@shreyasnsharma Totally agree. Individual tokens as an action space is a “drawback” of RL in LMs. Today’s process of constructing DSLs and priors tho reminds me a lot of early feature engineering days… curious to know if there are general or DL-pilled methods of LM action space construction.
Putting out a wish to the universe.
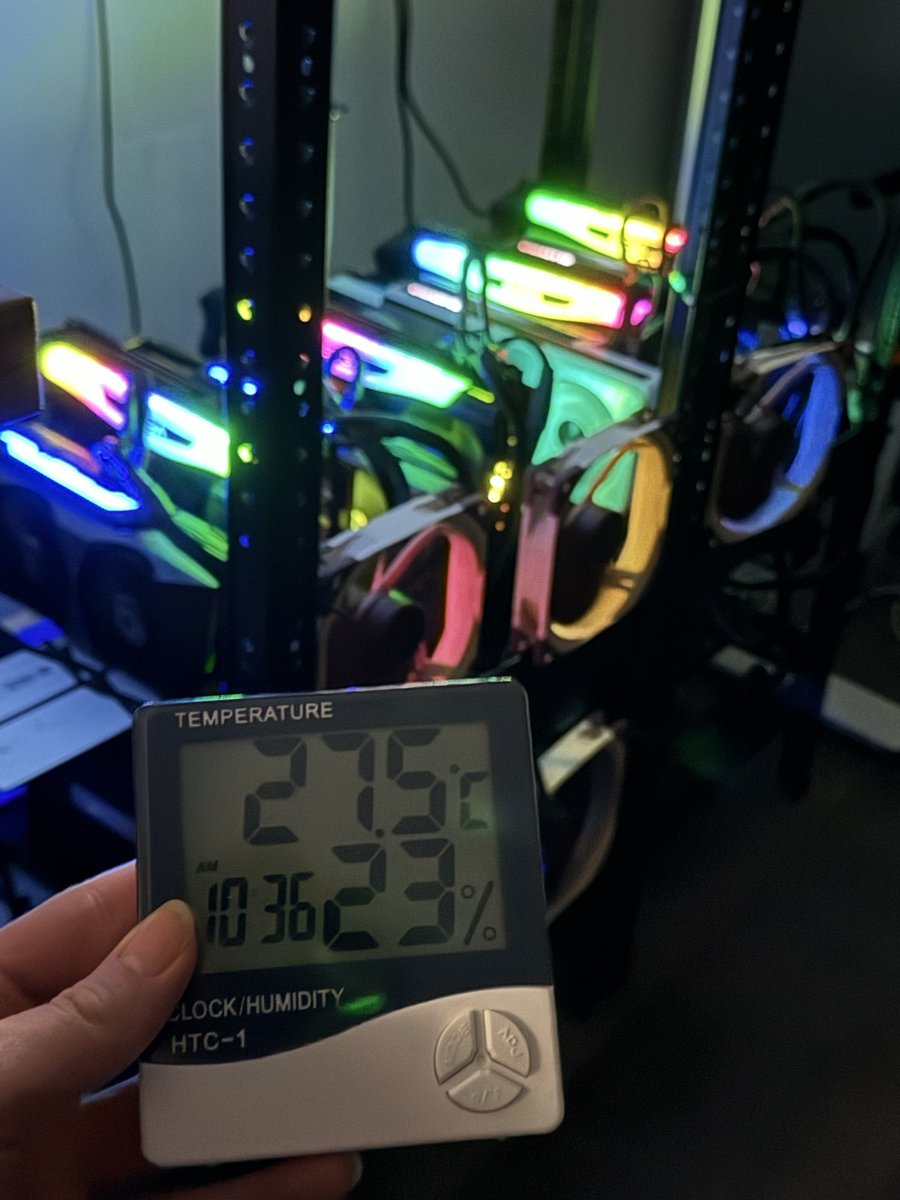
I need more compute, if I can get more I will make sure every machine from a small phone to a bootstrapped RTX 3090 node can run frontier intelligence fast with minimal intelligence loss.
I have hit page 2 of huggingface, released 3 model family compressions and got GLM-4.7 on a MacBook https://t.co/lorDSUEYCL
My beast just isn’t enough and I already spent 2k usd on renting GPUs on top of credits provided by Prime intellect and Hotaisle.
———
If you believe in what I do help me get this to Nvidia, maybe they will bless me with the pewter to keep making local AI more accessible 🙏
(1/n) Evolutionary frameworks like AlphaEvolve and GEPA use diversity and fitness to select which subset of past experiments to condition the next generation on. Why not let an agent choose instead? To this end, we introduce Coding Agents as Text Optimizers (CATO). We beat AlphaEvolve on 2 out of the 3 problems we try.
Work done with @shaurnav. Blogpost and details in thread.
As a founder, you can get a lot of things wrong. But if you're unwiling to die, it will eventually work out.
Be optimistic, and try to be right. But even if you're not right, don't die.