90% of that is noise.
When the answer is wrong, it re-retrieves — another 50K tokens, another ~$0.50 in LLM token costs, another few seconds of latency.
The problem isn't the LLM. It's the retrieval.
We built Shaped to fix it. 🧵
We just shipped an MCP server.
pip install shaped-mcp
Works natively with Cursor, Claude Code, Windsurf, VS Code Copilot, Gemini, OpenAI — any MCP-compatible agent.
Add it to your config. Your agent has better retrieval instantly. No custom integration code.
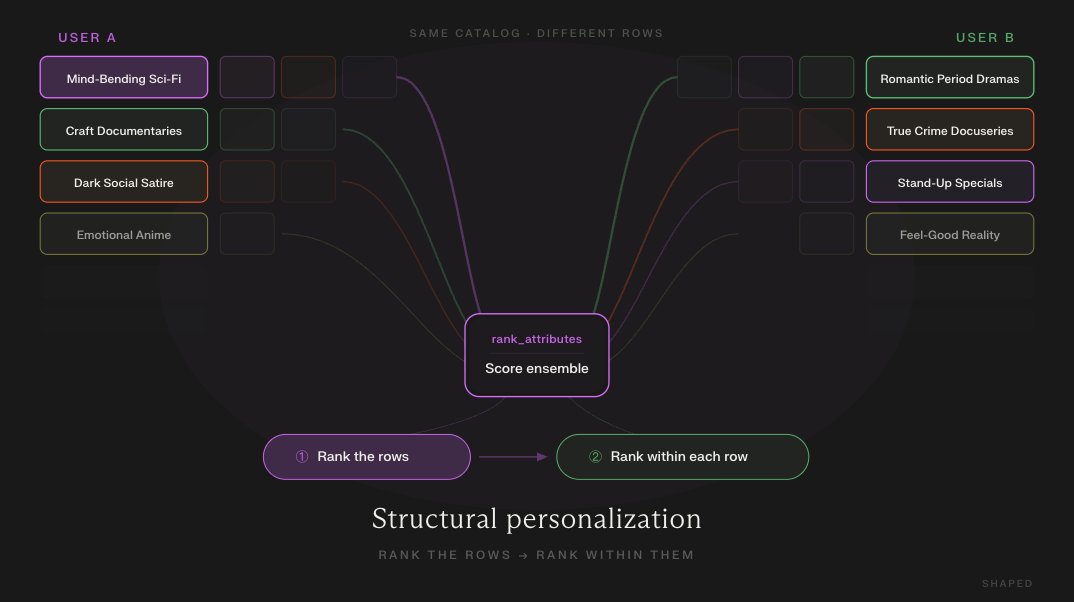
Netflix doesn't just personalize which movies you see. It personalizes which ROWS you see.
We wrote the playbook on how to build it.
https://t.co/Imtw5MqL10
"the new model feels better"
that's not a metric
offline eval:
Recall@10: 0.45 → 0.50 (+11%)
NDCG@10: 0.54 → 0.61 (+13%)
online A/B test:
CTR: +15%
Conversion: +19%
now you have proof
https://t.co/9XhRnTYEtl
your agent's config:
• ranking formula in .env
• filters hardcoded
• vector DB settings in UI
• features scattered
when it breaks: 🤷
with GitOps:
• everything in Git
• PR review before deploy
• one command to rollback
• clear audit trail
https://t.co/PC9qKw3pVz
your agent: 5 seconds to respond
your LLM: 3 seconds
where are the other 2 seconds?
retrieval.
vector DB: 220ms
filtering: 50ms
scoring: 120ms
reordering: 60ms
network hops: 4x
= 450ms+ per query
Shaped's fast_tier: 30-100ms for all 4 stages unified
https://t.co/euREfIEbFz
The scaling law for agents isn't model size. It's what goes into the context window.
Attention is quadratic. 2x tokens = 4x cost.
10 ranked results > 200 stuffed chunks. Every time. At 10x lower cost.
We wrote the math:
https://t.co/LH8X7AzRRm
your agent: "order has shipping tier 4 and status 7"
what the customer needed: "ships in 2 days via FedEx, in transit"
AI Views fix this—enrich at write time, not read time
https://t.co/CtALPq0pJF
most "AI hallucinations" are just stale retrieval
user: "is this in stock?"
agent's index: last updated 2am
product: sold out at 9am
agent: "yes"
the model is fine. your data pipeline is broken.
how to fix it 👇
https://t.co/bLN2NDjyGi
We built a complete technical guide:
✓ Working code
✓ Architecture diagrams
✓ Dynamic weight tuning patterns
✓ Real-world use cases (e-commerce, travel, content) ✓ When NOT to use this approach
Read it here: https://t.co/f6lFHCDHpc
Your agent just cost you $40,000.
It recommended wireless headphones to a customer who bought the exact same pair yesterday.
The problem? It optimized for semantic similarity. It ignored business logic.
Here's how to fix it 🧵